 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher Resolution, Better Generalization: Unlocking Visual Scaling in Deep Reinforcement Learning
May 11, 2026Pixel-based deep reinforcement learning agents are typically trained on heavily downsampled visual observations, a convention inherited from early benchmarks rather than grounded in principled design. In this work, we show that observation resolution is a critical yet overlooked variable for policy learning: higher-resolution inputs can substantially improve both performance and generalization, provided the network architecture can process them effectively. We find that the widely used Impala encoder, which flattens spatial features into a vector, suffers from quadratic parameter growth as resolution increases and fails to leverage the additional visual detail. Replacing this operation with global average pooling, as in the Impoola architecture, decouples parameter count from resolution and yields consistent improvements across resolutions and network widths - at their respective best conditions, visual scaling unlocks a 28 % performance gain for Impoola over Impala. These gains are strongest in environments that require precise perception of small or distant objects, and gradient saliency analysis confirms that the underlying mechanism is a more spatially localized visual attention of the policy at higher resolutions. Our results challenge the prevailing practice of aggressive input downsampling and position resolution-independent architectures as a simple, effective path toward scalable visual deep RL. To facilitate future research on resolution scaling in deep RL, we publicly release the open-source code for the Procgen-HD benchmark: https://github.com/raphajaner/procgen-hd.
Clipping-Free Policy Optimization for Large Language Models
Jan 30, 2026Reinforcement learning has become central to post-training large language models, yet dominant algorithms rely on clipping mechanisms that introduce optimization issues at scale, including zero-gradient regions, reward hacking, and training instability. We propose Clipping-Free Policy Optimization (CFPO), which replaces heuristic clipping with a convex quadratic penalty derived from Total Variation divergence constraints, yielding an everywhere-differentiable objective that enforces stable policy updates without hard boundaries. We evaluate CFPO across both reasoning and alignment settings. In reasoning, CFPO matches clipping-based methods on downstream benchmarks while extending the stable training regime. In alignment, CFPO mitigates verbosity exploitation and reduces capability degradation, while achieving competitive instruction-following performance. CFPO requires only a one-line code change and no additional hyperparameters. Our results suggest that CFPO is a promising drop-in alternative to clipping-based methods for LLM post-training.
Uncovering RL Integration in SSL Loss: Objective-Specific Implications for Data-Efficient RL
Oct 22, 2024In this study, we investigate the effect of SSL objective modifications within the SPR framework, focusing on specific adjustments such as terminal state masking and prioritized replay weighting, which were not explicitly addressed in the original design. While these modifications are specific to RL, they are not universally applicable across all RL algorithms. Therefore, we aim to assess their impact on performance and explore other SSL objectives that do not accommodate these adjustments like Barlow Twins and VICReg. We evaluate six SPR variants on the Atari 100k benchmark, including versions both with and without these modifications. Additionally, we test the performance of these objectives on the DeepMind Control Suite, where such modifications are absent. Our findings reveal that incorporating specific SSL modifications within SPR significantly enhances performance, and this influence extends to subsequent frameworks like SR-SPR and BBF, highlighting the critical importance of SSL objective selection and related adaptations in achieving data efficiency in self-predictive reinforcement learning.
Privileged to Predicted: Towards Sensorimotor Reinforcement Learning for Urban Driving
Sep 18, 2023Reinforcement Learning (RL) has the potential to surpass human performance in driving without needing any expert supervision. Despite its promise, the state-of-the-art in sensorimotor self-driving is dominated by imitation learning methods due to the inherent shortcomings of RL algorithms. Nonetheless, RL agents are able to discover highly successful policies when provided with privileged ground truth representations of the environment. In this work, we investigate what separates privileged RL agents from sensorimotor agents for urban driving in order to bridge the gap between the two. We propose vision-based deep learning models to approximate the privileged representations from sensor data. In particular, we identify aspects of state representation that are crucial for the success of the RL agent such as desired route generation and stop zone prediction, and propose solutions to gradually develop less privileged RL agents. We also observe that bird's-eye-view models trained on offline datasets do not generalize to online RL training due to distribution mismatch. Through rigorous evaluation on the CARLA simulation environment, we shed light on the significance of the state representations in RL for autonomous driving and point to unresolved challenges for future research.
FLAGS Framework for Comparative Analysis of Federated Learning Algorithms
Dec 14, 2022Federated Learning (FL) has become a key choice for distributed machine learning. Initially focused on centralized aggregation, recent works in FL have emphasized greater decentralization to adapt to the highly heterogeneous network edge. Among these, Hierarchical, Device-to-Device and Gossip Federated Learning (HFL, D2DFL \& GFL respectively) can be considered as foundational FL algorithms employing fundamental aggregation strategies. A number of FL algorithms were subsequently proposed employing multiple fundamental aggregation schemes jointly. Existing research, however, subjects the FL algorithms to varied conditions and gauges the performance of these algorithms mainly against Federated Averaging (FedAvg) only. This work consolidates the FL landscape and offers an objective analysis of the major FL algorithms through a comprehensive cross-evaluation for a wide range of operating conditions. In addition to the three foundational FL algorithms, this work also analyzes six derived algorithms. To enable a uniform assessment, a multi-FL framework named FLAGS: Federated Learning AlGorithms Simulation has been developed for rapid configuration of multiple FL algorithms. Our experiments indicate that fully decentralized FL algorithms achieve comparable accuracy under multiple operating conditions, including asynchronous aggregation and the presence of stragglers. Furthermore, decentralized FL can also operate in noisy environments and with a comparably higher local update rate. However, the impact of extremely skewed data distributions on decentralized FL is much more adverse than on centralized variants. The results indicate that it may not be necessary to restrict the devices to a single FL algorithm; rather, multi-FL nodes may operate with greater efficiency.
