 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian autoencoders with uncertainty quantification: Towards trustworthy anomaly detection
Feb 25, 2022



Despite numerous studies of deep autoencoders (AEs) for unsupervised anomaly detection, AEs still lack a way to express uncertainty in their predictions, crucial for ensuring safe and trustworthy machine learning systems in high-stake applications. Therefore, in this work, the formulation of Bayesian autoencoders (BAEs) is adopted to quantify the total anomaly uncertainty, comprising epistemic and aleatoric uncertainties. To evaluate the quality of uncertainty, we consider the task of classifying anomalies with the additional option of rejecting predictions of high uncertainty. In addition, we use the accuracy-rejection curve and propose the weighted average accuracy as a performance metric. Our experiments demonstrate the effectiveness of the BAE and total anomaly uncertainty on a set of benchmark datasets and two real datasets for manufacturing: one for condition monitoring, the other for quality inspection.
Do autoencoders need a bottleneck for anomaly detection?
Feb 25, 2022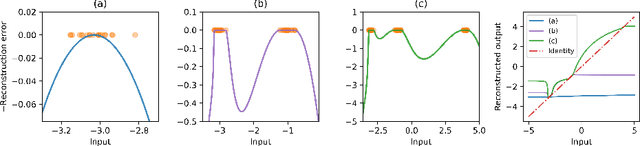
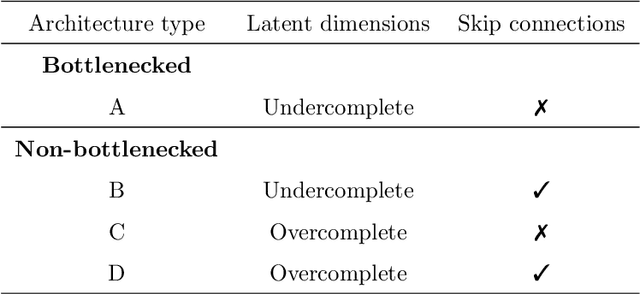


A common belief in designing deep autoencoders (AEs), a type of unsupervised neural network, is that a bottleneck is required to prevent learning the identity function. Learning the identity function renders the AEs useless for anomaly detection. In this work, we challenge this limiting belief and investigate the value of non-bottlenecked AEs. The bottleneck can be removed in two ways: (1) overparameterising the latent layer, and (2) introducing skip connections. However, limited works have reported on the use of one of the ways. For the first time, we carry out extensive experiments covering various combinations of bottleneck removal schemes, types of AEs and datasets. In addition, we propose the infinitely-wide AEs as an extreme example of non-bottlenecked AEs. Their improvement over the baseline implies learning the identity function is not trivial as previously assumed. Moreover, we find that non-bottlenecked architectures (highest AUROC=0.857) can outperform their bottlenecked counterparts (highest AUROC=0.696) on the popular task of CIFAR (inliers) vs SVHN (anomalies), among other tasks, shedding light on the potential of developing non-bottlenecked AEs for improving anomaly detection.
Coalitional Bayesian Autoencoders -- Towards explainable unsupervised deep learning
Oct 19, 2021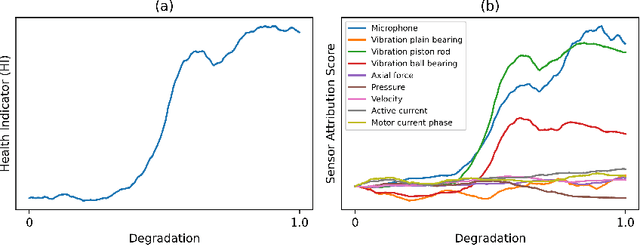

