 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiREN: Towards Higher Supervision Quality for Better Scene Text Image Super-Resolution
Jul 31, 2023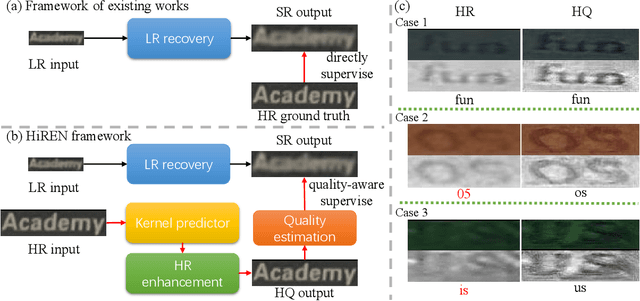
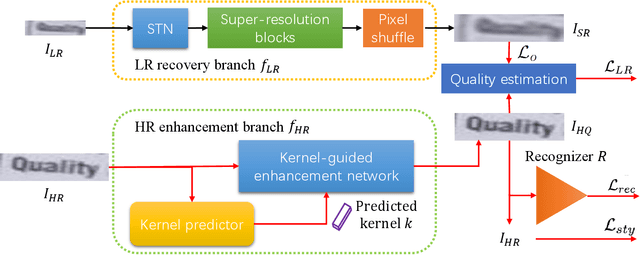
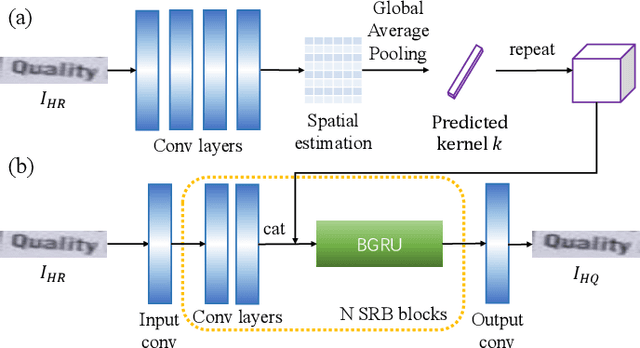

Scene text image super-resolution (STISR) is an important pre-processing technique for text recognition from low-resolution scene images. Nowadays, various methods have been proposed to extract text-specific information from high-resolution (HR) images to supervise STISR model training. However, due to uncontrollable factors (e.g. shooting equipment, focus, and environment) in manually photographing HR images, the quality of HR images cannot be guaranteed, which unavoidably impacts STISR performance. Observing the quality issue of HR images, in this paper we propose a novel idea to boost STISR by first enhancing the quality of HR images and then using the enhanced HR images as supervision to do STISR. Concretely, we develop a new STISR framework, called High-Resolution ENhancement (HiREN) that consists of two branches and a quality estimation module. The first branch is developed to recover the low-resolution (LR) images, and the other is an HR quality enhancement branch aiming at generating high-quality (HQ) text images based on the HR images to provide more accurate supervision to the LR images. As the degradation from HQ to HR may be diverse, and there is no pixel-level supervision for HQ image generation, we design a kernel-guided enhancement network to handle various degradation, and exploit the feedback from a recognizer and text-level annotations as weak supervision signal to train the HR enhancement branch. Then, a quality estimation module is employed to evaluate the qualities of HQ images, which are used to suppress the erroneous supervision information by weighting the loss of each image. Extensive experiments on TextZoom show that HiREN can work well with most existing STISR methods and significantly boost their performances.
C3-STISR: Scene Text Image Super-resolution with Triple Clues
Apr 29, 2022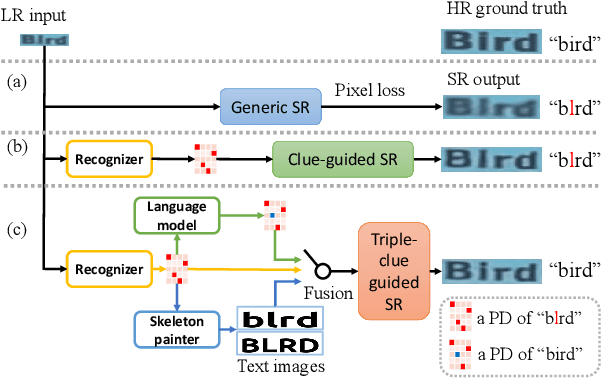
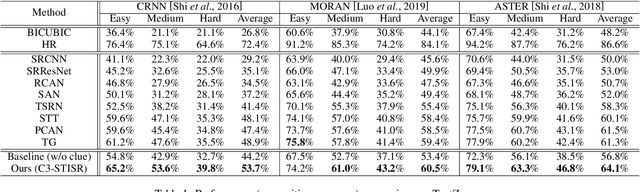

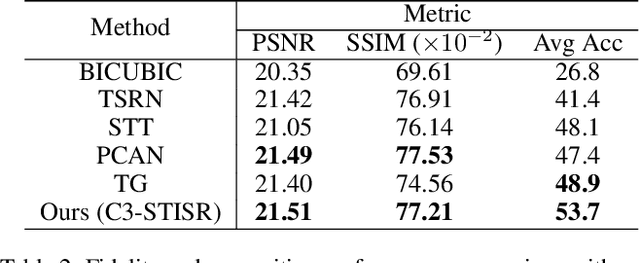
Scene text image super-resolution (STISR) has been regarded as an important pre-processing task for text recognition from low-resolution scene text images. Most recent approaches use the recognizer's feedback as clues to guide super-resolution. However, directly using recognition clue has two problems: 1) Compatibility. It is in the form of probability distribution, has an obvious modal gap with STISR - a pixel-level task; 2) Inaccuracy. it usually contains wrong information, thus will mislead the main task and degrade super-resolution performance. In this paper, we present a novel method C3-STISR that jointly exploits the recognizer's feedback, visual and linguistical information as clues to guide super-resolution. Here, visual clue is from the images of texts predicted by the recognizer, which is informative and more compatible with the STISR task; while linguistical clue is generated by a pre-trained character-level language model, which is able to correct the predicted texts. We design effective extraction and fusion mechanisms for the triple cross-modal clues to generate a comprehensive and unified guidance for super-resolution. Extensive experiments on TextZoom show that C3-STISR outperforms the SOTA methods in fidelity and recognition performance. Code is available in https://github.com/zhaominyiz/C3-STISR.