 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualitative Evaluation of LLM-Designed GUI
Jan 30, 2026As generative artificial intelligence advances, Large Language Models (LLMs) are being explored for automated graphical user interface (GUI) design. This study investigates the usability and adaptability of LLM-generated interfaces by analysing their ability to meet diverse user needs. The experiments included utilization of three state-of-the-art models from January 2025 (OpenAI GPT o3-mini-high, DeepSeek R1, and Anthropic Claude 3.5 Sonnet) generating mockups for three interface types: a chat system, a technical team panel, and a manager dashboard. Expert evaluations revealed that while LLMs are effective at creating structured layouts, they face challenges in meeting accessibility standards and providing interactive functionality. Further testing showed that LLMs could partially tailor interfaces for different user personas but lacked deeper contextual understanding. The results suggest that while LLMs are promising tools for early-stage UI prototyping, human intervention remains critical to ensure usability, accessibility, and user satisfaction.
Towards the Ultimate Programming Language: Trust and Benevolence in the Age of Artificial Intelligence
Nov 29, 2024This article explores the evolving role of programming languages in the context of artificial intelligence. It highlights the need for programming languages to ensure human understanding while eliminating unnecessary implementation details and suggests that future programs should be designed to recognize and actively support user interests. The vision includes a three-level process: using natural language for requirements, translating it into a precise system definition language, and finally optimizing the code for performance. The concept of an "Ultimate Programming Language" is introduced, emphasizing its role in maintaining human control over machines. Trust, reliability, and benevolence are identified as key elements that will enhance cooperation between humans and AI systems.
NormEnsembleXAI: Unveiling the Strengths and Weaknesses of XAI Ensemble Techniques
