 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharing Generative Models Instead of Private Data: A Simulation Study on Mammography Patch Classification
Mar 08, 2022



Early detection of breast cancer in mammography screening via deep-learning based computer-aided detection systems shows promising potential in improving the curability and mortality rates of breast cancer. However, many clinical centres are restricted in the amount and heterogeneity of available data to train such models to (i) achieve promising performance and to (ii) generalise well across acquisition protocols and domains. As sharing data between centres is restricted due to patient privacy concerns, we propose a potential solution: sharing trained generative models between centres as substitute for real patient data. In this work, we use three well known mammography datasets to simulate three different centres, where one centre receives the trained generator of Generative Adversarial Networks (GANs) from the two remaining centres in order to augment the size and heterogeneity of its training dataset. We evaluate the utility of this approach on mammography patch classification on the test set of the GAN-receiving centre using two different classification models, (a) a convolutional neural network and (b) a transformer neural network. Our experiments demonstrate that shared GANs notably increase the performance of both transformer and convolutional classification models and highlight this approach as a viable alternative to inter-centre data sharing.
Analysis of Video Feature Learning in Two-Stream CNNs on the Example of Zebrafish Swim Bout Classification
Dec 20, 2019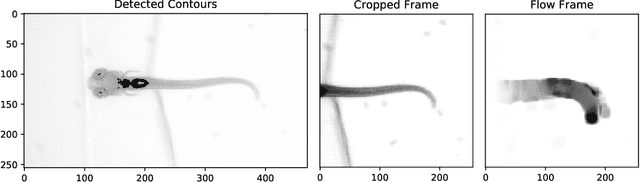

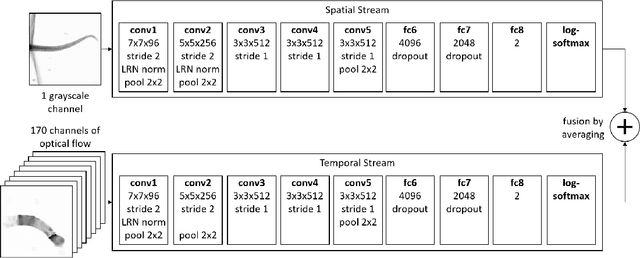
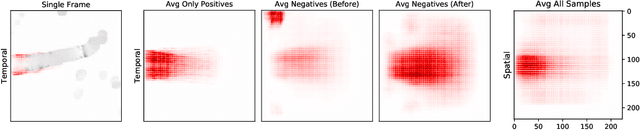
Semmelhack et al. (2014) have achieved high classification accuracy in distinguishing swim bouts of zebrafish using a Support Vector Machine (SVM). Convolutional Neural Networks (CNNs) have reached superior performance in various image recognition tasks over SVMs, but these powerful networks remain a black box. Reaching better transparency helps to build trust in their classifications and makes learned features interpretable to experts. Using a recently developed technique called Deep Taylor Decomposition, we generated heatmaps to highlight input regions of high relevance for predictions. We find that our CNN makes predictions by analyzing the steadiness of the tail's trunk, which markedly differs from the manually extracted features used by Semmelhack et al. (2014). We further uncovered that the network paid attention to experimental artifacts. Removing these artifacts ensured the validity of predictions. After correction, our best CNN beats the SVM by 6.12%, achieving a classification accuracy of 96.32%. Our work thus demonstrates the utility of AI explainability for CNNs.