 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning for Temporal Data in Finance: Challenges and Opportunities
Sep 11, 2020


Temporal data are ubiquitous in the financial services (FS) industry -- traditional data like economic indicators, operational data such as bank account transactions, and modern data sources like website clickstreams -- all of these occur as a time-indexed sequence. But machine learning efforts in FS often fail to account for the temporal richness of these data, even in cases where domain knowledge suggests that the precise temporal patterns between events should contain valuable information. At best, such data are often treated as uniform time series, where there is a sequence but no sense of exact timing. At worst, rough aggregate features are computed over a pre-selected window so that static sample-based approaches can be applied (e.g. number of open lines of credit in the previous year or maximum credit utilization over the previous month). Such approaches are at odds with the deep learning paradigm which advocates for building models that act directly on raw or lightly processed data and for leveraging modern optimization techniques to discover optimal feature transformations en route to solving the modeling task at hand. Furthermore, a full picture of the entity being modeled (customer, company, etc.) might only be attainable by examining multiple data streams that unfold across potentially vastly different time scales. In this paper, we examine the different types of temporal data found in common FS use cases, review the current machine learning approaches in this area, and finally assess challenges and opportunities for researchers working at the intersection of machine learning for temporal data and applications in FS.
Conscientious Classification: A Data Scientist's Guide to Discrimination-Aware Classification
Jul 21, 2019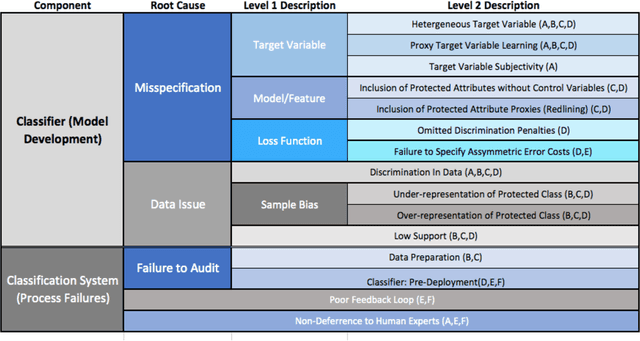
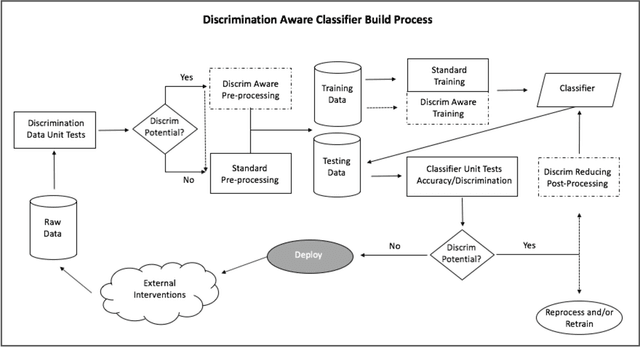
Recent research has helped to cultivate growing awareness that machine learning systems fueled by big data can create or exacerbate troubling disparities in society. Much of this research comes from outside of the practicing data science community, leaving its members with little concrete guidance to proactively address these concerns. This article introduces issues of discrimination to the data science community on its own terms. In it, we tour the familiar data mining process while providing a taxonomy of common practices that have the potential to produce unintended discrimination. We also survey how discrimination is commonly measured, and suggest how familiar development processes can be augmented to mitigate systems' discriminatory potential. We advocate that data scientists should be intentional about modeling and reducing discriminatory outcomes. Without doing so, their efforts will result in perpetuating any systemic discrimination that may exist, but under a misleading veil of data-driven objectivity.
* 30 pages, 3 figures
Explaining Classification Models Built on High-Dimensional Sparse Data
Jul 26, 2016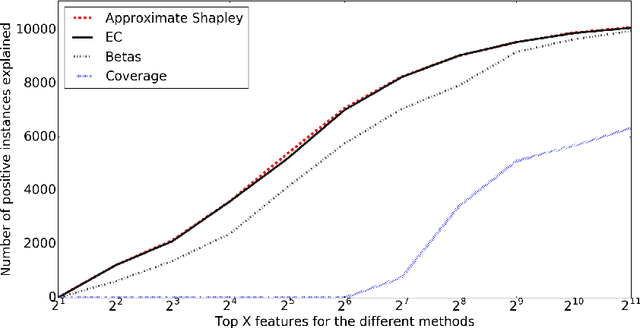

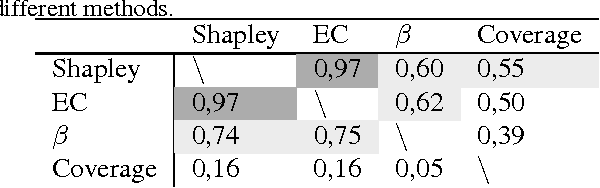
Predictive modeling applications increasingly use data representing people's behavior, opinions, and interactions. Fine-grained behavior data often has different structure from traditional data, being very high-dimensional and sparse. Models built from these data are quite difficult to interpret, since they contain many thousands or even many millions of features. Listing features with large model coefficients is not sufficient, because the model coefficients do not incorporate information on feature presence, which is key when analysing sparse data. In this paper we introduce two alternatives for explaining predictive models by listing important features. We evaluate these alternatives in terms of explanation "bang for the buck,", i.e., how many examples' inferences are explained for a given number of features listed. The bottom line: (i) The proposed alternatives have double the bang-for-the-buck as compared to just listing the high-coefficient features, and (ii) interestingly, although they come from different sources and motivations, the two new alternatives provide strikingly similar rankings of important features.