Jan 30, 2024This paper presents a comprehensive comparative analysis of explainable artificial intelligence (XAI) ensembling methods. Our research brings three significant contributions. Firstly, we introduce a novel ensembling method, NormEnsembleXAI, that leverages minimum, maximum, and average functions in conjunction with normalization techniques to enhance interpretability. Secondly, we offer insights into the strengths and weaknesses of XAI ensemble methods. Lastly, we provide a library, facilitating the practical implementation of XAI ensembling, thus promoting the adoption of transparent and interpretable deep learning models.
Two-Step Reinforcement Learning for Multistage Strategy Card Game
Nov 29, 2023In the realm of artificial intelligence and card games, this study introduces a two-step reinforcement learning (RL) strategy tailored for "The Lord of the Rings: The Card Game (LOTRCG)," a complex multistage strategy card game. This research diverges from conventional RL methods by adopting a phased learning approach, beginning with a foundational learning stage in a simplified version of the game and subsequently progressing to the complete, intricate game environment. This methodology notably enhances the AI agent's adaptability and performance in the face of LOTRCG's unpredictable and challenging nature. The paper also explores a multi-agent system, where distinct RL agents are employed for various decision-making aspects of the game. This approach has demonstrated a remarkable improvement in game outcomes, with the RL agents achieving a winrate of 78.5% across a set of 10,000 random games.
Optimisation of MCTS Player for The Lord of the Rings: The Card Game
Sep 24, 2021
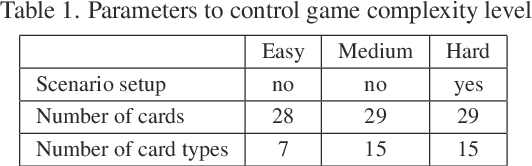
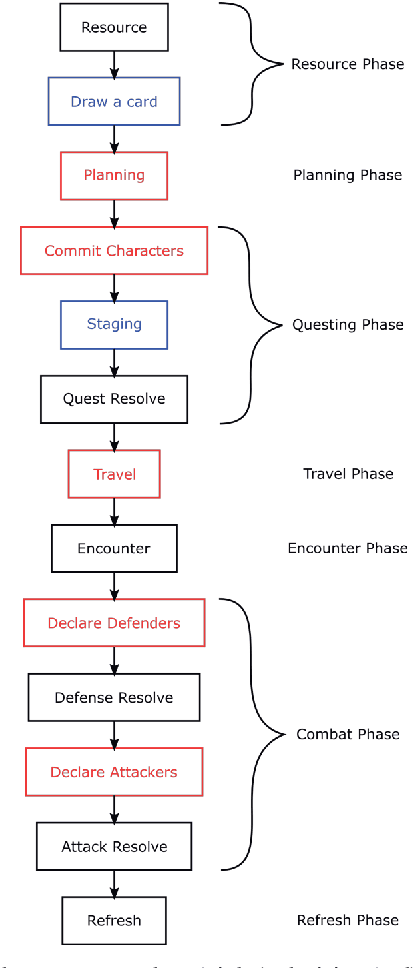
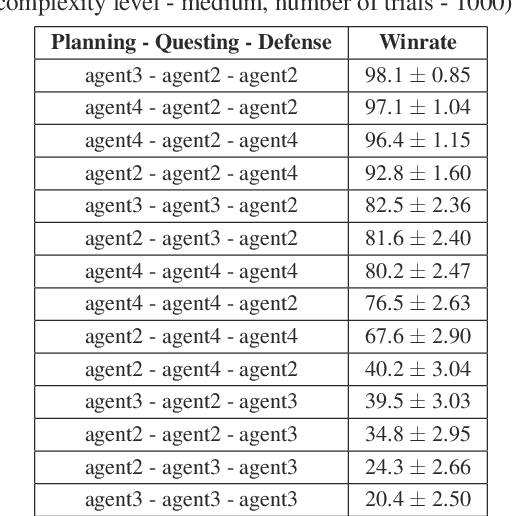
The article presents research on the use of Monte-Carlo Tree Search (MCTS) methods to create an artificial player for the popular card game "The Lord of the Rings". The game is characterized by complicated rules, multi-stage round construction, and a high level of randomness. The described study found that the best probability of a win is received for a strategy combining expert knowledge-based agents with MCTS agents at different decision stages. It is also beneficial to replace random playouts with playouts using expert knowledge. The results of the final experiments indicate that the relative effectiveness of the developed solution grows as the difficulty of the game increases.
