 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Quantum Computing Approach for Multi-robot Coverage Path Planning
Jul 11, 2024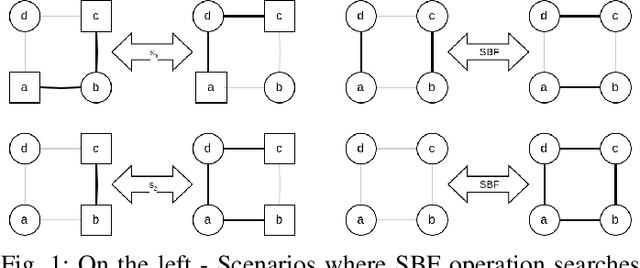

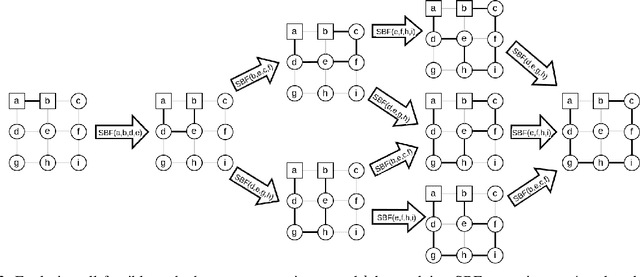
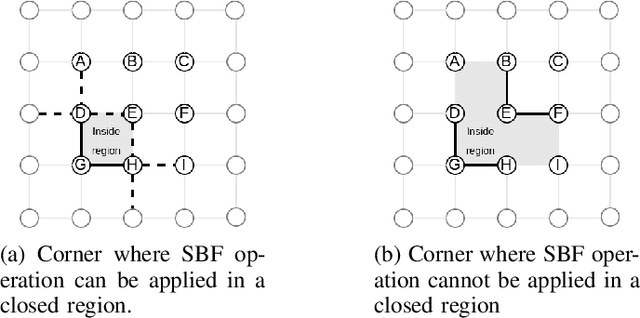
This paper tackles the multi-vehicle Coverage Path Planning (CPP) problem, crucial for applications like search and rescue or environmental monitoring. Due to its NP-hard nature, finding optimal solutions becomes infeasible with larger problem sizes. This motivates the development of heuristic approaches that enhance efficiency even marginally. We propose a novel approach for exploring paths in a 2D grid, specifically designed for easy integration with the Quantum Alternating Operator Ansatz (QAOA), a powerful quantum heuristic. Our contribution includes: 1) An objective function tailored to solve the multi-vehicle CPP using QAOA. 2) Theoretical proofs guaranteeing the validity of the proposed approach. 3) Efficient construction of QAOA operators for practical implementation. 4) Resource estimation to assess the feasibility of QAOA execution. 5) Performance comparison against established algorithms like the Depth First Search. This work paves the way for leveraging quantum computing in optimizing multi-vehicle path planning, potentially leading to real-world advancements in various applications.
Extracting Conceptual Knowledge from Natural Language Text Using Maximum Likelihood Principle
Sep 19, 2019
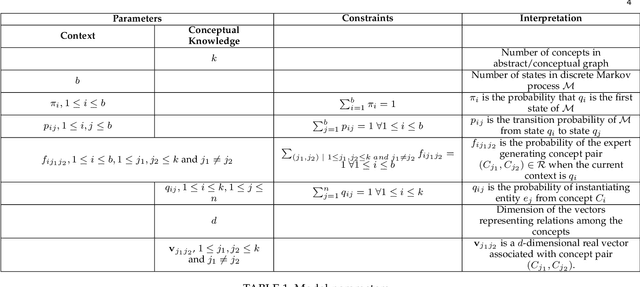
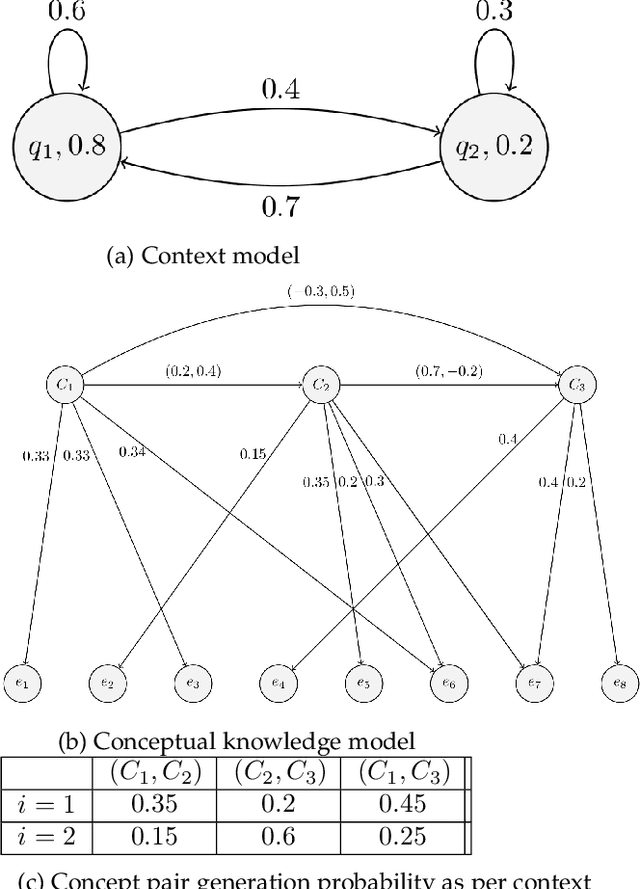
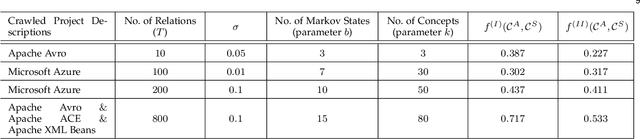
