 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Classification Models Built on High-Dimensional Sparse Data
Paper and Code
Jul 26, 2016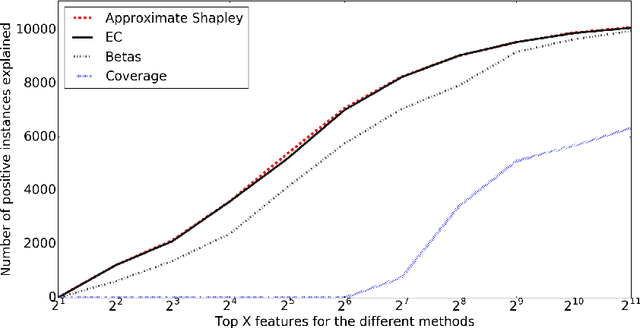

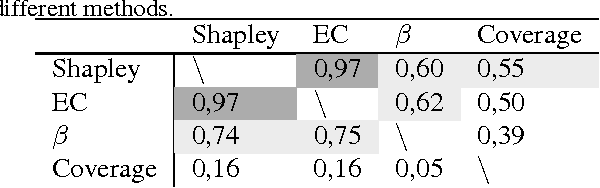
Predictive modeling applications increasingly use data representing people's behavior, opinions, and interactions. Fine-grained behavior data often has different structure from traditional data, being very high-dimensional and sparse. Models built from these data are quite difficult to interpret, since they contain many thousands or even many millions of features. Listing features with large model coefficients is not sufficient, because the model coefficients do not incorporate information on feature presence, which is key when analysing sparse data. In this paper we introduce two alternatives for explaining predictive models by listing important features. We evaluate these alternatives in terms of explanation "bang for the buck,", i.e., how many examples' inferences are explained for a given number of features listed. The bottom line: (i) The proposed alternatives have double the bang-for-the-buck as compared to just listing the high-coefficient features, and (ii) interestingly, although they come from different sources and motivations, the two new alternatives provide strikingly similar rankings of important features.