 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Confident Steps to New Pockets: Strategies for Docking Generalization
Feb 28, 2024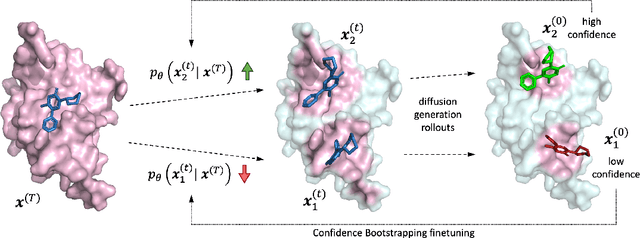
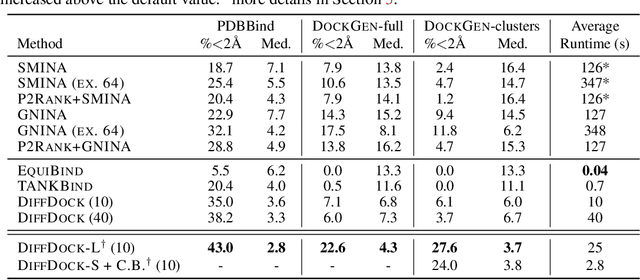
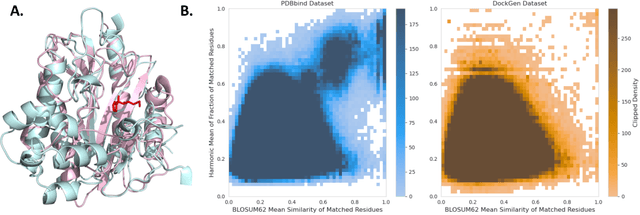
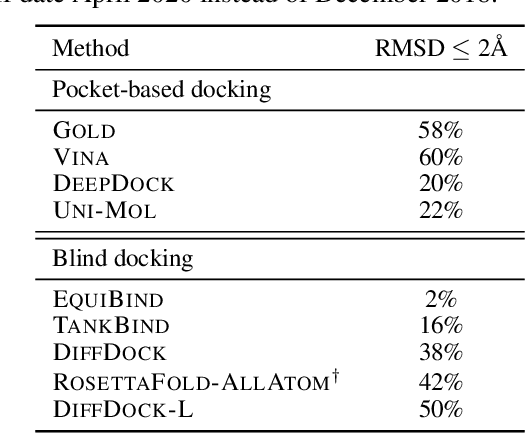
Accurate blind docking has the potential to lead to new biological breakthroughs, but for this promise to be realized, docking methods must generalize well across the proteome. Existing benchmarks, however, fail to rigorously assess generalizability. Therefore, we develop DockGen, a new benchmark based on the ligand-binding domains of proteins, and we show that existing machine learning-based docking models have very weak generalization abilities. We carefully analyze the scaling laws of ML-based docking and show that, by scaling data and model size, as well as integrating synthetic data strategies, we are able to significantly increase the generalization capacity and set new state-of-the-art performance across benchmarks. Further, we propose Confidence Bootstrapping, a new training paradigm that solely relies on the interaction between diffusion and confidence models and exploits the multi-resolution generation process of diffusion models. We demonstrate that Confidence Bootstrapping significantly improves the ability of ML-based docking methods to dock to unseen protein classes, edging closer to accurate and generalizable blind docking methods.