 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Conceptual Knowledge from Natural Language Text Using Maximum Likelihood Principle
Paper and Code
Sep 19, 2019
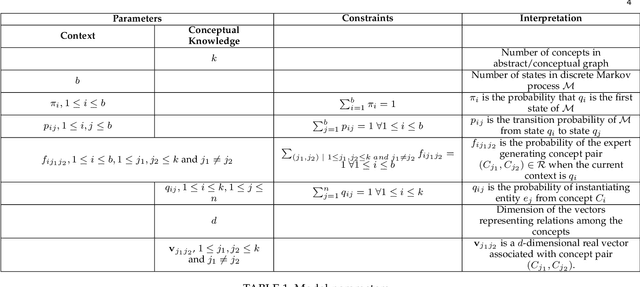
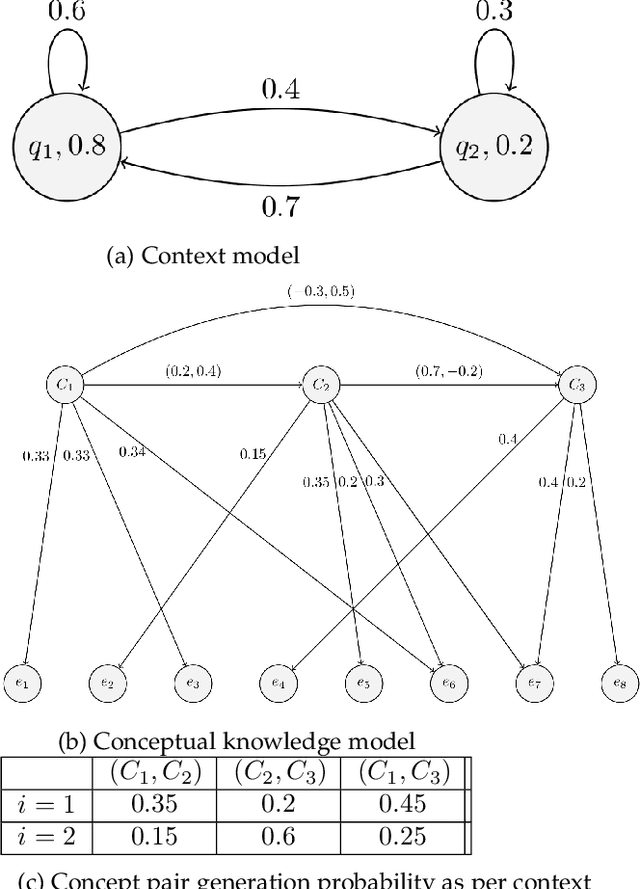
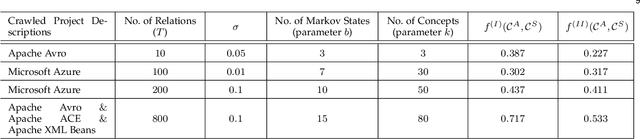
Domain-specific knowledge graphs constructed from natural language text are ubiquitous in today's world. In many such scenarios the base text, from which the knowledge graph is constructed, concerns itself with practical, on-hand, actual or ground-reality information about the domain. Product documentation in software engineering domain are one example of such base texts. Other examples include blogs and texts related to digital artifacts, reports on emerging markets and business models, patient medical records, etc. Though the above sources contain a wealth of knowledge about their respective domains, the conceptual knowledge on which they are based is often missing or unclear. Access to this conceptual knowledge can enormously increase the utility of available data and assist in several tasks such as knowledge graph completion, grounding, querying, etc. Our contributions in this paper are twofold. First, we propose a novel Markovian stochastic model for document generation from conceptual knowledge. The uniqueness of our approach lies in the fact that the conceptual knowledge in the writer's mind forms a component of the parameter set of our stochastic model. Secondly, we solve the inverse problem of learning the best conceptual knowledge from a given document, by finding model parameters which maximize the likelihood of generating the specific document over all possible parameter values. This likelihood maximization is done using an application of Baum-Welch algorithm, which is a known special case of Expectation-Maximization (EM) algorithm. We run our conceptualization algorithm on several well-known natural language sources and obtain very encouraging results. The results of our extensive experiments concur with the hypothesis that the information contained in these sources has a well-defined and rigorous underlying conceptual structure, which can be discovered using our method.