 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cure for Pathological Behavior in Games that Use Minimax
Mar 27, 2013The traditional approach to choosing moves in game-playing programs is the minimax procedure. The general belief underlying its use is that increasing search depth improves play. Recent research has shown that given certain simplifying assumptions about a game tree's structure, this belief is erroneous: searching deeper decreases the probability of making a correct move. This phenomenon is called game tree pathology. Among these simplifying assumptions is uniform depth of win/loss (terminal) nodes, a condition which is not true for most real games. Analytic studies in [10] have shown that if every node in a pathological game tree is made terminal with probability exceeding a certain threshold, the resulting tree is nonpathological. This paper considers a new evaluation function which recognizes increasing densities of forced wins at deeper levels in the tree. This property raises two points that strengthen the hypothesis that uniform win depth causes pathology. First, it proves mathematically that as search deepens, an evaluation function that does not explicitly check for certain forced win patterns becomes decreasingly likely to force wins. This failing predicts the pathological behavior of the original evaluation function. Second, it shows empirically that despite recognizing fewer mid-game wins than the theoretically predicted minimum, the new function is nonpathological.
A Sensitivity Analysis of Pathfinder
Mar 27, 2013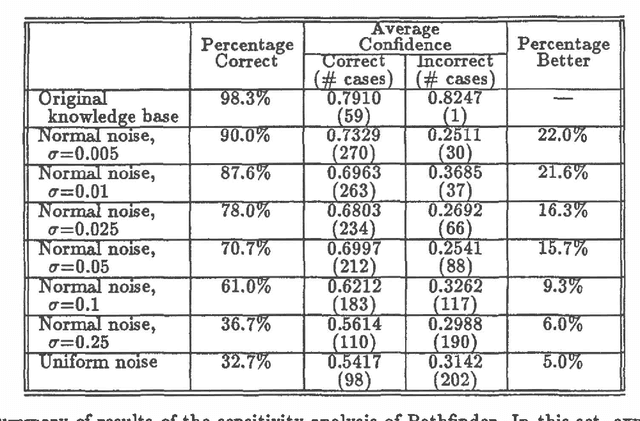
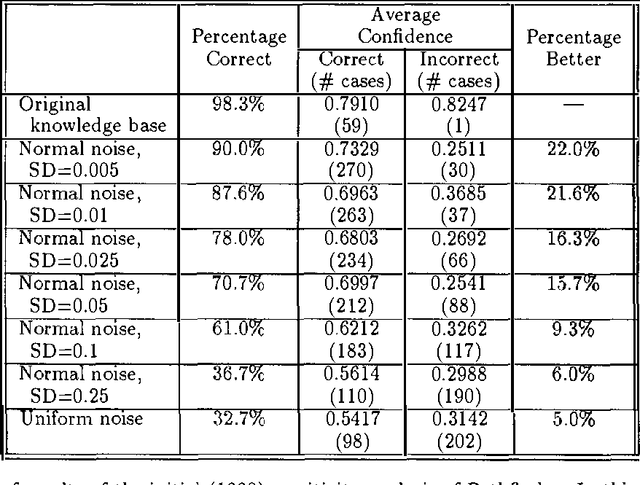
Knowledge elicitation is one of the major bottlenecks in expert system design. Systems based on Bayes nets require two types of information--network structure and parameters (or probabilities). Both must be elicited from the domain expert. In general, parameters have greater opacity than structure, and more time is spent in their refinement than in any other phase of elicitation. Thus, it is important to determine the point of diminishing returns, beyond which further refinements will promise little (if any) improvement. Sensitivity analyses address precisely this issue--the sensitivity of a model to the precision of its parameters. In this paper, we report the results of a sensitivity analysis of Pathfinder, a Bayes net based system for diagnosing pathologies of the lymph system. This analysis is intended to shed some light on the relative importance of structure and parameters to system performance, as well as the sensitivity of a system based on a Bayes net to noise in its assessed parameters.