Domain-specific knowledge graphs constructed from natural language text are ubiquitous in today's world. In many such scenarios the base text, from which the knowledge graph is constructed, concerns itself with practical, on-hand, actual or ground-reality information about the domain. Product documentation in software engineering domain are one example of such base texts. Other examples include blogs and texts related to digital artifacts, reports on emerging markets and business models, patient medical records, etc. Though the above sources contain a wealth of knowledge about their respective domains, the conceptual knowledge on which they are based is often missing or unclear. Access to this conceptual knowledge can enormously increase the utility of available data and assist in several tasks such as knowledge graph completion, grounding, querying, etc. Our contributions in this paper are twofold. First, we propose a novel Markovian stochastic model for document generation from conceptual knowledge. The uniqueness of our approach lies in the fact that the conceptual knowledge in the writer's mind forms a component of the parameter set of our stochastic model. Secondly, we solve the inverse problem of learning the best conceptual knowledge from a given document, by finding model parameters which maximize the likelihood of generating the specific document over all possible parameter values. This likelihood maximization is done using an application of Baum-Welch algorithm, which is a known special case of Expectation-Maximization (EM) algorithm. We run our conceptualization algorithm on several well-known natural language sources and obtain very encouraging results. The results of our extensive experiments concur with the hypothesis that the information contained in these sources has a well-defined and rigorous underlying conceptual structure, which can be discovered using our method.
APR: Architectural Pattern Recommender
Mar 23, 2018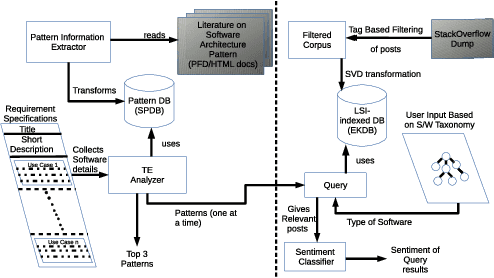
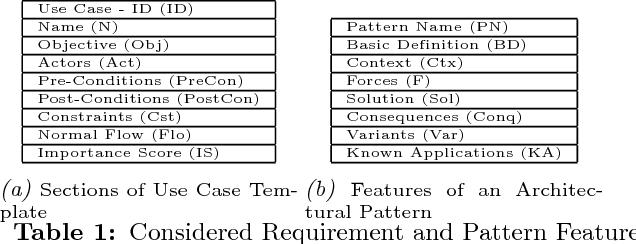
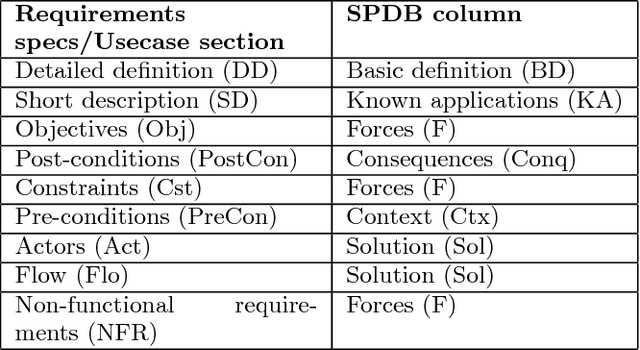
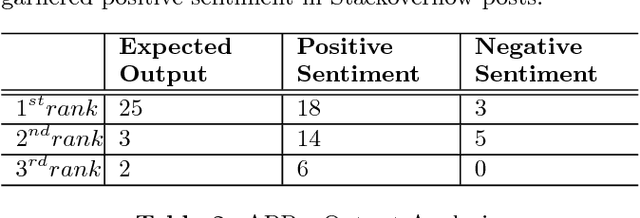
