 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIR-Nets: An Attention-Based Framework for Locally Conditioned Implicit Representations
Paper and Code
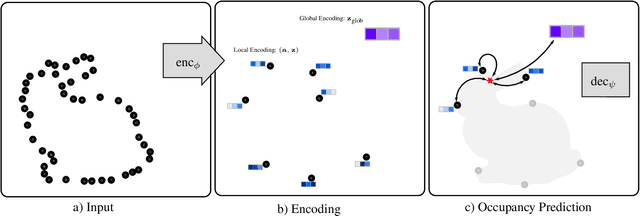
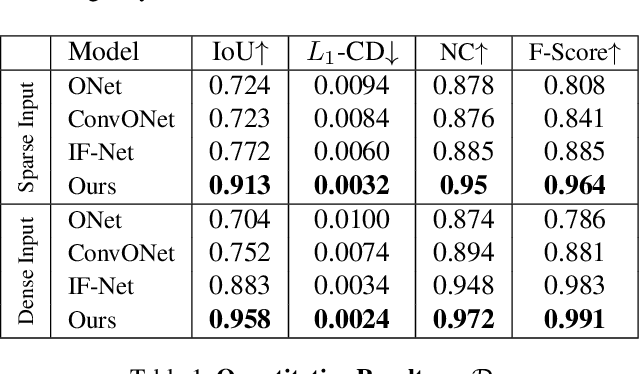
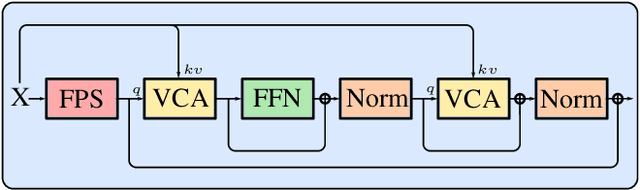
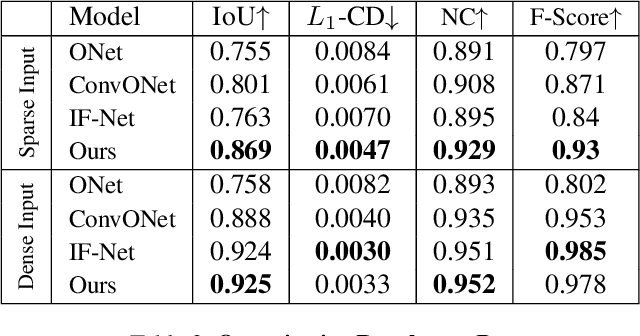
This paper introduces Attentive Implicit Representation Networks (AIR-Nets), a simple, but highly effective architecture for 3D reconstruction from point clouds. Since representing 3D shapes in a local and modular fashion increases generalization and reconstruction quality, AIR-Nets encode an input point cloud into a set of local latent vectors anchored in 3D space, which locally describe the object's geometry, as well as a global latent description, enforcing global consistency. Our model is the first grid-free, encoder-based approach that locally describes an implicit function. The vector attention mechanism from [Zhao et al. 2020] serves as main point cloud processing module, and allows for permutation invariance and translation equivariance. When queried with a 3D coordinate, our decoder gathers information from the global and nearby local latent vectors in order to predict an occupancy value. Experiments on the ShapeNet dataset show that AIR-Nets significantly outperform previous state-of-the-art encoder-based, implicit shape learning methods and especially dominate in the sparse setting. Furthermore, our model generalizes well to the FAUST dataset in a zero-shot setting. Finally, since AIR-Nets use a sparse latent representation and follow a simple operating scheme, the model offers several exiting avenues for future work. Our code is available at https://github.com/SimonGiebenhain/AIR-Nets.