 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Computer Vision Interpretability: Transparent Two-level Classification for Complex Scenes
Jul 04, 2024
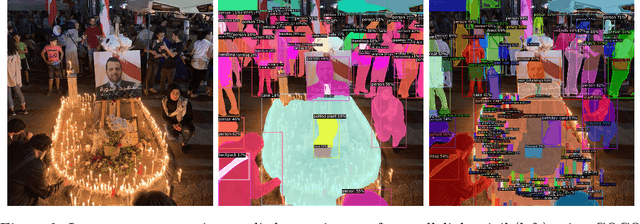

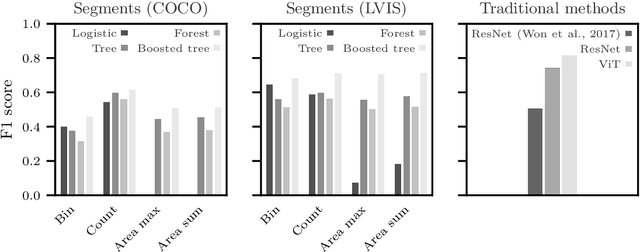
Treating images as data has become increasingly popular in political science. While existing classifiers for images reach high levels of accuracy, it is difficult to systematically assess the visual features on which they base their classification. This paper presents a two-level classification method that addresses this transparency problem. At the first stage, an image segmenter detects the objects present in the image and a feature vector is created from those objects. In the second stage, this feature vector is used as input for standard machine learning classifiers to discriminate between images. We apply this method to a new dataset of more than 140,000 images to detect which ones display political protest. This analysis demonstrates three advantages to this paper's approach. First, identifying objects in images improves transparency by providing human-understandable labels for the objects shown on an image. Second, knowing these objects enables analysis of which distinguish protest images from non-protest ones. Third, comparing the importance of objects across countries reveals how protest behavior varies. These insights are not available using conventional computer vision classifiers and provide new opportunities for comparative research.
AIR-Nets: An Attention-Based Framework for Locally Conditioned Implicit Representations
Oct 22, 2021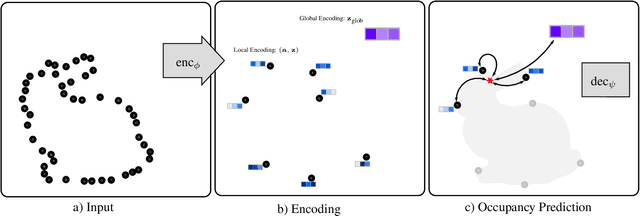
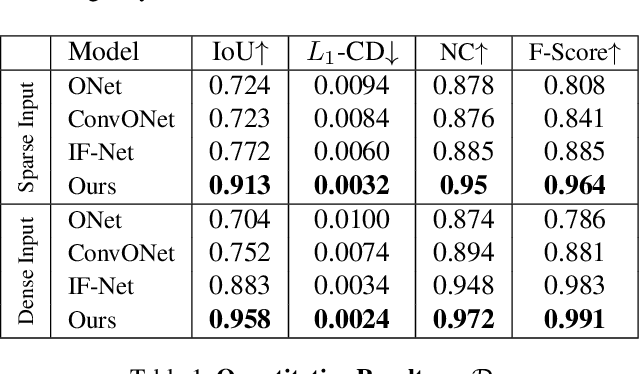
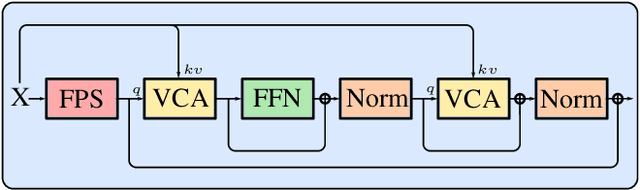
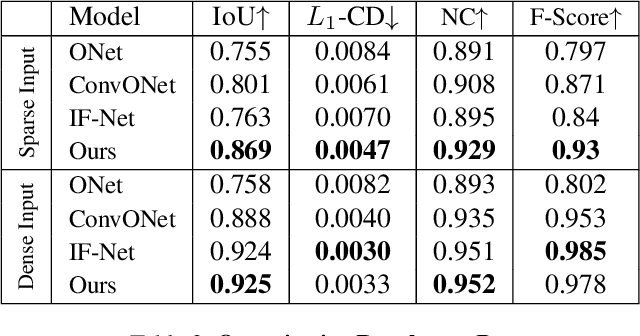
This paper introduces Attentive Implicit Representation Networks (AIR-Nets), a simple, but highly effective architecture for 3D reconstruction from point clouds. Since representing 3D shapes in a local and modular fashion increases generalization and reconstruction quality, AIR-Nets encode an input point cloud into a set of local latent vectors anchored in 3D space, which locally describe the object's geometry, as well as a global latent description, enforcing global consistency. Our model is the first grid-free, encoder-based approach that locally describes an implicit function. The vector attention mechanism from [Zhao et al. 2020] serves as main point cloud processing module, and allows for permutation invariance and translation equivariance. When queried with a 3D coordinate, our decoder gathers information from the global and nearby local latent vectors in order to predict an occupancy value. Experiments on the ShapeNet dataset show that AIR-Nets significantly outperform previous state-of-the-art encoder-based, implicit shape learning methods and especially dominate in the sparse setting. Furthermore, our model generalizes well to the FAUST dataset in a zero-shot setting. Finally, since AIR-Nets use a sparse latent representation and follow a simple operating scheme, the model offers several exiting avenues for future work. Our code is available at https://github.com/SimonGiebenhain/AIR-Nets.