 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverywhere Attack: Attacking Locally and Globally to Boost Targeted Transferability
Jan 01, 2025
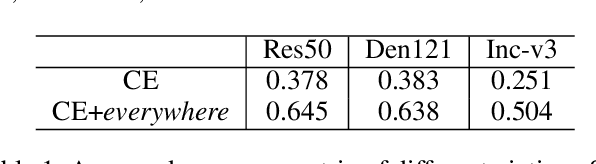
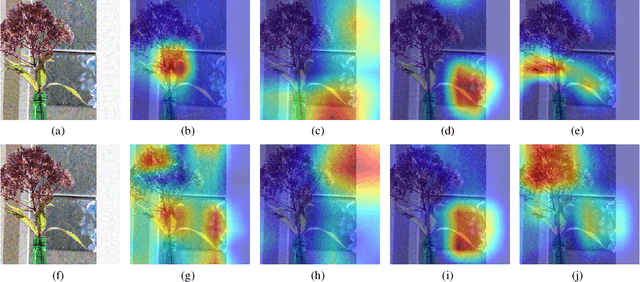
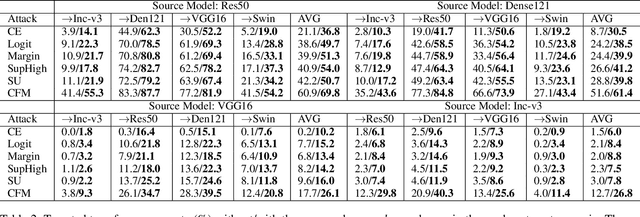
Adversarial examples' (AE) transferability refers to the phenomenon that AEs crafted with one surrogate model can also fool other models. Notwithstanding remarkable progress in untargeted transferability, its targeted counterpart remains challenging. This paper proposes an everywhere scheme to boost targeted transferability. Our idea is to attack a victim image both globally and locally. We aim to optimize 'an army of targets' in every local image region instead of the previous works that optimize a high-confidence target in the image. Specifically, we split a victim image into non-overlap blocks and jointly mount a targeted attack on each block. Such a strategy mitigates transfer failures caused by attention inconsistency between surrogate and victim models and thus results in stronger transferability. Our approach is method-agnostic, which means it can be easily combined with existing transferable attacks for even higher transferability. Extensive experiments on ImageNet demonstrate that the proposed approach universally improves the state-of-the-art targeted attacks by a clear margin, e.g., the transferability of the widely adopted Logit attack can be improved by 28.8%-300%.We also evaluate the crafted AEs on a real-world platform: Google Cloud Vision. Results further support the superiority of the proposed method.
Two Heads Are Better Than One: Averaging along Fine-Tuning to Improve Targeted Transferability
Dec 30, 2024



With much longer optimization time than that of untargeted attacks notwithstanding, the transferability of targeted attacks is still far from satisfactory. Recent studies reveal that fine-tuning an existing adversarial example (AE) in feature space can efficiently boost its targeted transferability. However, existing fine-tuning schemes only utilize the endpoint and ignore the valuable information in the fine-tuning trajectory. Noting that the vanilla fine-tuning trajectory tends to oscillate around the periphery of a flat region of the loss surface, we propose averaging over the fine-tuning trajectory to pull the crafted AE towards a more centered region. We compare the proposed method with existing fine-tuning schemes by integrating them with state-of-the-art targeted attacks in various attacking scenarios. Experimental results uphold the superiority of the proposed method in boosting targeted transferability. The code is available at github.com/zengh5/Avg_FT.
Enhancing targeted transferability via feature space fine-tuning
Jan 13, 2024



Adversarial examples (AEs) have been extensively studied due to their potential for privacy protection and inspiring robust neural networks. Yet, making a targeted AE transferable across unknown models remains challenging. In this paper, to alleviate the overfitting dilemma common in an AE crafted by existing simple iterative attacks, we propose fine-tuning it in the feature space. Specifically, starting with an AE generated by a baseline attack, we encourage the features conducive to the target class and discourage the features to the original class in a middle layer of the source model. Extensive experiments demonstrate that only a few iterations of fine-tuning can boost existing attacks' targeted transferability nontrivially and universally. Our results also verify that the simple iterative attacks can yield comparable or even better transferability than the resource-intensive methods, which rest on training target-specific classifiers or generators with additional data. The code is available at: github.com/zengh5/TA_feature_FT.