 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Methods for Model-Based Reinforcement Learning
Oct 28, 2019
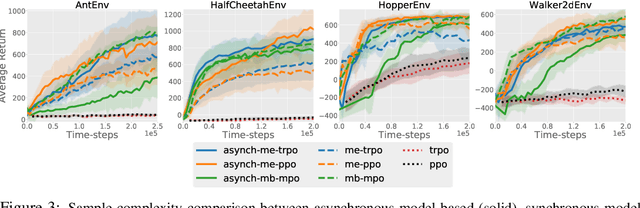
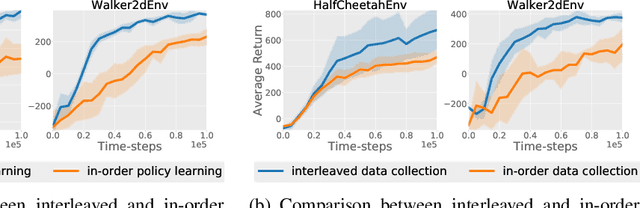
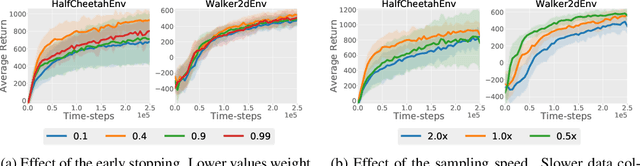
Significant progress has been made in the area of model-based reinforcement learning. State-of-the-art algorithms are now able to match the asymptotic performance of model-free methods while being significantly more data efficient. However, this success has come at a price: state-of-the-art model-based methods require significant computation interleaved with data collection, resulting in run times that take days, even if the amount of agent interaction might be just hours or even minutes. When considering the goal of learning in real-time on real robots, this means these state-of-the-art model-based algorithms still remain impractical. In this work, we propose an asynchronous framework for model-based reinforcement learning methods that brings down the run time of these algorithms to be just the data collection time. We evaluate our asynchronous framework on a range of standard MuJoCo benchmarks. We also evaluate our asynchronous framework on three real-world robotic manipulation tasks. We show how asynchronous learning not only speeds up learning w.r.t wall-clock time through parallelization, but also further reduces the sample complexity of model-based approaches by means of improving the exploration and by means of effectively avoiding the policy overfitting to the deficiencies of learned dynamics models.