 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling semantic association in self-paced reading with language model embeddings
Jun 05, 2026Semantic association between a word and its context has been identified as an important component of reading comprehension, even when word predictability is accounted for. Recent research has highlighted the potential of language model ( LM) embeddings to quantify semantic association. Yet, embedding-based semantic association have been operationalized in a myriad of ways. In this study, we use embeddings from LMs to estimate semantic association on a corpus of joint electroencephalography (EEG) and self-paced reading of natural, Dutch texts. Semantic association is calculated in ten different implementations that vary the embedding model and context lengths. The effects of semantic association across the different implementations on the N400 and self-paced reading times are examined using Bayesian hierarchical models and Bayes factor. The results show that the choice of embedding model can alter the estimated effect of semantic association on both the N400 and self-paced reading times. Furthermore, the results demonstrate a promising potential of sentence embeddings for capturing semantic association, as only implementations relying on sentence embeddings indicate reliable results of semantic association beyond word predictability on both neural and behavioral measures. Together, these findings highlight the importance of methodological choices in quantifying semantic association.
Feature overwriting as a finite mixture process: Evidence from comprehension data
Jan 20, 2018


The ungrammatical sentence "The key to the cabinets are on the table" is known to lead to an illusion of grammaticality. As discussed in the meta-analysis by Jaeger et al., 2017, faster reading times are observed at the verb are in the agreement-attraction sentence above compared to the equally ungrammatical sentence "The key to the cabinet are on the table". One explanation for this facilitation effect is the feature percolation account: the plural feature on cabinets percolates up to the head noun key, leading to the illusion. An alternative account is in terms of cue-based retrieval (Lewis & Vasishth, 2005), which assumes that the non-subject noun cabinets is misretrieved due to a partial feature-match when a dependency completion process at the auxiliary initiates a memory access for a subject with plural marking. We present evidence for yet another explanation for the observed facilitation. Because the second sentence has two nouns with identical number, it is possible that these are, in some proportion of trials, more difficult to keep distinct, leading to slower reading times at the verb in the first sentence above; this is the feature overwriting account of Nairne, 1990. We show that the feature overwriting proposal can be implemented as a finite mixture process. We reanalysed ten published data-sets, fitting hierarchical Bayesian mixture models to these data assuming a two-mixture distribution. We show that in nine out of the ten studies, a mixture distribution corresponding to feature overwriting furnishes a superior fit over both the feature percolation and the cue-based retrieval accounts.
Models of retrieval in sentence comprehension: A computational evaluation using Bayesian hierarchical modeling
Aug 24, 2017



Research on interference has provided evidence that the formation of dependencies between non-adjacent words relies on a cue-based retrieval mechanism. Two different models can account for one of the main predictions of interference, i.e., a slowdown at a retrieval site, when several items share a feature associated with a retrieval cue: Lewis and Vasishth's (2005) activation-based model and McElree's (2000) direct access model. Even though these two models have been used almost interchangeably, they are based on different assumptions and predict differences in the relationship between reading times and response accuracy. The activation-based model follows the assumptions of ACT-R, and its retrieval process behaves as a lognormal race between accumulators of evidence with a single variance. Under this model, accuracy of the retrieval is determined by the winner of the race and retrieval time by its rate of accumulation. In contrast, the direct access model assumes a model of memory where only the probability of retrieval varies between items; in this model, differences in latencies are a by-product of the possibility and repairing incorrect retrievals. We implemented both models in a Bayesian hierarchical framework in order to evaluate them and compare them. We show that some aspects of the data are better fit under the direct access model than under the activation-based model. We suggest that this finding does not rule out the possibility that retrieval may be behaving as a race model with assumptions that follow less closely the ones from the ACT-R framework. We show that by introducing a modification of the activation model, i.e, by assuming that the accumulation of evidence for retrieval of incorrect items is not only slower but noisier (i.e., different variances for the correct and incorrect items), the model can provide a fit as good as the one of the direct access model.
Modelling dependency completion in sentence comprehension as a Bayesian hierarchical mixture process: A case study involving Chinese relative clauses
May 05, 2017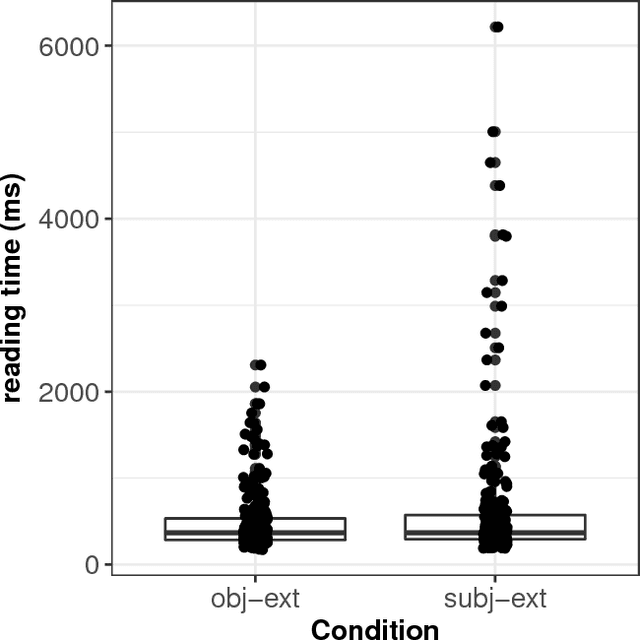


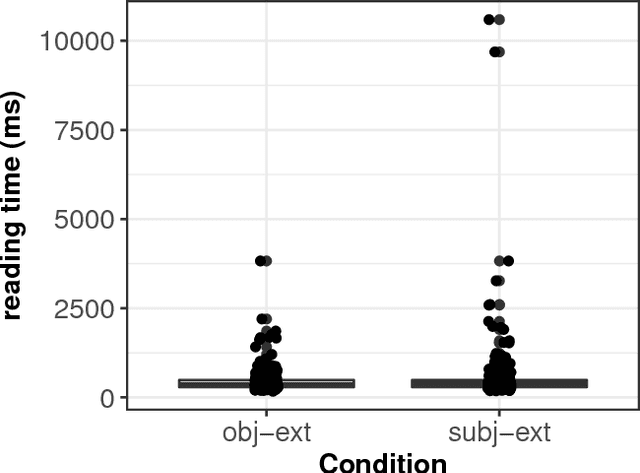
We present a case-study demonstrating the usefulness of Bayesian hierarchical mixture modelling for investigating cognitive processes. In sentence comprehension, it is widely assumed that the distance between linguistic co-dependents affects the latency of dependency resolution: the longer the distance, the longer the retrieval time (the distance-based account). An alternative theory, direct-access, assumes that retrieval times are a mixture of two distributions: one distribution represents successful retrievals (these are independent of dependency distance) and the other represents an initial failure to retrieve the correct dependent, followed by a reanalysis that leads to successful retrieval. We implement both models as Bayesian hierarchical models and show that the direct-access model explains Chinese relative clause reading time data better than the distance account.