 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling wildland fire burn severity in California using a spatial Super Learner approach
Nov 25, 2023Given the increasing prevalence of wildland fires in the Western US, there is a critical need to develop tools to understand and accurately predict burn severity. We develop a machine learning model to predict post-fire burn severity using pre-fire remotely sensed data. Hydrological, ecological, and topographical variables collected from four regions of California - the sites of the Kincade fire (2019), the CZU Lightning Complex fire (2020), the Windy fire (2021), and the KNP Fire (2021) - are used as predictors of the difference normalized burn ratio. We hypothesize that a Super Learner (SL) algorithm that accounts for spatial autocorrelation using Vecchia's Gaussian approximation will accurately model burn severity. In all combinations of test and training sets explored, the results of our model showed the SL algorithm outperformed standard Linear Regression methods. After fitting and verifying the performance of the SL model, we use interpretable machine learning tools to determine the main drivers of severe burn damage, including greenness, elevation and fire weather variables. These findings provide actionable insights that enable communities to strategize interventions, such as early fire detection systems, pre-fire season vegetation clearing activities, and resource allocation during emergency responses. When implemented, this model has the potential to minimize the loss of human life, property, resources, and ecosystems in California.
Bivariate DeepKriging for Large-scale Spatial Interpolation of Wind Fields
Jul 16, 2023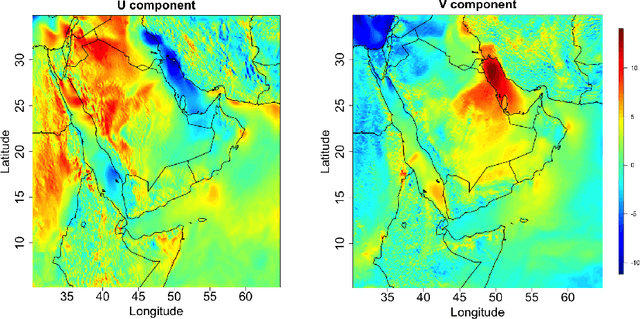



High spatial resolution wind data are essential for a wide range of applications in climate, oceanographic and meteorological studies. Large-scale spatial interpolation or downscaling of bivariate wind fields having velocity in two dimensions is a challenging task because wind data tend to be non-Gaussian with high spatial variability and heterogeneity. In spatial statistics, cokriging is commonly used for predicting bivariate spatial fields. However, the cokriging predictor is not optimal except for Gaussian processes. Additionally, cokriging is computationally prohibitive for large datasets. In this paper, we propose a method, called bivariate DeepKriging, which is a spatially dependent deep neural network (DNN) with an embedding layer constructed by spatial radial basis functions for bivariate spatial data prediction. We then develop a distribution-free uncertainty quantification method based on bootstrap and ensemble DNN. Our proposed approach outperforms the traditional cokriging predictor with commonly used covariance functions, such as the linear model of co-regionalization and flexible bivariate Mat\'ern covariance. We demonstrate the computational efficiency and scalability of the proposed DNN model, with computations that are, on average, 20 times faster than those of conventional techniques. We apply the bivariate DeepKriging method to the wind data over the Middle East region at 506,771 locations. The prediction performance of the proposed method is superior over the cokriging predictors and dramatically reduces computation time.
Spatio-temporal DeepKriging for Interpolation and Probabilistic Forecasting
Jun 20, 2023Gaussian processes (GP) and Kriging are widely used in traditional spatio-temporal mod-elling and prediction. These techniques typically presuppose that the data are observed from a stationary GP with parametric covariance structure. However, processes in real-world applications often exhibit non-Gaussianity and nonstationarity. Moreover, likelihood-based inference for GPs is computationally expensive and thus prohibitive for large datasets. In this paper we propose a deep neural network (DNN) based two-stage model for spatio-temporal interpolation and forecasting. Interpolation is performed in the first step, which utilizes a dependent DNN with the embedding layer constructed with spatio-temporal basis functions. For the second stage, we use Long-Short Term Memory (LSTM) and convolutional LSTM to forecast future observations at a given location. We adopt the quantile-based loss function in the DNN to provide probabilistic forecasting. Compared to Kriging, the proposed method does not require specifying covariance functions or making stationarity assumption, and is computationally efficient. Therefore, it is suitable for large-scale prediction of complex spatio-temporal processes. We apply our method to monthly $PM_{2.5}$ data at more than $200,000$ space-time locations from January 1999 to December 2022 for fast imputation of missing values and forecasts with uncertainties.
