 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensions of Interpersonal Dynamics in Text: Group Membership and Fine-grained Interpersonal Emotion
Sep 14, 2022
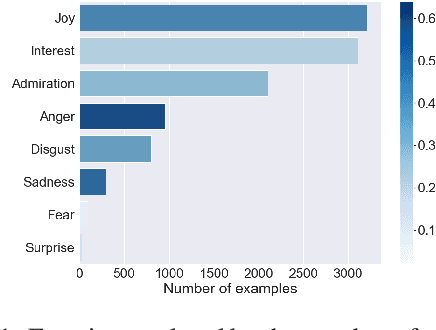
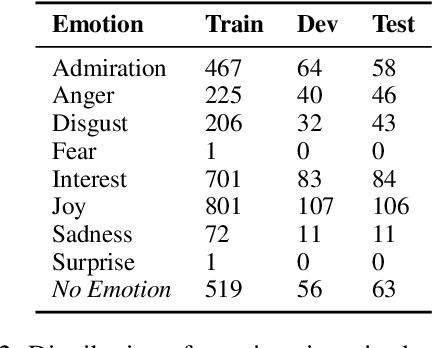
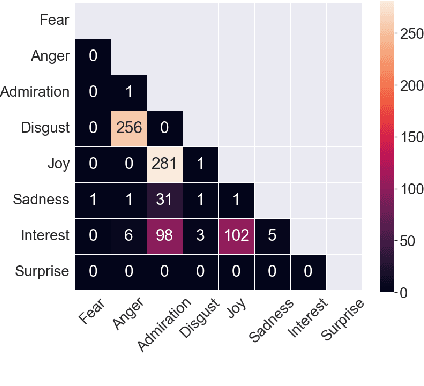
The ability of language to perpetuate inequality is most evident when individuals refer to, or talk about, other individuals in their utterances. While current studies of bias in NLP rely mainly on identifying hate speech or bias towards a specific group, we believe we can reach a more subtle and nuanced understanding of the interaction between bias and language use by modeling the speaker, the text, and the target in the text. In this paper, we introduce a dataset of 3033 English tweets by US Congress members annotated for interpersonal emotion, and `found supervision' for interpersonal group membership labels. We find that negative emotions such as anger and disgust are used predominantly in out-group situations, and directed predominantly at leaders of opposite parties. While humans can perform better than chance at identifying interpersonal group membership given an utterance, neural models perform much better; furthermore, a shared encoding between interpersonal group membership and interpersonal perceived emotion enabled some performance gains in the latter. This work aims to re-align the study of bias in NLP away from specific instances of bias to one which encapsulates the relationship between speaker, text, target and social dynamics. Data and code for this paper are available at https://github.com/venkatasg/Interpersonal-Dynamics
Political Ideology and Polarization of Policy Positions: A Multi-dimensional Approach
Jun 28, 2021
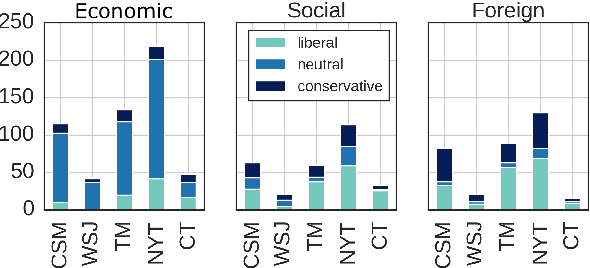
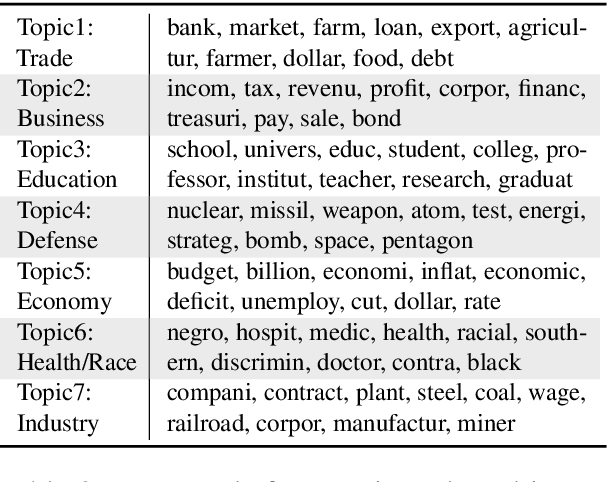
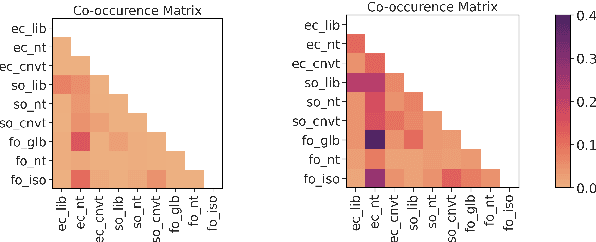
Analyzing political ideology and polarization is of critical importance in advancing our understanding of the political context in society. Recent research has made great strides towards understanding the ideological bias (i.e., stance) of news media along a left-right spectrum. In this work, we take a novel approach and study the ideology of the policy under discussion teasing apart the nuanced co-existence of stance and ideology. Aligned with the theoretical accounts in political science, we treat ideology as a multi-dimensional construct, and introduce the first diachronic dataset of news articles whose political ideology under discussion is annotated by trained political scientists and linguists at the paragraph-level. We showcase that this framework enables quantitative analysis of polarization, a temporal, multifaceted measure of ideological distance. We further present baseline models for ideology prediction.
Adaptive Ensembling: Unsupervised Domain Adaptation for Political Document Analysis
Oct 28, 2019
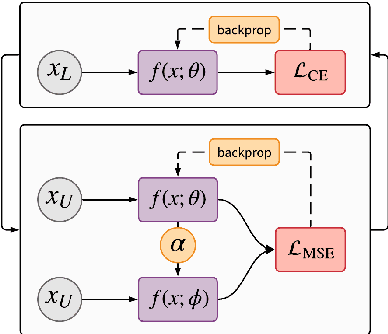

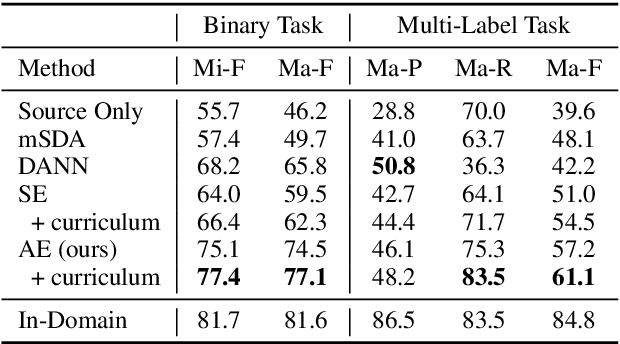
Insightful findings in political science often require researchers to analyze documents of a certain subject or type, yet these documents are usually contained in large corpora that do not distinguish between pertinent and non-pertinent documents. In contrast, we can find corpora that label relevant documents but have limitations (e.g., from a single source or era), preventing their use for political science research. To bridge this gap, we present \textit{adaptive ensembling}, an unsupervised domain adaptation framework, equipped with a novel text classification model and time-aware training to ensure our methods work well with diachronic corpora. Experiments on an expert-annotated dataset show that our framework outperforms strong benchmarks. Further analysis indicates that our methods are more stable, learn better representations, and extract cleaner corpora for fine-grained analysis.