A Sensitivity Analysis of Pathfinder: A Follow-up Study
Mar 20, 2013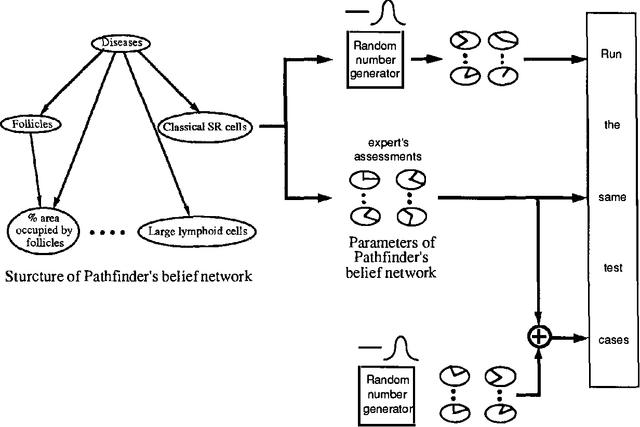
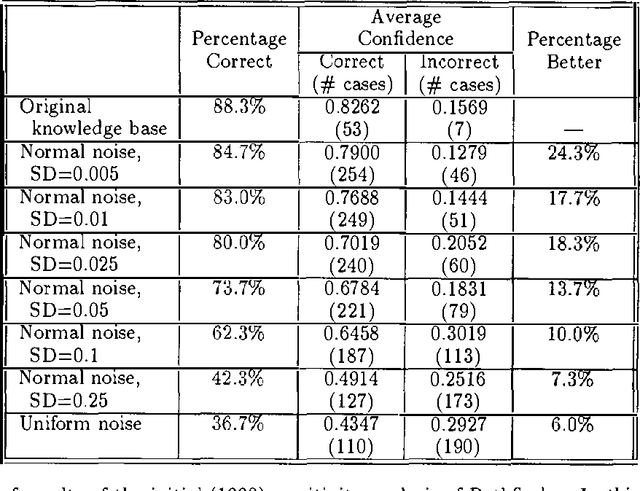
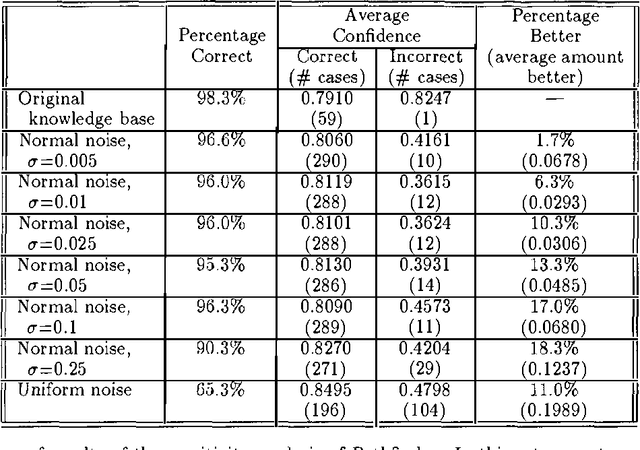
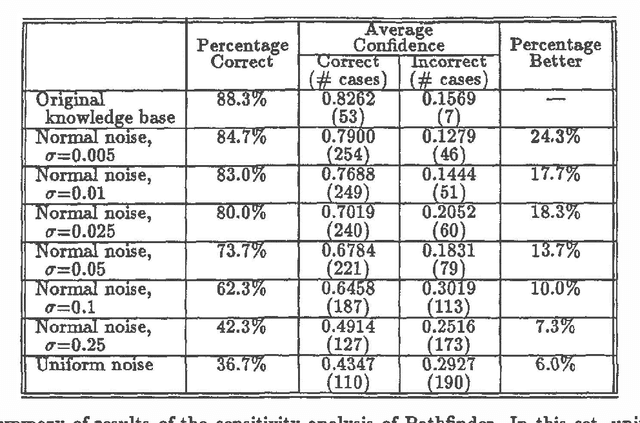
At last year?s Uncertainty in AI Conference, we reported the results of a sensitivity analysis study of Pathfinder. Our findings were quite unexpected-slight variations to Pathfinder?s parameters appeared to lead to substantial degradations in system performance. A careful look at our first analysis, together with the valuable feedback provided by the participants of last year?s conference, led us to conduct a follow-up study. Our follow-up differs from our initial study in two ways: (i) the probabilities 0.0 and 1.0 remained unchanged, and (ii) the variations to the probabilities that are close to both ends (0.0 or 1.0) were less than the ones close to the middle (0.5). The results of the follow-up study look more reasonable-slight variations to Pathfinder?s parameters now have little effect on its performance. Taken together, these two sets of results suggest a viable extension of a common decision analytic sensitivity analysis to the larger, more complex settings generally encountered in artificial intelligence.
