 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRH-Net: A Multi-Level Knowledge Distillation Approach for Low-Resource Heart Network
Apr 11, 2022
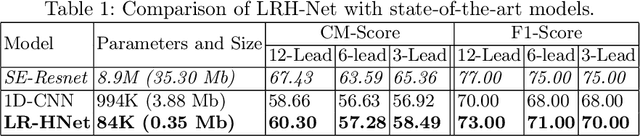
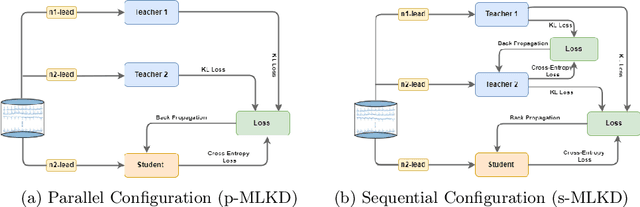
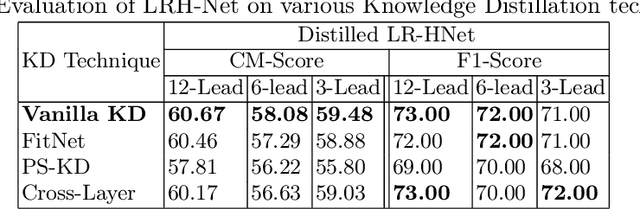
An electrocardiogram (ECG) monitors the electrical activity generated by the heart and is used to detect fatal cardiovascular diseases (CVDs). Conventionally, to capture the precise electrical activity, clinical experts use multiple-lead ECGs (typically 12 leads). But in recent times, large-size deep learning models have been used to detect these diseases. However, such models require heavy compute resources like huge memory and long inference time. To alleviate these shortcomings, we propose a low-parameter model, named Low Resource Heart-Network (LRH-Net), which uses fewer leads to detect ECG anomalies in a resource-constrained environment. A multi-level knowledge distillation process is used on top of that to get better generalization performance on our proposed model. The multi-level knowledge distillation process distills the knowledge to LRH-Net trained on a reduced number of leads from higher parameter (teacher) models trained on multiple leads to reduce the performance gap. The proposed model is evaluated on the PhysioNet-2020 challenge dataset with constrained input. The parameters of the LRH-Net are 106x less than our teacher model for detecting CVDs. The performance of the LRH-Net was scaled up to 3.2% and