 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair MP-BOOST: Fair and Interpretable Minipatch Boosting
Apr 01, 2024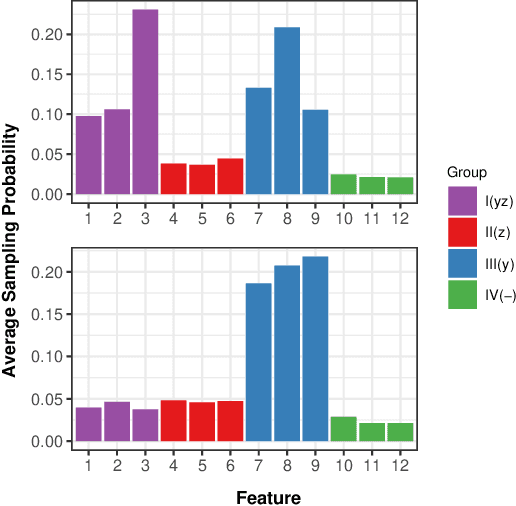
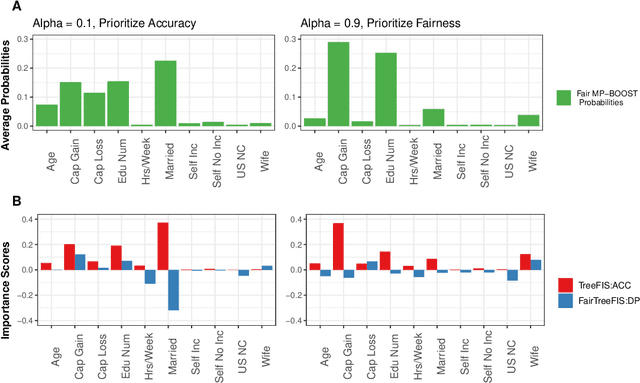
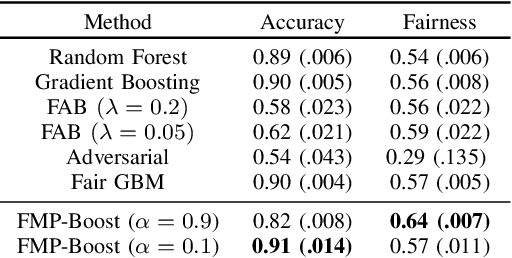
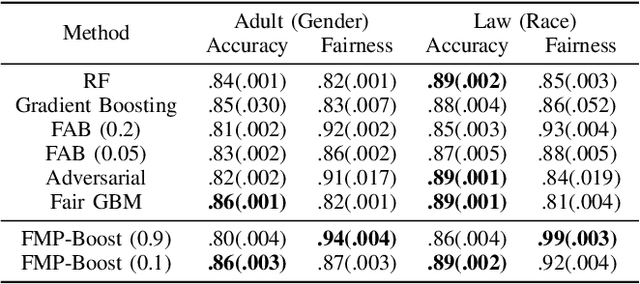
Ensemble methods, particularly boosting, have established themselves as highly effective and widely embraced machine learning techniques for tabular data. In this paper, we aim to leverage the robust predictive power of traditional boosting methods while enhancing fairness and interpretability. To achieve this, we develop Fair MP-Boost, a stochastic boosting scheme that balances fairness and accuracy by adaptively learning features and observations during training. Specifically, Fair MP-Boost sequentially samples small subsets of observations and features, termed minipatches (MP), according to adaptively learned feature and observation sampling probabilities. We devise these probabilities by combining loss functions, or by combining feature importance scores to address accuracy and fairness simultaneously. Hence, Fair MP-Boost prioritizes important and fair features along with challenging instances, to select the most relevant minipatches for learning. The learned probability distributions also yield intrinsic interpretations of feature importance and important observations in Fair MP-Boost. Through empirical evaluation of simulated and benchmark datasets, we showcase the interpretability, accuracy, and fairness of Fair MP-Boost.
Fair Feature Importance Scores for Interpreting Tree-Based Methods and Surrogates
Oct 06, 2023Across various sectors such as healthcare, criminal justice, national security, finance, and technology, large-scale machine learning (ML) and artificial intelligence (AI) systems are being deployed to make critical data-driven decisions. Many have asked if we can and should trust these ML systems to be making these decisions. Two critical components are prerequisites for trust in ML systems: interpretability, or the ability to understand why the ML system makes the decisions it does, and fairness, which ensures that ML systems do not exhibit bias against certain individuals or groups. Both interpretability and fairness are important and have separately received abundant attention in the ML literature, but so far, there have been very few methods developed to directly interpret models with regard to their fairness. In this paper, we focus on arguably the most popular type of ML interpretation: feature importance scores. Inspired by the use of decision trees in knowledge distillation, we propose to leverage trees as interpretable surrogates for complex black-box ML models. Specifically, we develop a novel fair feature importance score for trees that can be used to interpret how each feature contributes to fairness or bias in trees, tree-based ensembles, or tree-based surrogates of any complex ML system. Like the popular mean decrease in impurity for trees, our Fair Feature Importance Score is defined based on the mean decrease (or increase) in group bias. Through simulations as well as real examples on benchmark fairness datasets, we demonstrate that our Fair Feature Importance Score offers valid interpretations for both tree-based ensembles and tree-based surrogates of other ML systems.
To the Fairness Frontier and Beyond: Identifying, Quantifying, and Optimizing the Fairness-Accuracy Pareto Frontier
May 31, 2022

Algorithmic fairness has emerged as an important consideration when using machine learning to make high-stakes societal decisions. Yet, improved fairness often comes at the expense of model accuracy. While aspects of the fairness-accuracy tradeoff have been studied, most work reports the fairness and accuracy of various models separately; this makes model comparisons nearly impossible without a model-agnostic metric that reflects the balance of the two desiderata. We seek to identify, quantify, and optimize the empirical Pareto frontier of the fairness-accuracy tradeoff. Specifically, we identify and outline the empirical Pareto frontier through Tradeoff-between-Fairness-and-Accuracy (TAF) Curves; we then develop a metric to quantify this Pareto frontier through the weighted area under the TAF Curve which we term the Fairness-Area-Under-the-Curve (FAUC). TAF Curves provide the first empirical, model-agnostic characterization of the Pareto frontier, while FAUC provides the first metric to impartially compare model families on both fairness and accuracy. Both TAF Curves and FAUC can be employed with all group fairness definitions and accuracy measures. Next, we ask: Is it possible to expand the empirical Pareto frontier and thus improve the FAUC for a given collection of fitted models? We answer affirmately by developing a novel fair model stacking framework, FairStacks, that solves a convex program to maximize the accuracy of model ensemble subject to a score-bias constraint. We show that optimizing with FairStacks always expands the empirical Pareto frontier and improves the FAUC; we additionally study other theoretical properties of our proposed approach. Finally, we empirically validate TAF, FAUC, and FairStacks through studies on several real benchmark data sets, showing that FairStacks leads to major improvements in FAUC that outperform existing algorithmic fairness approaches.