 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionBench: A Comprehensive Benchmark of Deep Model Fusion
Jun 07, 2024Deep model fusion is an emerging technique that unifies the predictions or parameters of several deep neural networks into a single model in a cost-effective and data-efficient manner. This enables the unified model to take advantage of the original models' strengths, potentially exceeding their performance. Although a variety of deep model fusion techniques have been introduced, their evaluations tend to be inconsistent and often inadequate to validate their effectiveness and robustness against distribution shifts. To address this issue, we introduce FusionBench, which is the first comprehensive benchmark dedicated to deep model fusion. FusionBench covers a wide range of tasks, including open-vocabulary image classification, text classification, and text-to-text generation. Each category includes up to eight tasks with corresponding task-specific models, featuring both full fine-tuning and LoRA fine-tuning, as well as models of different sizes, to ensure fair and balanced comparisons of various multi-task model fusion techniques across different tasks, model scales, and fine-tuning strategies. We implement and evaluate a broad spectrum of deep model fusion techniques. These techniques range from model ensemble methods, which combine the predictions to improve the overall performance, to model merging, which integrates different models into a single one, and model mixing methods, which upscale or recombine the components of the original models. FusionBench now contains 26 distinct tasks, 74 fine-tuned models, and 16 fusion techniques, and we are committed to consistently expanding the benchmark with more tasks, models, and fusion techniques. In addition, we offer a well-documented set of resources and guidelines to aid researchers in understanding and replicating the benchmark results. Homepage https://github.com/tanganke/fusion_bench
Unsupervised Change Detection in Multi-temporal VHR Images Based on Deep Kernel PCA Convolutional Mapping Network
Dec 18, 2019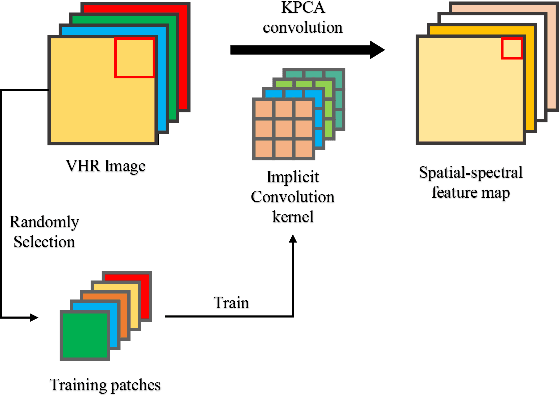
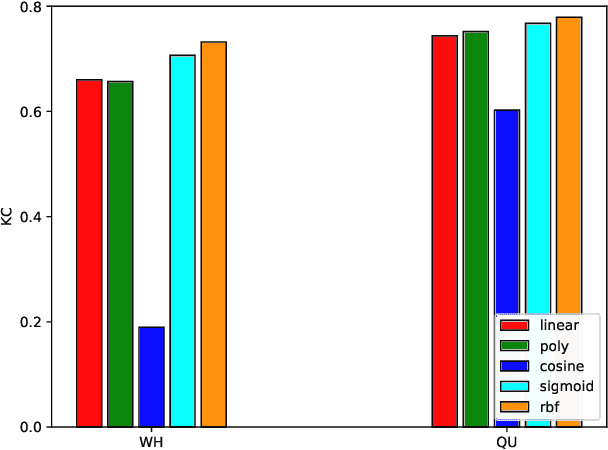


With the development of Earth observation technology, very-high-resolution (VHR) image has become an important data source of change detection. Nowadays, deep learning methods have achieved conspicuous performance in the change detection of VHR images. Nonetheless, most of the existing change detection models based on deep learning require annotated training samples. In this paper, a novel unsupervised model called kernel principal component analysis (KPCA) convolution is proposed for extracting representative features from multi-temporal VHR images. Based on the KPCA convolution, an unsupervised deep siamese KPCA convolutional mapping network (KPCA-MNet) is designed for binary and multi-class change detection. In the KPCA-MNet, the high-level spatial-spectral feature maps are extracted by a deep siamese network consisting of weight-shared PCA convolution layers. Then, the change information in the feature difference map is mapped into a 2-D polar domain. Finally, the change detection results are generated by threshold segmentation and clustering algorithms. All procedures of KPCA-MNet does not require labeled data. The theoretical analysis and experimental results demonstrate the validity, robustness, and potential of the proposed method in two binary change detection data sets and one multi-class change detection data set.