ARCO1: An Application of Belief Networks to the Oil Market
Mar 20, 2013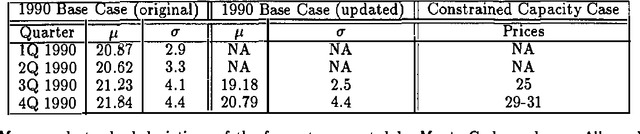
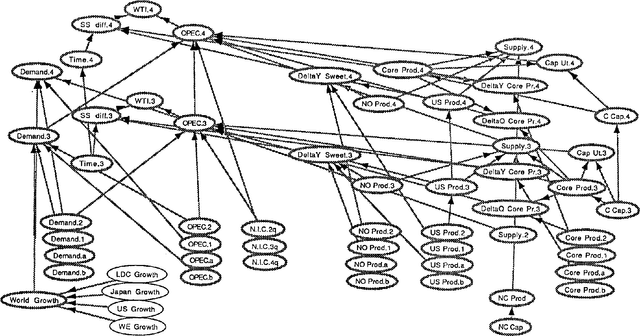
Belief networks are a new, potentially important, class of knowledge-based models. ARCO1, currently under development at the Atlantic Richfield Company (ARCO) and the University of Southern California (USC), is the most advanced reported implementation of these models in a financial forecasting setting. ARCO1's underlying belief network models the variables believed to have an impact on the crude oil market. A pictorial market model-developed on a MAC II- facilitates consensus among the members of the forecasting team. The system forecasts crude oil prices via Monte Carlo analyses of the network. Several different models of the oil market have been developed; the system's ability to be updated quickly highlights its flexibility.
The Topological Fusion of Bayes Nets
Mar 13, 2013
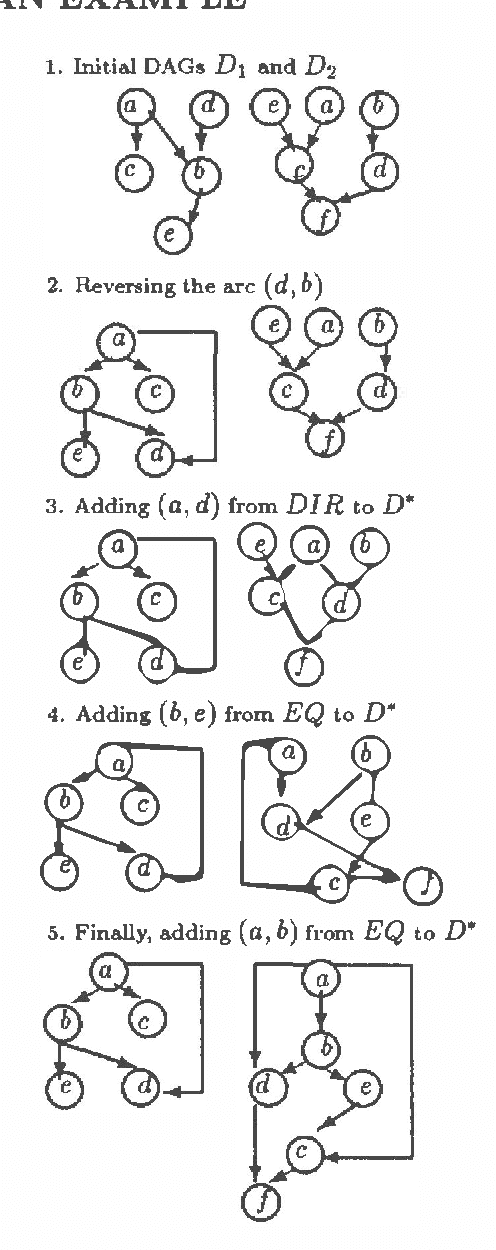
Bayes nets are relatively recent innovations. As a result, most of their theoretical development has focused on the simplest class of single-author models. The introduction of more sophisticated multiple-author settings raises a variety of interesting questions. One such question involves the nature of compromise and consensus. Posterior compromises let each model process all data to arrive at an independent response, and then split the difference. Prior compromises, on the other hand, force compromise to be reached on all points before data is observed. This paper introduces prior compromises in a Bayes net setting. It outlines the problem and develops an efficient algorithm for fusing two directed acyclic graphs into a single, consensus structure, which may then be used as the basis of a prior compromise.
