 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging vision language model (VLM) evaluation gaps with a framework for scalable and cost-effective benchmark generation
Feb 21, 2025
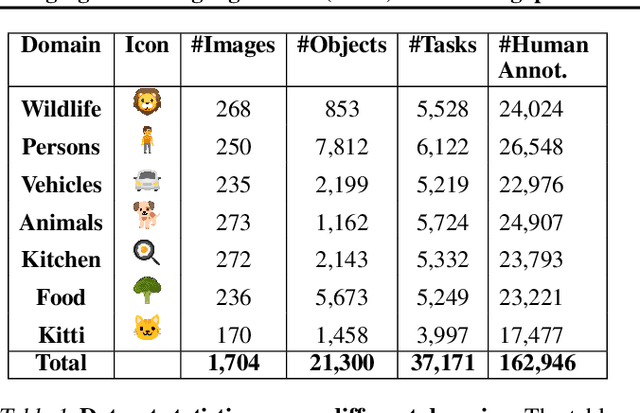
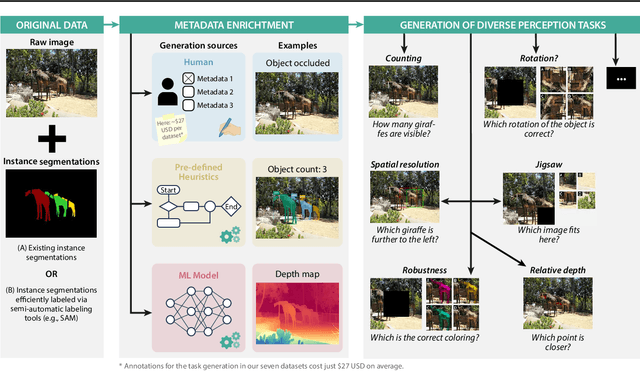
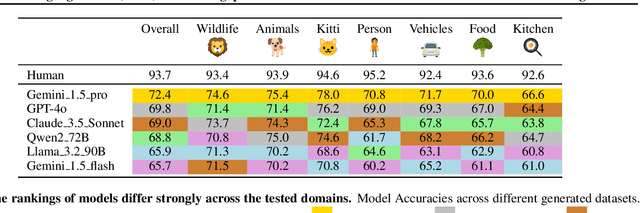
Reliable evaluation of AI models is critical for scientific progress and practical application. While existing VLM benchmarks provide general insights into model capabilities, their heterogeneous designs and limited focus on a few imaging domains pose significant challenges for both cross-domain performance comparison and targeted domain-specific evaluation. To address this, we propose three key contributions: (1) a framework for the resource-efficient creation of domain-specific VLM benchmarks enabled by task augmentation for creating multiple diverse tasks from a single existing task, (2) the release of new VLM benchmarks for seven domains, created according to the same homogeneous protocol and including 162,946 thoroughly human-validated answers, and (3) an extensive benchmarking of 22 state-of-the-art VLMs on a total of 37,171 tasks, revealing performance variances across domains and tasks, thereby supporting the need for tailored VLM benchmarks. Adoption of our methodology will pave the way for the resource-efficient domain-specific selection of models and guide future research efforts toward addressing core open questions.