the inference time scaled down by 75% compared to the teacher model. In contrast to the compute- and parameter-intensive deep learning techniques, the proposed methodology uses a subset of ECG leads using the low resource LRH-Net, making it eminently suitable for deployment on edge devices.
Value-of-Information based Arbitration between Model-based and Model-free Control
Dec 08, 2019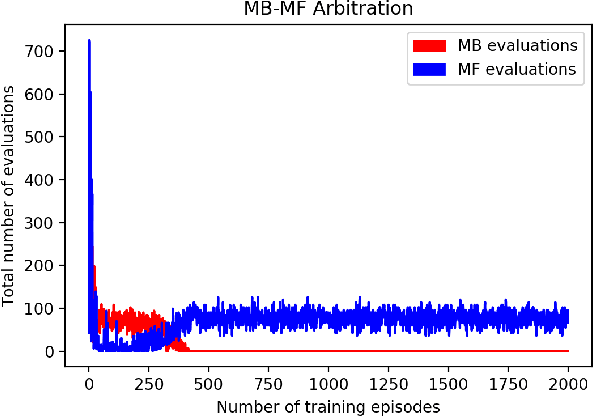
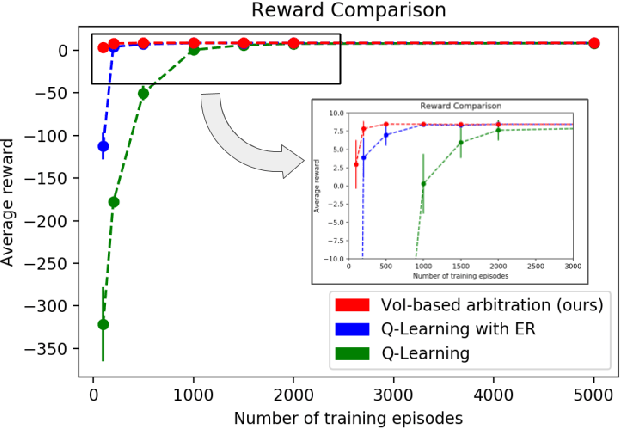
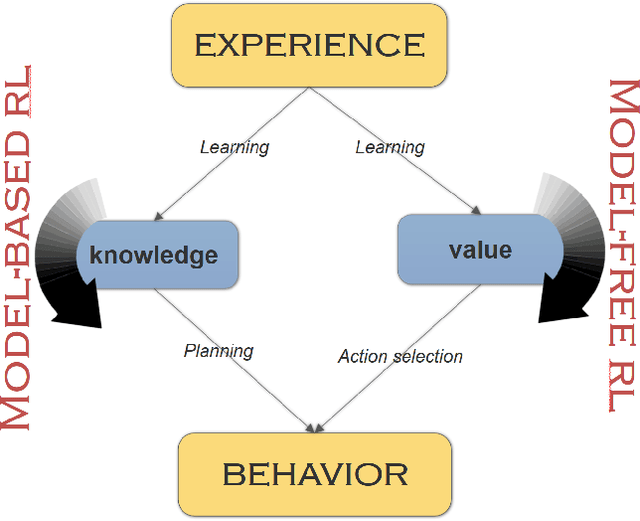
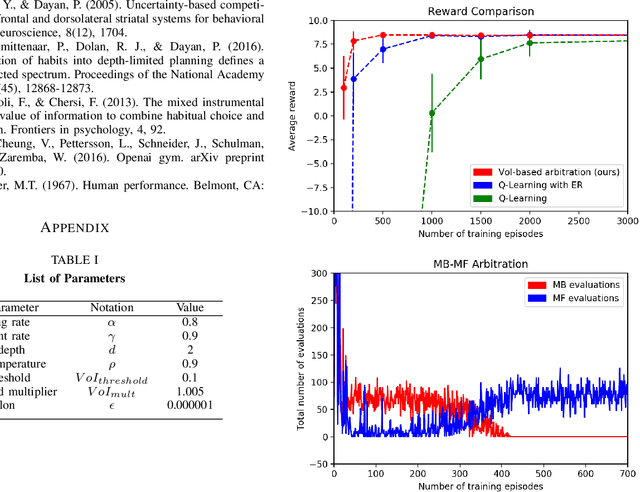
There have been numerous attempts in explaining the general learning behaviours using model-based and model-free methods. While the model-based control is flexible yet computationally expensive in planning, the model-free control is quick but inflexible. The model-based control is therefore immune from reward devaluation and contingency degradation. Multiple arbitration schemes have been suggested to achieve the data efficiency and computational efficiency of model-based and model-free control respectively. In this context, we propose a quantitative 'value of information' based arbitration between both the controllers in order to establish a general computational framework for skill learning. The interacting model-based and model-free reinforcement learning processes are arbitrated using an uncertainty-based value of information. We further show that our algorithm performs better than Q-learning as well as Q-learning with experience replay.