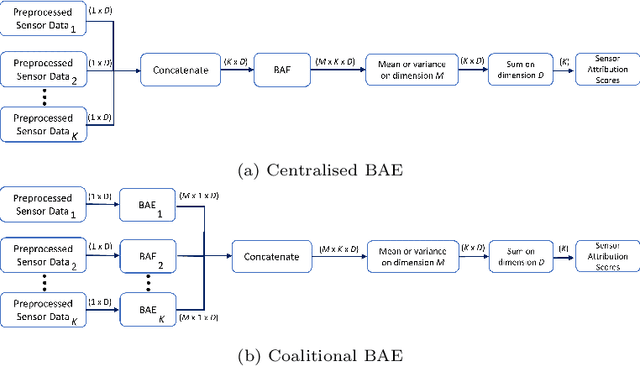

This paper aims to improve the explainability of Autoencoder's (AE) predictions by proposing two explanation methods based on the mean and epistemic uncertainty of log-likelihood estimate, which naturally arise from the probabilistic formulation of the AE called Bayesian Autoencoders (BAE). To quantitatively evaluate the performance of explanation methods, we test them in sensor network applications, and propose three metrics based on covariate shift of sensors : (1) G-mean of Spearman drift coefficients, (2) G-mean of sensitivity-specificity of explanation ranking and (3) sensor explanation quality index (SEQI) which combines the two aforementioned metrics. Surprisingly, we find that explanations of BAE's predictions suffer from high correlation resulting in misleading explanations. To alleviate this, a "Coalitional BAE" is proposed, which is inspired by agent-based system theory. Our comprehensive experiments on publicly available condition monitoring datasets demonstrate the improved quality of explanations using the Coalitional BAE.
Bayesian Autoencoders: Analysing and Fixing the Bernoulli likelihood for Out-of-Distribution Detection
Jul 28, 2021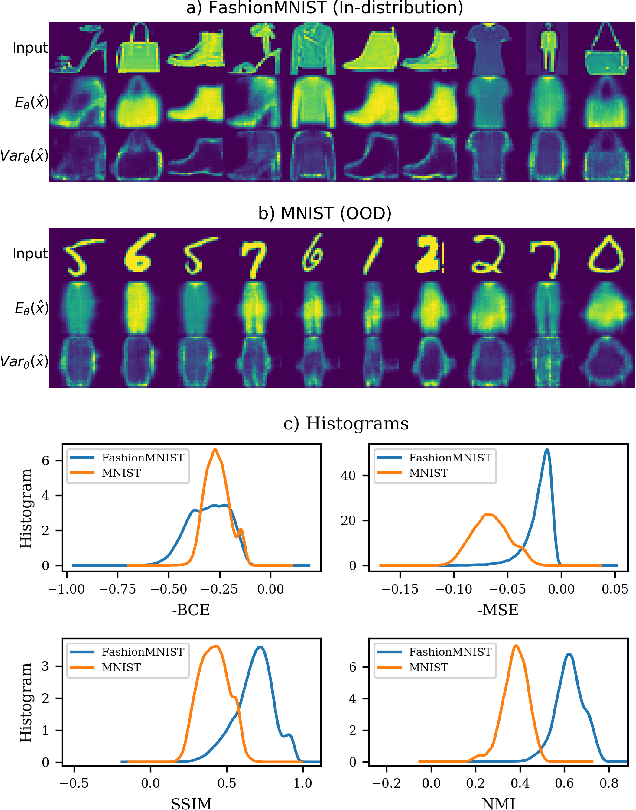
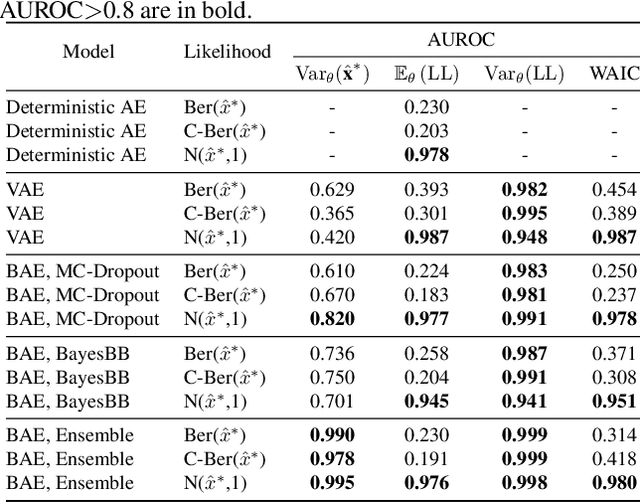
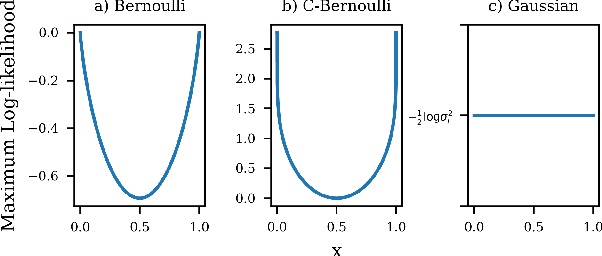
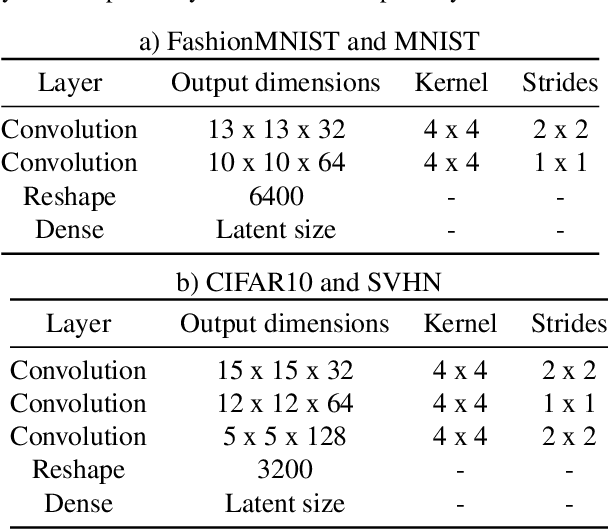
After an autoencoder (AE) has learnt to reconstruct one dataset, it might be expected that the likelihood on an out-of-distribution (OOD) input would be low. This has been studied as an approach to detect OOD inputs. Recent work showed this intuitive approach can fail for the dataset pairs FashionMNIST vs MNIST. This paper suggests this is due to the use of Bernoulli likelihood and analyses why this is the case, proposing two fixes: 1) Compute the uncertainty of likelihood estimate by using a Bayesian version of the AE. 2) Use alternative distributions to model the likelihood.
Multi Agent System for Machine Learning Under Uncertainty in Cyber Physical Manufacturing System
Jul 28, 2021



