 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoreset Spectral Clustering
Mar 10, 2025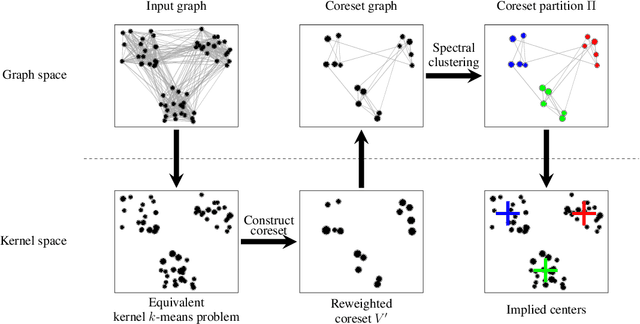
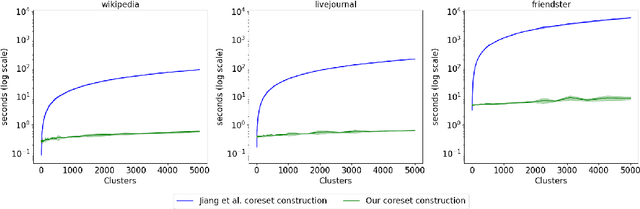
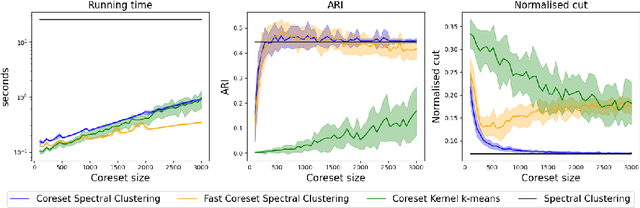
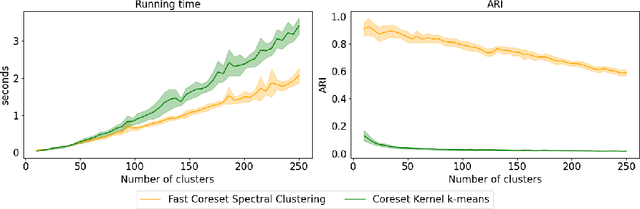
Coresets have become an invaluable tool for solving $k$-means and kernel $k$-means clustering problems on large datasets with small numbers of clusters. On the other hand, spectral clustering works well on sparse graphs and has recently been extended to scale efficiently to large numbers of clusters. We exploit the connection between kernel $k$-means and the normalised cut problem to combine the benefits of both. Our main result is a coreset spectral clustering algorithm for graphs that clusters a coreset graph to infer a good labelling of the original graph. We prove that an $\alpha$-approximation for the normalised cut problem on the coreset graph is an $O(\alpha)$-approximation on the original. We also improve the running time of the state-of-the-art coreset algorithm for kernel $k$-means on sparse kernels, from $\tilde{O}(nk)$ to $\tilde{O}(n\cdot \min \{k, d_{avg}\})$, where $d_{avg}$ is the average number of non-zero entries in each row of the $n\times n$ kernel matrix. Our experiments confirm our coreset algorithm is asymptotically faster on large real-world graphs with many clusters, and show that our clustering algorithm overcomes the main challenge faced by coreset kernel $k$-means on sparse kernels which is getting stuck in local optima.
Mini-Batch Kernel $k$-means
Oct 08, 2024



We present the first mini-batch kernel $k$-means algorithm, offering an order of magnitude improvement in running time compared to the full batch algorithm. A single iteration of our algorithm takes $\widetilde{O}(kb^2)$ time, significantly faster than the $O(n^2)$ time required by the full batch kernel $k$-means, where $n$ is the dataset size and $b$ is the batch size. Extensive experiments demonstrate that our algorithm consistently achieves a 10-100x speedup with minimal loss in quality, addressing the slow runtime that has limited kernel $k$-means adoption in practice. We further complement these results with a theoretical analysis under an early stopping condition, proving that with a batch size of $\widetilde{\Omega}(\max \{\gamma^{4}, \gamma^{2}\} \cdot \epsilon^{-2})$, the algorithm terminates in $O(\gamma^2/\epsilon)$ iterations with high probability, where $\gamma$ bounds the norm of points in feature space and $\epsilon$ is a termination threshold. Our analysis holds for any reasonable center initialization, and when using $k$-means++ initialization, the algorithm achieves an approximation ratio of $O(\log k)$ in expectation. For normalized kernels, such as Gaussian or Laplacian it holds that $\gamma=1$. Taking $\epsilon = O(1)$ and $b=\Theta(\log n)$, the algorithm terminates in $O(1)$ iterations, with each iteration running in $\widetilde{O}(k)$ time.