 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrassmann Iterative Linear Discriminant Analysis with Proxy Matrix Optimization
Apr 16, 2021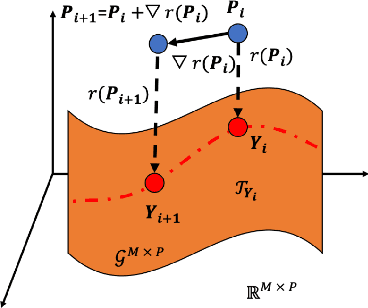

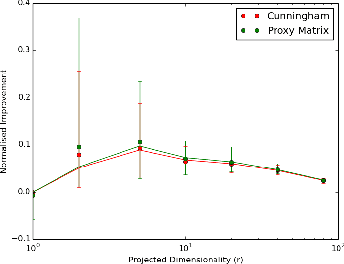
Linear Discriminant Analysis (LDA) is commonly used for dimensionality reduction in pattern recognition and statistics. It is a supervised method that aims to find the most discriminant space of reduced dimension that can be further used for classification. In this work, we present a Grassmann Iterative LDA method (GILDA) that is based on Proxy Matrix Optimization (PMO). PMO makes use of automatic differentiation and stochastic gradient descent (SGD) on the Grassmann manifold to arrive at the optimal projection matrix. Our results show that GILDAoutperforms the prevailing manifold optimization method.
Benchmarking Deep Trackers on Aerial Videos
Mar 24, 2021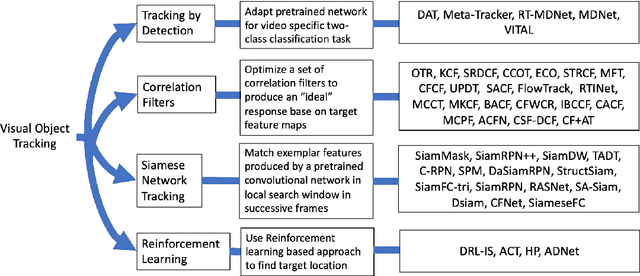
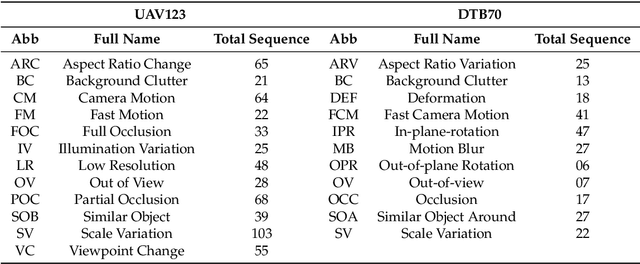


In recent years, deep learning-based visual object trackers have achieved state-of-the-art performance on several visual object tracking benchmarks. However, most tracking benchmarks are focused on ground level videos, whereas aerial tracking presents a new set of challenges. In this paper, we compare ten trackers based on deep learning techniques on four aerial datasets. We choose top performing trackers utilizing different approaches, specifically tracking by detection, discriminative correlation filters, Siamese networks and reinforcement learning. In our experiments, we use a subset of OTB2015 dataset with aerial style videos; the UAV123 dataset without synthetic sequences; the UAV20L dataset, which contains 20 long sequences; and DTB70 dataset as our benchmark datasets. We compare the advantages and disadvantages of different trackers in different tracking situations encountered in aerial data. Our findings indicate that the trackers perform significantly worse in aerial datasets compared to standard ground level videos. We attribute this effect to smaller target size, camera motion, significant camera rotation with respect to the target, out of view movement, and clutter in the form of occlusions or similar looking distractors near tracked object.
* 25 pages, 10 figures, 7 tables
Cascaded Projection: End-to-End Network Compression and Acceleration
Mar 12, 2019


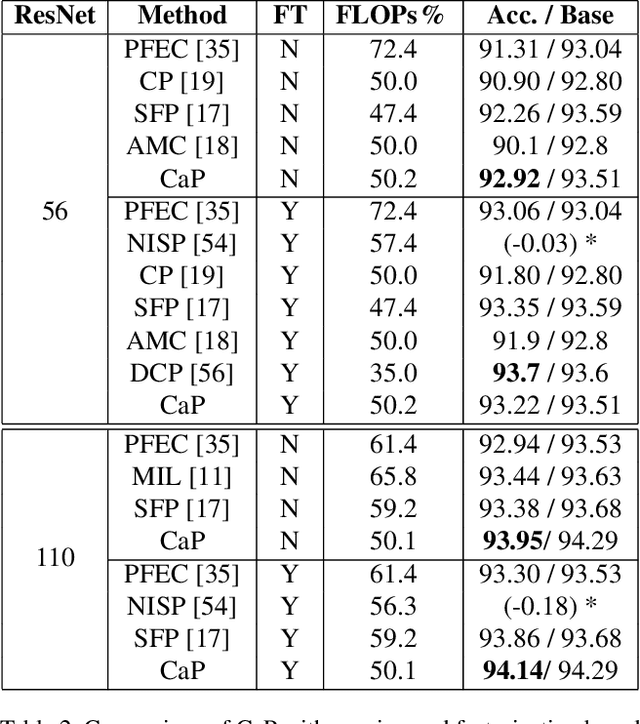
We propose a data-driven approach for deep convolutional neural network compression that achieves high accuracy with high throughput and low memory requirements. Current network compression methods either find a low-rank factorization of the features that requires more memory, or select only a subset of features by pruning entire filter channels. We propose the Cascaded Projection (CaP) compression method that projects the output and input filter channels of successive layers to a unified low dimensional space based on a low-rank projection. We optimize the projection to minimize classification loss and the difference between the next layer's features in the compressed and uncompressed networks. To solve this non-convex optimization problem we propose a new optimization method of a proxy matrix using backpropagation and Stochastic Gradient Descent (SGD) with geometric constraints. Our cascaded projection approach leads to improvements in all critical areas of network compression: high accuracy, low memory consumption, low parameter count and high processing speed. The proposed CaP method demonstrates state-of-the-art results compressing VGG16 and ResNet networks with over 4x reduction in the number of computations and excellent performance in top-5 accuracy on the ImageNet dataset before and after fine-tuning.
DEFRAG: Deep Euclidean Feature Representations through Adaptation on the Grassmann Manifold
Jun 20, 2018



We propose a novel technique for training deep networks with the objective of obtaining feature representations that exist in a Euclidean space and exhibit strong clustering behavior. Our desired features representations have three traits: they can be compared using a standard Euclidian distance metric, samples from the same class are tightly clustered, and samples from different classes are well separated. However, most deep networks do not enforce such feature representations. The DEFRAG training technique consists of two steps: first good feature clustering behavior is encouraged though an auxiliary loss function based on the Silhouette clustering metric. Then the feature space is retracted onto a Grassmann manifold to ensure that the L_2 Norm forms a similarity metric. The DEFRAG technique achieves state of the art results on standard classification datasets using a relatively small network architecture with significantly fewer parameters than many standard networks.