 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtraction of Medication Names from Twitter Using Augmentation and an Ensemble of Language Models
Nov 12, 2021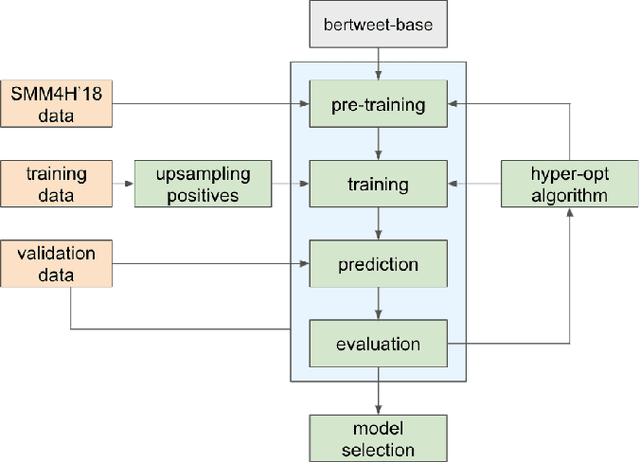
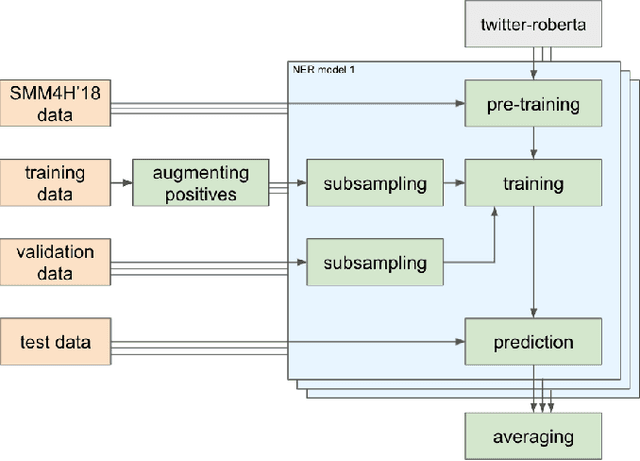
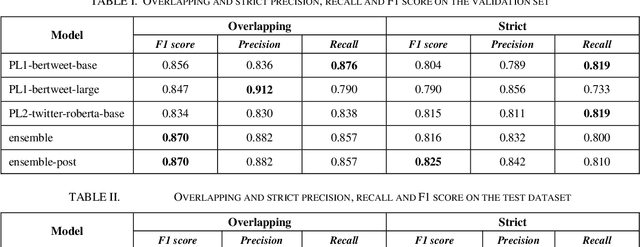
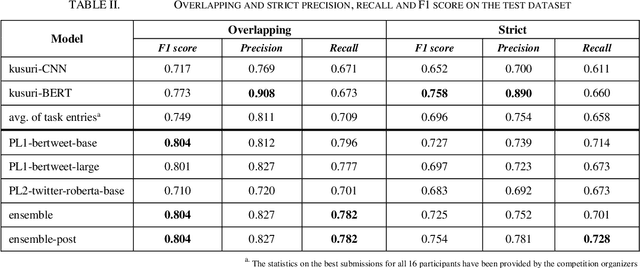
The BioCreative VII Track 3 challenge focused on the identification of medication names in Twitter user timelines. For our submission to this challenge, we expanded the available training data by using several data augmentation techniques. The augmented data was then used to fine-tune an ensemble of language models that had been pre-trained on general-domain Twitter content. The proposed approach outperformed the prior state-of-the-art algorithm Kusuri and ranked high in the competition for our selected objective function, overlapping F1 score.