Recent advancements in predictive machine learning has led to its application in various use cases in manufacturing. Most research focused on maximising predictive accuracy without addressing the uncertainty associated with it. While accuracy is important, focusing primarily on it poses an overfitting danger, exposing manufacturers to risk, ultimately hindering the adoption of these techniques. In this paper, we determine the sources of uncertainty in machine learning and establish the success criteria of a machine learning system to function well under uncertainty in a cyber-physical manufacturing system (CPMS) scenario. Then, we propose a multi-agent system architecture which leverages probabilistic machine learning as a means of achieving such criteria. We propose possible scenarios for which our proposed architecture is useful and discuss future work. Experimentally, we implement Bayesian Neural Networks for multi-tasks classification on a public dataset for the real-time condition monitoring of a hydraulic system and demonstrate the usefulness of the system by evaluating the probability of a prediction being accurate given its uncertainty. We deploy these models using our proposed agent-based framework and integrate web visualisation to demonstrate its real-time feasibility.
Bayesian Autoencoders for Drift Detection in Industrial Environments
Jul 28, 2021
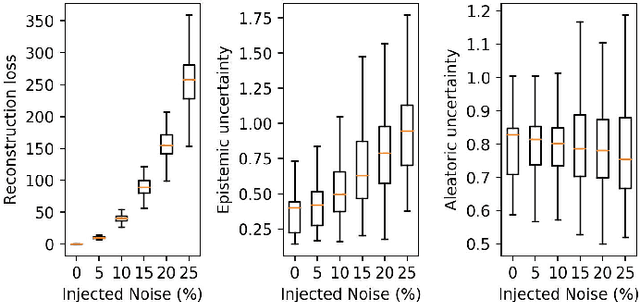


Autoencoders are unsupervised models which have been used for detecting anomalies in multi-sensor environments. A typical use includes training a predictive model with data from sensors operating under normal conditions and using the model to detect anomalies. Anomalies can come either from real changes in the environment (real drift) or from faulty sensory devices (virtual drift); however, the use of Autoencoders to distinguish between different anomalies has not yet been considered. To this end, we first propose the development of Bayesian Autoencoders to quantify epistemic and aleatoric uncertainties. We then test the Bayesian Autoencoder using a real-world industrial dataset for hydraulic condition monitoring. The system is injected with noise and drifts, and we have found the epistemic uncertainty to be less sensitive to sensor perturbations as compared to the reconstruction loss. By observing the reconstructed signals with the uncertainties, we gain interpretable insights, and these uncertainties offer a potential avenue for distinguishing real and virtual drifts.