* 39 pages, 10 figures. Accepted for publication in Elsevier 'Internet of Things'
State-of-the-art Techniques in Deep Edge Intelligence
Aug 04, 2020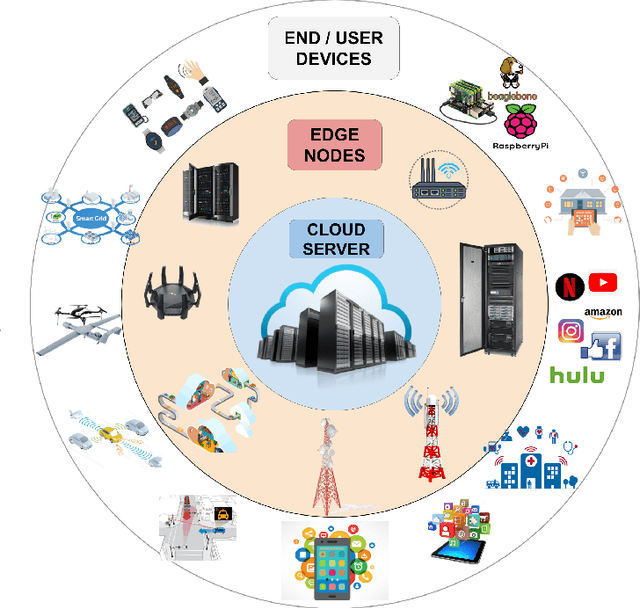
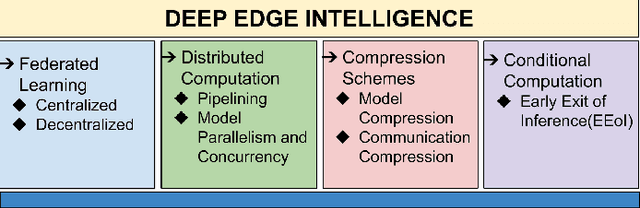
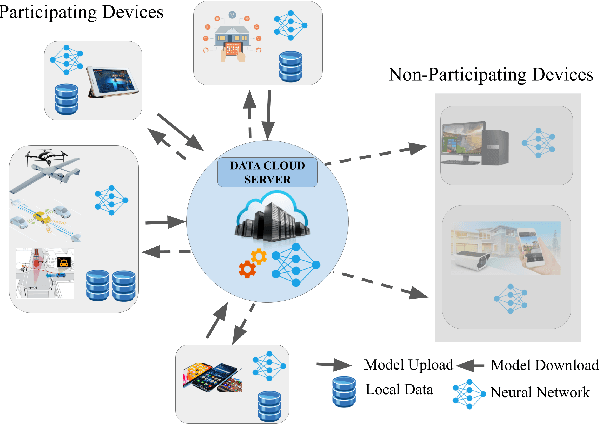
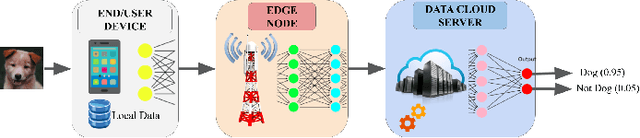
The potential held by the gargantuan volumes of data being generated across networks worldwide has been truly unlocked by machine learning techniques and more recently Deep Learning. The advantages offered by the latter have seen it rapidly becoming a framework of choice for various applications. However, the centralization of computational resources and the need for data aggregation have long been limiting factors in the democratization of Deep Learning applications. Edge Computing is an emerging paradigm that aims to utilize the hitherto untapped processing resources available at the network periphery. Edge Intelligence (EI) has quickly emerged as a powerful alternative to enable learning using the concepts of Edge Computing. Deep Learning-based Edge Intelligence or Deep Edge Intelligence (DEI) lies in this rapidly evolving domain. In this article, we provide an overview of the major constraints in operationalizing DEI. The major research avenues in DEI have been consolidated under Federated Learning, Distributed Computation, Compression Schemes and Conditional Computation. We also present some of the prevalent challenges and highlight prospective research avenues.
Flow From Motion: A Deep Learning Approach
Mar 26, 2018



Wearable devices have the potential to enhance sports performance, yet they are not fulfilling this promise. Our previous studies with 6 professional tennis coaches and 20 players indicate that this could be due the lack of psychological or mental state feedback, which the coaches claim to provide. Towards this end, we propose to detect the flow state, mental state of optimal performance, using wearables data to be later used in training. We performed a study with a professional tennis coach and two players. The coach provided labels about the players' flow state while each player had a wearable device on their racket holding wrist. We trained multiple models using the wearables data and the coach labels. Our deep neural network models achieved around 98% testing accuracy for a variety of conditions. This suggests that the flow state or what coaches recognize as flow, can be detected using wearables data in tennis which is a novel result. The implication for the HCI community is that having access to such information would allow for design of novel hardware and interaction paradigms that would be helpful in professional athlete training.