MCTS Based Agents for Multistage Single-Player Card Game
Sep 24, 2021



The article presents the use of Monte Carlo Tree Search algorithms for the card game Lord of the Rings. The main challenge was the complexity of the game mechanics, in which each round consists of 5 decision stages and 2 random stages. To test various decision-making algorithms, a game simulator has been implemented. The research covered an agent based on expert rules, using flat Monte-Carlo search, as well as complete MCTS-UCB. Moreover different playout strategies has been compared. As a result of experiments, an optimal (assuming a limited time) combination of algorithms were formulated. The developed MCTS based method have demonstrated a advantage over agent with expert knowledge.
Monte Carlo Tree Search: A Review of Recent Modifications and Applications
Mar 09, 2021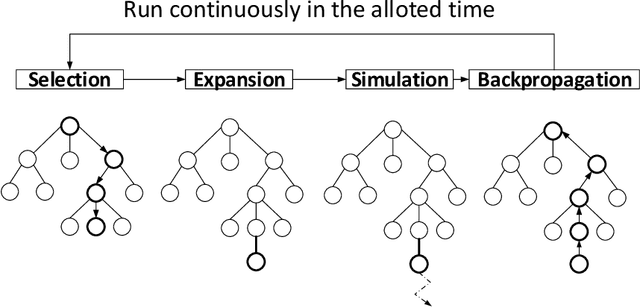
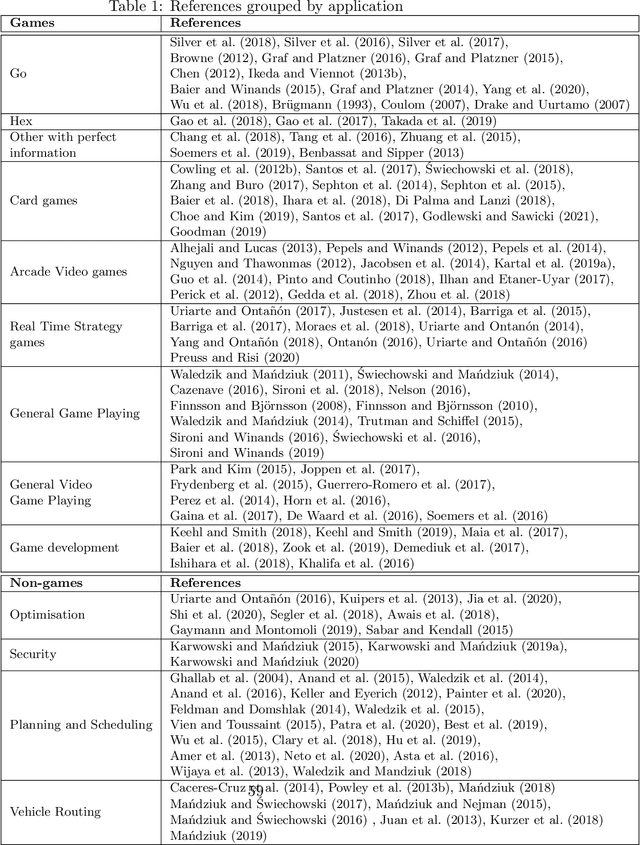
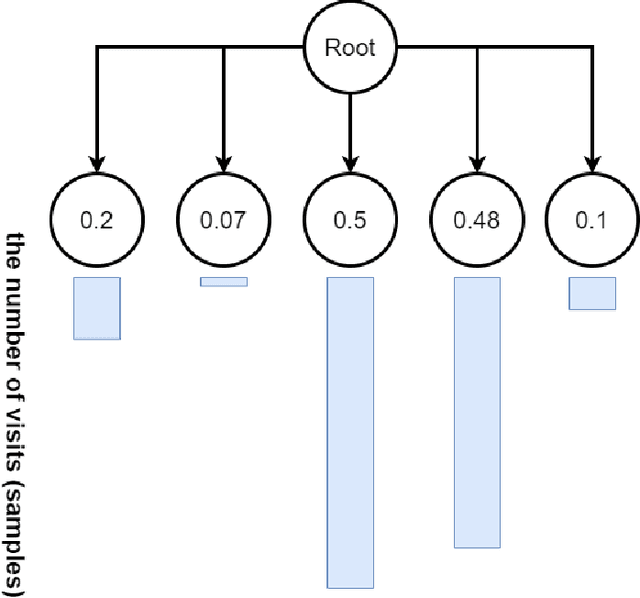
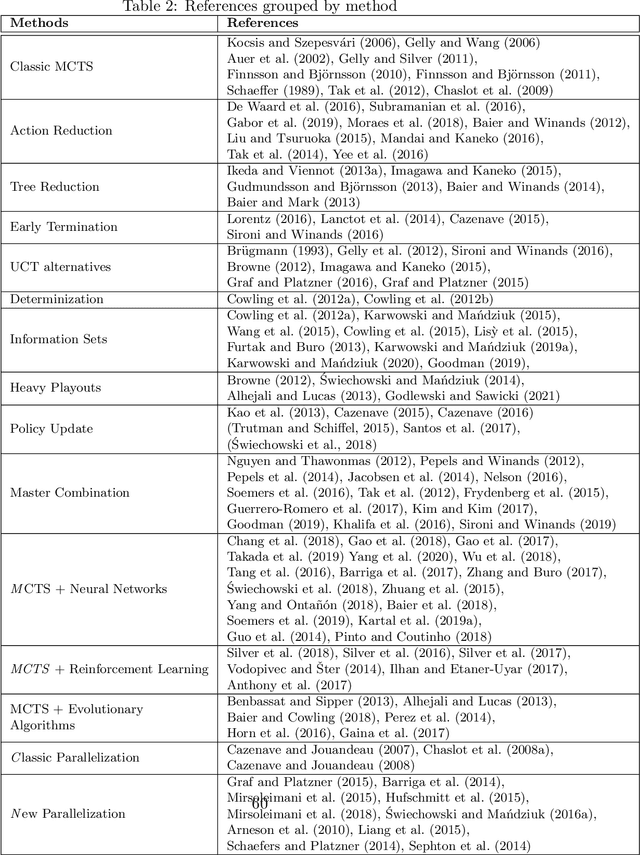
Monte Carlo Tree Search (MCTS) is a powerful approach to designing game-playing bots or solving sequential decision problems. The method relies on intelligent tree search that balances exploration and exploitation. MCTS performs random sampling in the form of simulations and stores statistics of actions to make more educated choices in each subsequent iteration. The method has become a state-of-the-art technique for combinatorial games, however, in more complex games (e.g. those with high branching factor or real-time ones), as well as in various practical domains (e.g. transportation, scheduling or security) an efficient MCTS application often requires its problem-dependent modification or integration with other techniques. Such domain-specific modifications and hybrid approaches are the main focus of this survey. The last major MCTS survey has been published in 2012. Contributions that appeared since its release are of particular interest for this review.