 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating defectiveness of source code: A predictive model using GitHub content
Paper and Code
Mar 21, 2018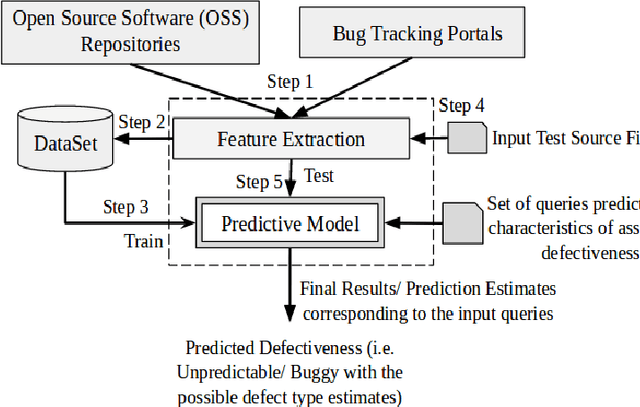

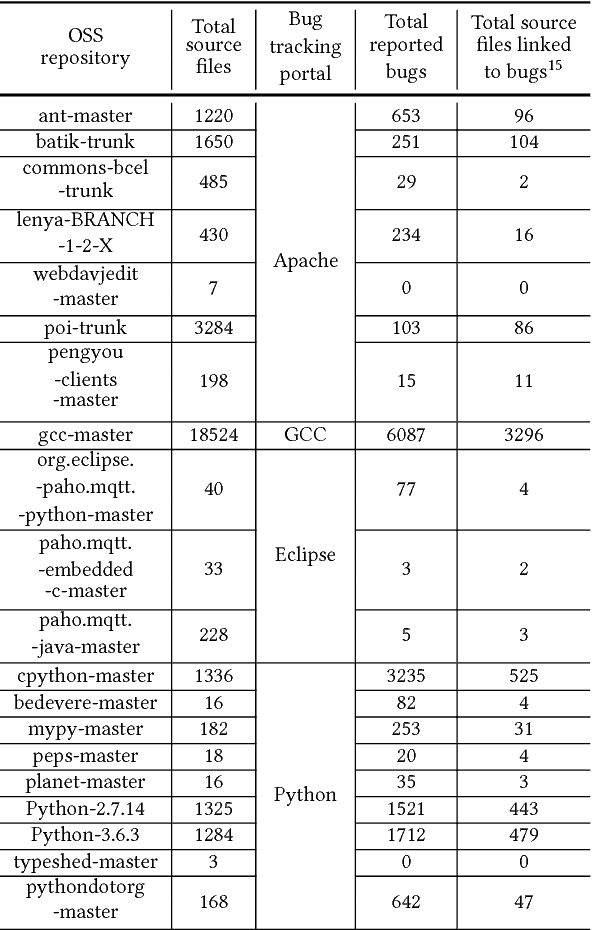
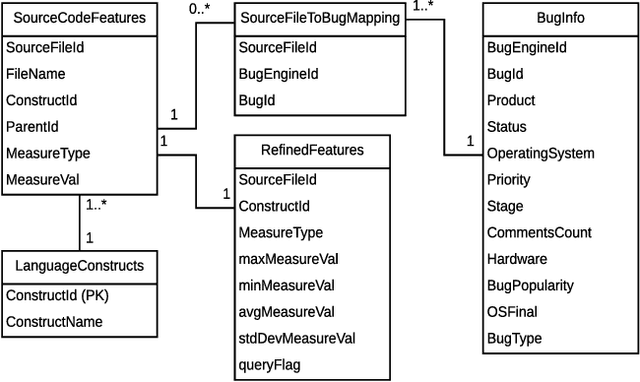
Two key contributions presented in this paper are: i) A method for building a dataset containing source code features extracted from source files taken from Open Source Software (OSS) and associated bug reports, ii) A predictive model for estimating defectiveness of a given source code. These artifacts can be useful for building tools and techniques pertaining to several automated software engineering areas such as bug localization, code review, and recommendation and program repair. In order to achieve our goal, we first extract coding style information (e.g. related to programming language constructs used in the source code) for source code files present on GitHub. Then the information available in bug reports (if any) associated with these source code files are extracted. Thus fetched un(/ semi)-structured information is then transformed into a structured knowledge base. We considered more than 30400 source code files from 20 different GitHub repositories with about 14950 associated bug reports across 4 bug tracking portals. The source code files considered are written in four programming languages (viz., C, C++, Java, and Python) and belong to different types of applications. A machine learning (ML) model for estimating the defectiveness of a given input source code is then trained using the knowledge base. In order to pick the best ML model, we evaluated 8 different ML algorithms such as Random Forest, K Nearest Neighbour and SVM with around 50 parameter configurations to compare their performance on our tasks. One of our findings shows that best K-fold (with k=5) cross-validation results are obtained with the NuSVM technique that gives a mean F1 score of 0.914.