Use of Affective Visual Information for Summarization of Human-Centric Videos
Jul 08, 2021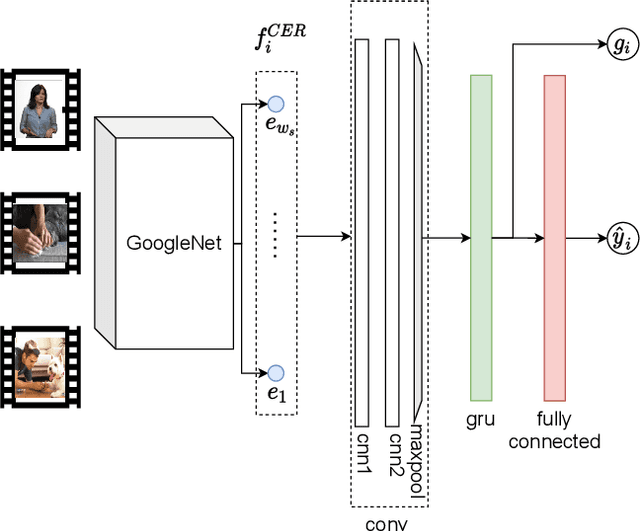

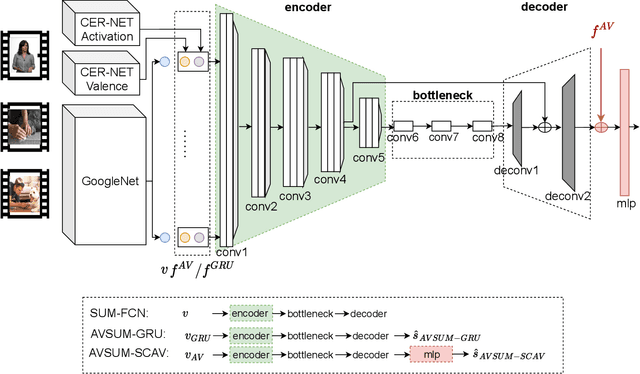
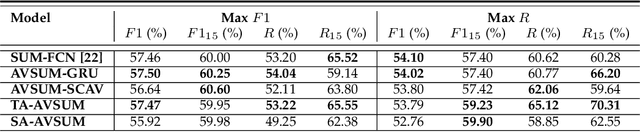
Increasing volume of user-generated human-centric video content and their applications, such as video retrieval and browsing, require compact representations that are addressed by the video summarization literature. Current supervised studies formulate video summarization as a sequence-to-sequence learning problem and the existing solutions often neglect the surge of human-centric view, which inherently contains affective content. In this study, we investigate the affective-information enriched supervised video summarization task for human-centric videos. First, we train a visual input-driven state-of-the-art continuous emotion recognition model (CER-NET) on the RECOLA dataset to estimate emotional attributes. Then, we integrate the estimated emotional attributes and the high-level representations from the CER-NET with the visual information to define the proposed affective video summarization architectures (AVSUM). In addition, we investigate the use of attention to improve the AVSUM architectures and propose two new architectures based on temporal attention (TA-AVSUM) and spatial attention (SA-AVSUM). We conduct video summarization experiments on the TvSum database. The proposed AVSUM-GRU architecture with an early fusion of high level GRU embeddings and the temporal attention based TA-AVSUM architecture attain competitive video summarization performances by bringing strong performance improvements for the human-centric videos compared to the state-of-the-art in terms of F-score and self-defined face recall metrics.
Neural Network Based Sleep Phases Classification for Resource Constraint Environments
May 25, 2021Sleep is restoration process of the body. The efficiency of this restoration process is directly correlated to the amount of time spent at each sleep phase. Hence, automatic tracking of sleep via wearable devices has attracted both the researchers and industry. Current state-of-the-art sleep tracking solutions are memory and processing greedy and they require cloud or mobile phone connectivity. We propose a memory efficient sleep tracking architecture which can work in the embedded environment without needing any cloud or mobile phone connection. In this study, a novel architecture is proposed that consists of a feature extraction and Artificial Neural Networks based stacking classifier. Besides, we discussed how to tackle with sequential nature of the sleep staging for the memory constraint environments through the proposed framework. To verify the system, a dataset is collected from 24 different subjects for 31 nights with a wrist worn device having 3-axis accelerometer (ACC) and photoplethysmogram (PPG) sensors. Over the collected dataset, the proposed classification architecture achieves 20\% and 14\% better F1 scores than its competitors. Apart from the superior performance, proposed architecture is a promising solution for resource constraint embedded systems by allocating only 4.2 kilobytes of memory (RAM).