DeepKriging: Spatially Dependent Deep Neural Networks for Spatial Prediction
Jul 25, 2020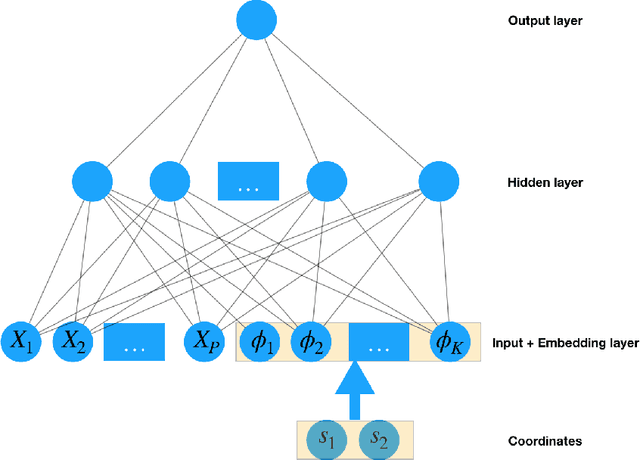

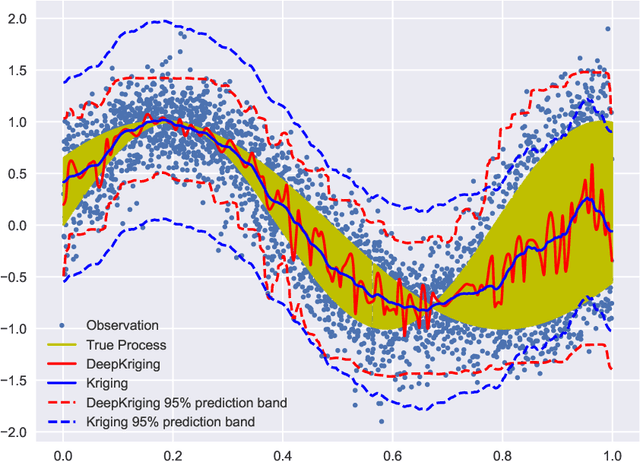
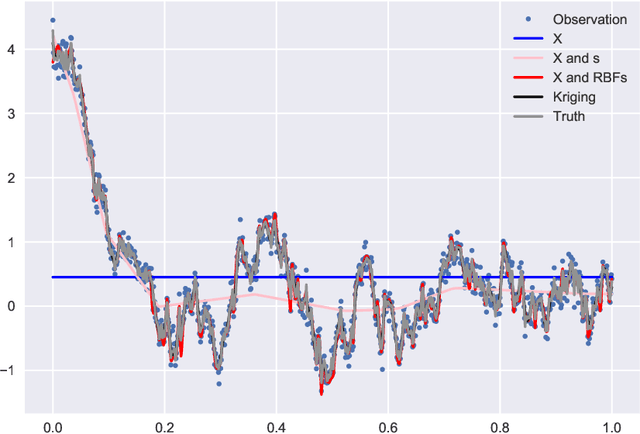
In spatial statistics, a common objective is to predict the values of a spatial process at unobserved locations by exploiting spatial dependence. In geostatistics, Kriging provides the best linear unbiased predictor using covariance functions and is often associated with Gaussian processes. However, when considering non-linear prediction for non-Gaussian and categorical data, the Kriging prediction is not necessarily optimal, and the associated variance is often overly optimistic. We propose to use deep neural networks (DNNs) for spatial prediction. Although DNNs are widely used for general classification and prediction, they have not been studied thoroughly for data with spatial dependence. In this work, we propose a novel neural network structure for spatial prediction by adding an embedding layer of spatial coordinates with basis functions. We show in theory that the proposed DeepKriging method has multiple advantages over Kriging and classical DNNs only with spatial coordinates as features. We also provide density prediction for uncertainty quantification without any distributional assumption and apply the method to PM$_{2.5}$ concentrations across the continental United States.