Deriving a Minimal I-map of a Belief Network Relative to a Target Ordering of its Nodes
Mar 06, 2013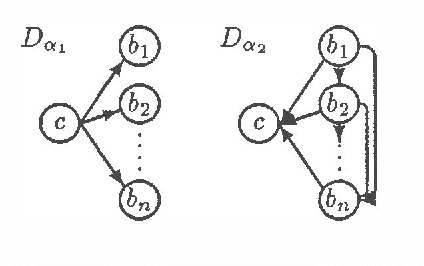
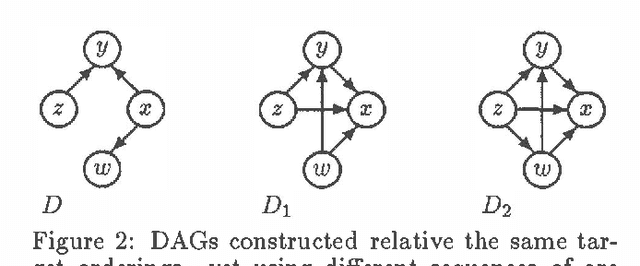
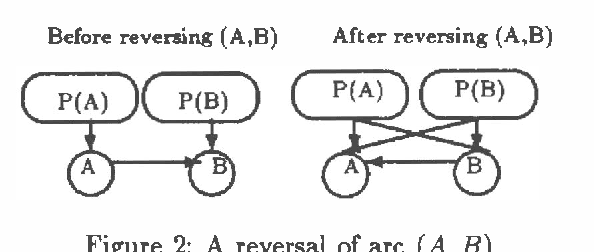
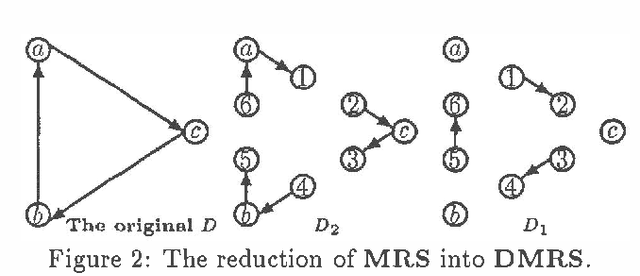
This paper identifies and solves a new optimization problem: Given a belief network (BN) and a target ordering on its variables, how can we efficiently derive its minimal I-map whose arcs are consistent with the target ordering? We present three solutions to this problem, all of which lead to directed acyclic graphs based on the original BN's recursive basis relative to the specified ordering (such a DAG is sometimes termed the boundary DAG drawn from the given BN relative to the said ordering [5]). Along the way, we also uncover an important general principal about arc reversals: when reordering a BN according to some target ordering, (while attempting to minimize the number of arcs generated), the sequence of arc reversals should follow the topological ordering induced by the original belief network's arcs to as great an extent as possible. These results promise to have a significant impact on the derivation of consensus models, as well as on other algorithms that require the reconfiguration and/or combination of BN's.
Some Complexity Considerations in the Combination of Belief Networks
Mar 06, 2013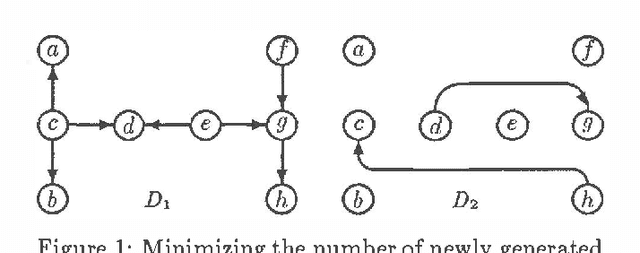
One topic that is likely to attract an increasing amount of attention within the Knowledge-base systems research community is the coordination of information provided by multiple experts. We envision a situation in which several experts independently encode information as belief networks. A potential user must then coordinate the conclusions and recommendations of these networks to derive some sort of consensus. One approach to such a consensus is the fusion of the contributed networks into a single, consensus model prior to the consideration of any case-specific data (specific observations, test results). This approach requires two types of combination procedures, one for probabilities, and one for graphs. Since the combination of probabilities is relatively well understood, the key barriers to this approach lie in the realm of graph theory. This paper provides formal definitions of some of the operations necessary to effect the necessary graphical combinations, and provides complexity analyses of these procedures. The paper's key result is that most of these operations are NP-hard, and its primary message is that the derivation of ?good? consensus networks must be done heuristically.