 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyT2V: LLM-Guided Iterative Self-Refinement for Physics-Grounded Text-to-Video Generation
Nov 30, 2024Text-to-video (T2V) generation has been recently enabled by transformer-based diffusion models, but current T2V models lack capabilities in adhering to the real-world common knowledge and physical rules, due to their limited understanding of physical realism and deficiency in temporal modeling. Existing solutions are either data-driven or require extra model inputs, but cannot be generalizable to out-of-distribution domains. In this paper, we present PhyT2V, a new data-independent T2V technique that expands the current T2V model's capability of video generation to out-of-distribution domains, by enabling chain-of-thought and step-back reasoning in T2V prompting. Our experiments show that PhyT2V improves existing T2V models' adherence to real-world physical rules by 2.3x, and achieves 35% improvement compared to T2V prompt enhancers. The source codes are available at: https://github.com/pittisl/PhyT2V.
Achieving Sparse Activation in Small Language Models
Jun 03, 2024Sparse activation, which selectively activates only an input-dependent set of neurons in inference, is a useful technique to reduce the computing cost of Large Language Models (LLMs) without retraining or adaptation efforts. However, whether it can be applied to the recently emerging Small Language Models (SLMs) remains questionable, because SLMs are generally less over-parameterized than LLMs. In this paper, we aim to achieve sparse activation in SLMs. We first show that the existing sparse activation schemes in LLMs that build on neurons' output magnitudes cannot be applied to SLMs, and activating neurons based on their attribution scores is a better alternative. Further, we demonstrated and quantified the large errors of existing attribution metrics when being used for sparse activation, due to the interdependency among attribution scores of neurons across different layers. Based on these observations, we proposed a new attribution metric that can provably correct such errors and achieve precise sparse activation. Experiments over multiple popular SLMs and datasets show that our approach can achieve 80% sparsification ratio with <5% model accuracy loss, comparable to the sparse activation achieved in LLMs. The source code is available at: https://github.com/pittisl/Sparse-Activation.
ElasticTrainer: Speeding Up On-Device Training with Runtime Elastic Tensor Selection
Dec 21, 2023



On-device training is essential for neural networks (NNs) to continuously adapt to new online data, but can be time-consuming due to the device's limited computing power. To speed up on-device training, existing schemes select trainable NN portion offline or conduct unrecoverable selection at runtime, but the evolution of trainable NN portion is constrained and cannot adapt to the current need for training. Instead, runtime adaptation of on-device training should be fully elastic, i.e., every NN substructure can be freely removed from or added to the trainable NN portion at any time in training. In this paper, we present ElasticTrainer, a new technique that enforces such elasticity to achieve the required training speedup with the minimum NN accuracy loss. Experiment results show that ElasticTrainer achieves up to 3.5x more training speedup in wall-clock time and reduces energy consumption by 2x-3x more compared to the existing schemes, without noticeable accuracy loss.
Modality Plug-and-Play: Elastic Modality Adaptation in Multimodal LLMs for Embodied AI
Dec 13, 2023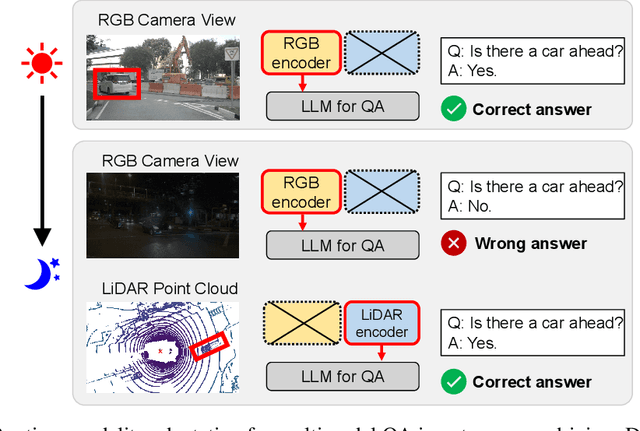

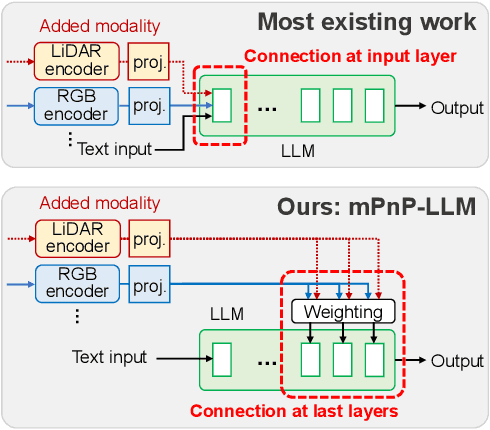

Large Language Models (LLMs) are capable of reasoning over diverse input data modalities through pre-trained encoders. However, the growing diversity of input data modalities prevents incorporating all modalities into LLMs, especially when LLMs are deployed on resource-constrained edge devices for embodied AI applications. Instead, a better option is to adaptively involve only the useful modalities at runtime, depending on the current environmental contexts and task requirements. For such modality adaptation, existing work adopts fixed connections between encoders and the LLM's input layer, leading to high training cost at runtime and ineffective cross-modal interaction. In this paper, we address these limitations by presenting mPnP-LLM, a new technique that allows fully elastic, automated and prompt runtime modality adaptation, by connecting unimodal encoders to a flexible set of last LLM blocks and making such latent connections fully trainable at runtime. Experiments over the nuScenes-QA dataset show that mPnP-LLM can achieve up to 3.7x FLOPs reduction and 30% GPU memory usage reduction, while retaining on-par accuracy with the existing schemes. Under the same compute budget, mPnP-LLM improves the task accuracy by up to 4% compared to the best existing scheme.