 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Forest and Trees in Images and Long Captions for Visually Grounded Understanding
Feb 03, 2026Large vision-language models such as CLIP struggle with long captions because they align images and texts as undifferentiated wholes. Fine-grained vision-language understanding requires hierarchical semantics capturing both global context and localized details across visual and textual domains. Yet linguistic hierarchies from syntax or semantics rarely match visual organization, and purely visual hierarchies tend to fragment scenes into appearance-driven parts without semantic focus. We propose CAFT (Cross-domain Alignment of Forests and Trees), a hierarchical image-text representation learning framework that aligns global and local semantics across images and long captions without pixel-level supervision. Coupling a fine-to-coarse visual encoder with a hierarchical text transformer, it uses a hierarchical alignment loss that matches whole images with whole captions while biasing region-sentence correspondences, so that coarse semantics are built from fine-grained evidence rather than from aggregation untethered to part-level grounding. Trained on 30M image-text pairs, CAFT achieves state-of-the-art performance on six long-text retrieval benchmarks and exhibits strong scaling behavior. Experiments show that hierarchical cross-domain alignment enables fine-grained, visually grounded image-text representations to emerge without explicit region-level supervision.
Tortoise and Hare Guidance: Accelerating Diffusion Model Inference with Multirate Integration
Nov 06, 2025In this paper, we propose Tortoise and Hare Guidance (THG), a training-free strategy that accelerates diffusion sampling while maintaining high-fidelity generation. We demonstrate that the noise estimate and the additional guidance term exhibit markedly different sensitivity to numerical error by reformulating the classifier-free guidance (CFG) ODE as a multirate system of ODEs. Our error-bound analysis shows that the additional guidance branch is more robust to approximation, revealing substantial redundancy that conventional solvers fail to exploit. Building on this insight, THG significantly reduces the computation of the additional guidance: the noise estimate is integrated with the tortoise equation on the original, fine-grained timestep grid, while the additional guidance is integrated with the hare equation only on a coarse grid. We also introduce (i) an error-bound-aware timestep sampler that adaptively selects step sizes and (ii) a guidance-scale scheduler that stabilizes large extrapolation spans. THG reduces the number of function evaluations (NFE) by up to 30% with virtually no loss in generation fidelity ($Δ$ImageReward $\leq$ 0.032) and outperforms state-of-the-art CFG-based training-free accelerators under identical computation budgets. Our findings highlight the potential of multirate formulations for diffusion solvers, paving the way for real-time high-quality image synthesis without any model retraining. The source code is available at https://github.com/yhlee-add/THG.
Textual Query-Driven Mask Transformer for Domain Generalized Segmentation
Jul 12, 2024
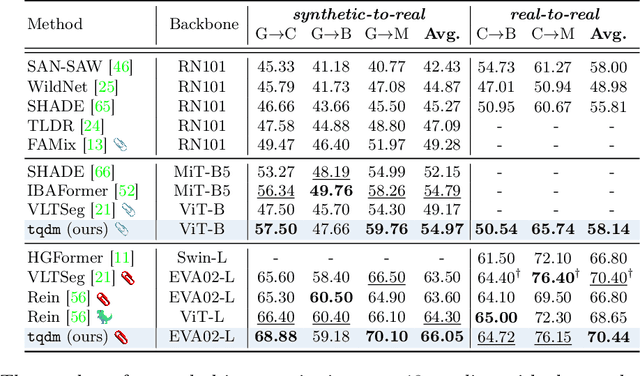
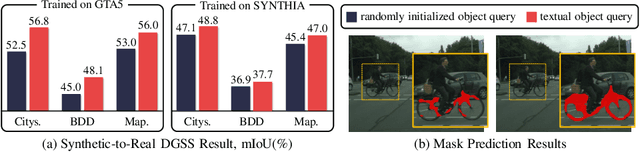
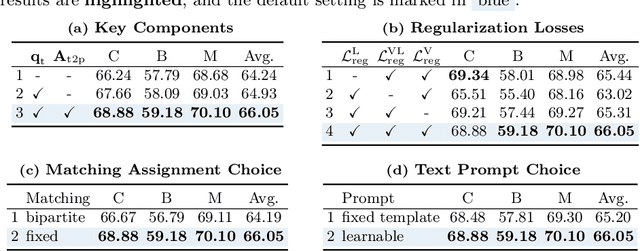
In this paper, we introduce a method to tackle Domain Generalized Semantic Segmentation (DGSS) by utilizing domain-invariant semantic knowledge from text embeddings of vision-language models. We employ the text embeddings as object queries within a transformer-based segmentation framework (textual object queries). These queries are regarded as a domain-invariant basis for pixel grouping in DGSS. To leverage the power of textual object queries, we introduce a novel framework named the textual query-driven mask transformer (tqdm). Our tqdm aims to (1) generate textual object queries that maximally encode domain-invariant semantics and (2) enhance the semantic clarity of dense visual features. Additionally, we suggest three regularization losses to improve the efficacy of tqdm by aligning between visual and textual features. By utilizing our method, the model can comprehend inherent semantic information for classes of interest, enabling it to generalize to extreme domains (e.g., sketch style). Our tqdm achieves 68.9 mIoU on GTA5$\rightarrow$Cityscapes, outperforming the prior state-of-the-art method by 2.5 mIoU. The project page is available at https://byeonghyunpak.github.io/tqdm.