This paper proposes Architectural Pattern Recommender (APR) system which helps in such architecture selection process. Main contribution of this work is in replacing the manual effort required to identify and analyse relevant architectural patterns in context of a particular set of software requirements. Key input to APR is a set of architecturally significant use cases concerning the application being developed. Central idea of APR's design is two folds: a) transform the unstructured information about software architecture design into a structured form which is suitable for recognizing textual entailment between a requirement scenario and a potential architectural pattern. b) leverage the rich experiential knowledge embedded in discussions on professional developer support forums such as Stackoverflow to check the sentiment about a design decision. APR makes use of both the above elements to identify a suitable architectural pattern and assess its suitability for a given set of requirements. Efficacy of APR has been evaluated by comparing its recommendations for "ground truth" scenarios (comprising of applications whose architecture is well known).
* 6 Pages, 1 Figure. Published in SAC 2017 in Software Engineering Track
Estimating defectiveness of source code: A predictive model using GitHub content
Mar 21, 2018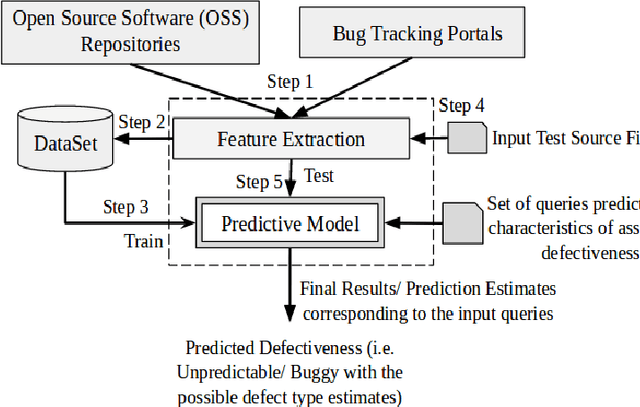

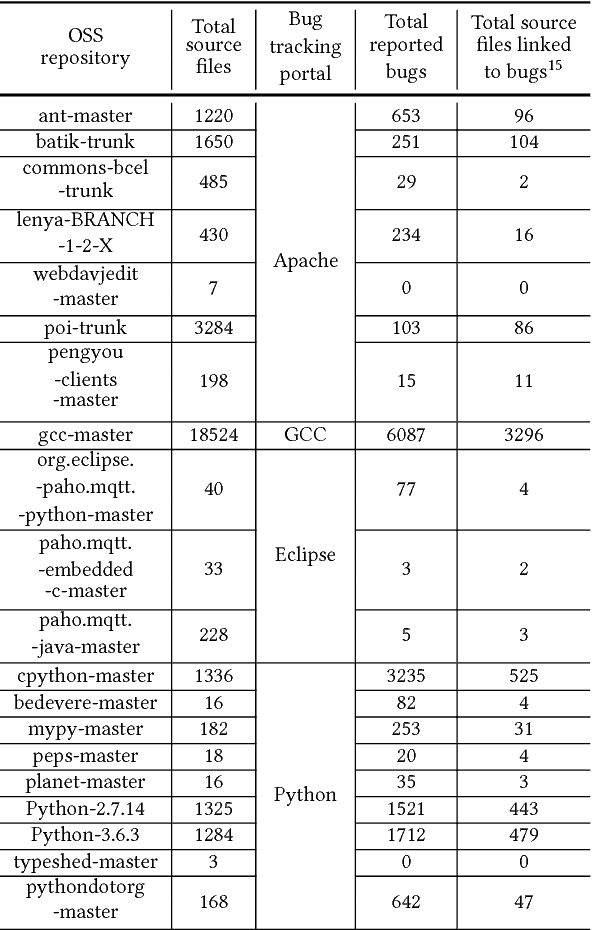
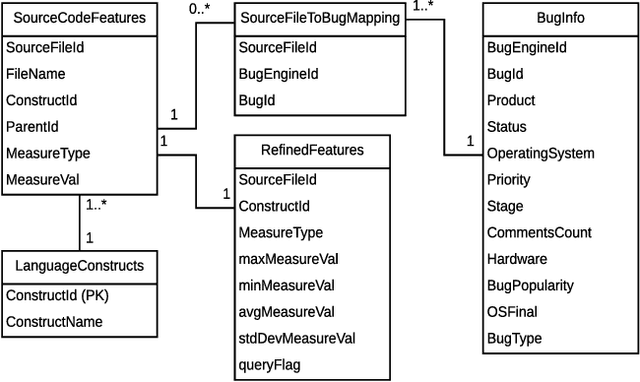
Two key contributions presented in this paper are: i) A method for building a dataset containing source code features extracted from source files taken from Open Source Software (OSS) and associated bug reports, ii) A predictive model for estimating defectiveness of a given source code. These artifacts can be useful for building tools and techniques pertaining to several automated software engineering areas such