Nearest-Neighbor Neural Networks for Geostatistics
Mar 28, 2019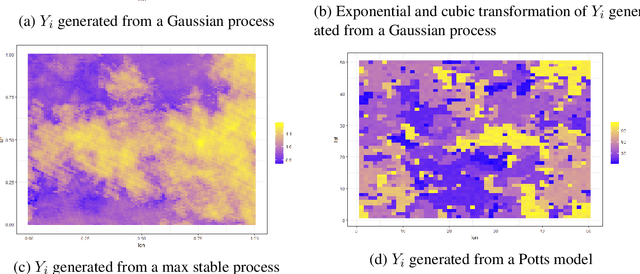
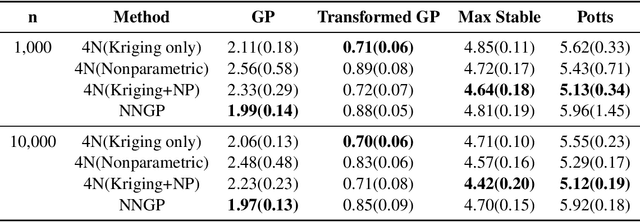
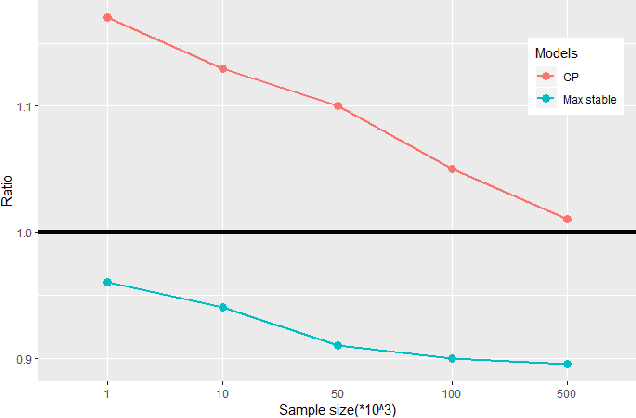
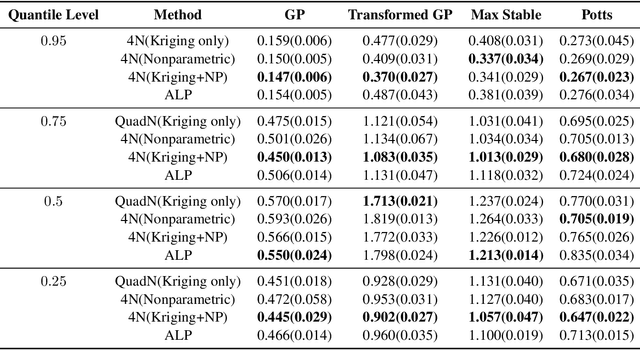
Kriging is the predominant method used for spatial prediction, but relies on the assumption that predictions are linear combinations of the observations. Kriging often also relies on additional assumptions such as normality and stationarity. We propose a more flexible spatial prediction method based on the Nearest-Neighbor Neural Network (4N) process that embeds deep learning into a geostatistical model. We show that the 4N process is a valid stochastic process and propose a series of new ways to construct features to be used as inputs to the deep learning model based on neighboring information. Our model framework outperforms some existing state-of-art geostatistical modelling methods for simulated non-Gaussian data and is applied to a massive forestry dataset.