A Computational Framework for Motor Skill Acquisition
Jan 03, 2019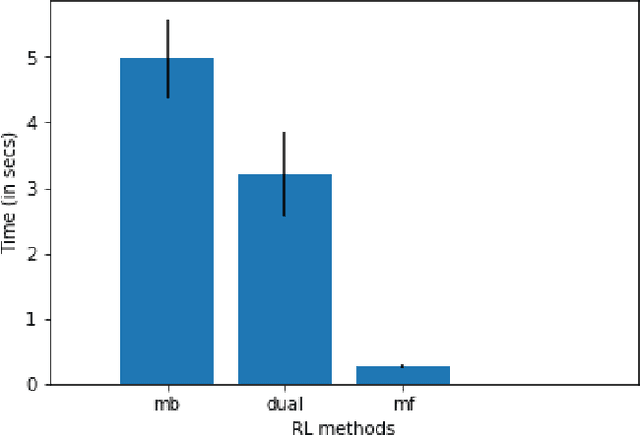
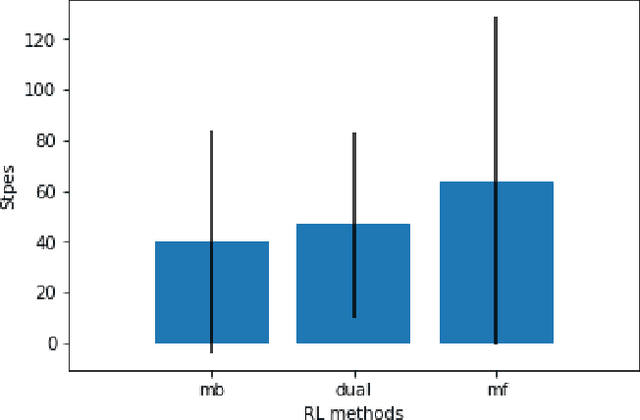
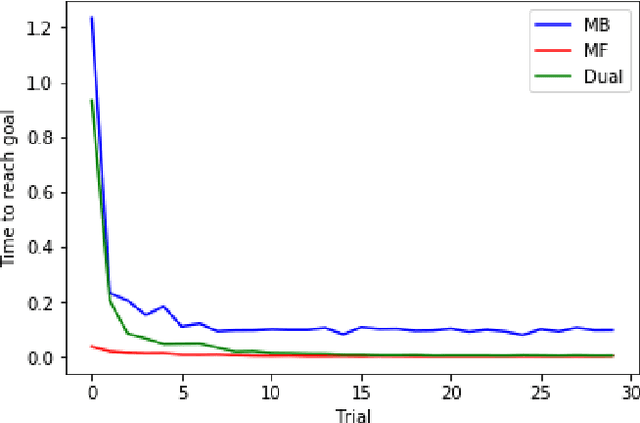
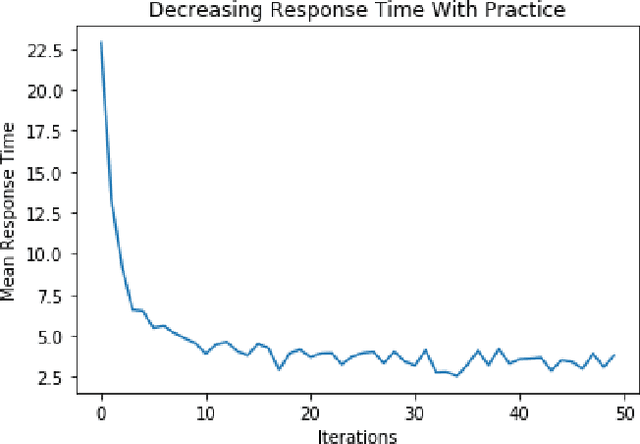
There have been numerous attempts in explaining the general learning behaviours by various cognitive models. Multiple hypotheses have been put further to qualitatively argue the best-fit model for motor skill acquisition task and its variations. In this context, for a discrete sequence production (DSP) task, one of the most insightful models is Verwey's Dual Processor Model (DPM). It largely explains the learning and behavioural phenomenon of skilled discrete key-press sequences without providing any concrete computational basis of reinforcement. Therefore, we propose a quantitative explanation for Verwey's DPM hypothesis by experimentally establishing a general computational framework for motor skill learning. We attempt combining the qualitative and quantitative theories based on a best-fit model of the experimental simulations of variations of dual processor models. The fundamental premise of sequential decision making for skill learning is based on interacting model-based (MB) and model-free (MF) reinforcement learning (RL) processes. Our unifying framework shows the proposed idea agrees well to Verwey's DPM and Fitts' three phases of skill learning. The accuracy of our model can further be validated by its statistical fit with the human-generated data on simple environment tasks like the grid-world.