as bug localization, code review, and recommendation and program repair. In order to achieve our goal, we first extract coding style information (e.g. related to programming language constructs used in the source code) for source code files present on GitHub. Then the information available in bug reports (if any) associated with these source code files are extracted. Thus fetched un(/ semi)-structured information is then transformed into a structured knowledge base. We considered more than 30400 source code files from 20 different GitHub repositories with about 14950 associated bug reports across 4 bug tracking portals. The source code files considered are written in four programming languages (viz., C, C++, Java, and Python) and belong to different types of applications. A machine learning (ML) model for estimating the defectiveness of a given input source code is then trained using the knowledge base. In order to pick the best ML model, we evaluated 8 different ML algorithms such as Random Forest, K Nearest Neighbour and SVM with around 50 parameter configurations to compare their performance on our tasks. One of our findings shows that best K-fold (with k=5) cross-validation results are obtained with the NuSVM technique that gives a mean F1 score of 0.914.
A Simplified Description of Fuzzy TOPSIS
Jun 03, 2017
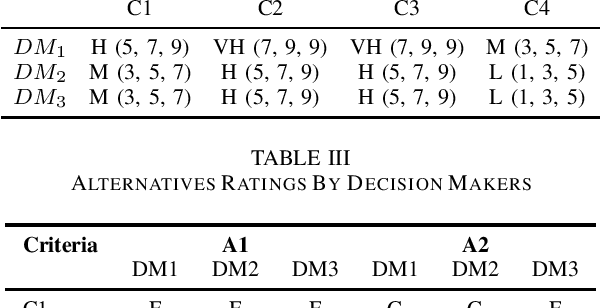
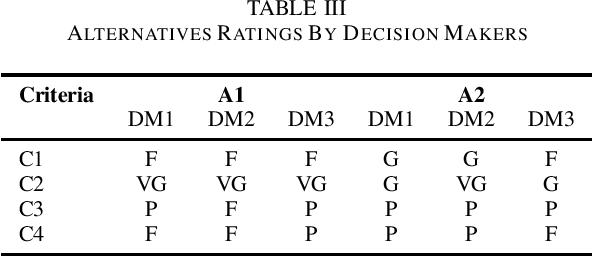
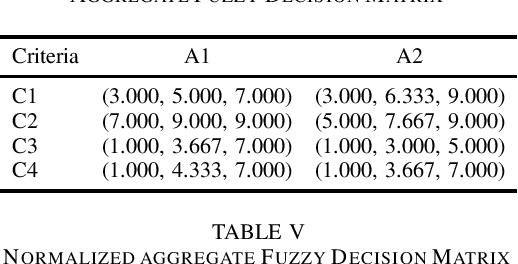
A simplified description of Fuzzy TOPSIS (Technique for Order Preference by Similarity to Ideal Situation) is presented. We have adapted the TOPSIS description from existing Fuzzy theory literature and distilled the bare minimum concepts required for understanding and applying TOPSIS. An example has been worked out to illustrate the application of TOPSIS for a multi-criteria group decision making scenario.