 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal plannability by variance of the episode length
Jan 09, 2003
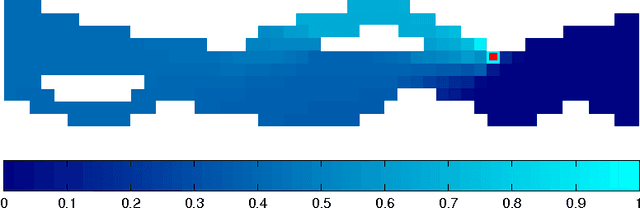

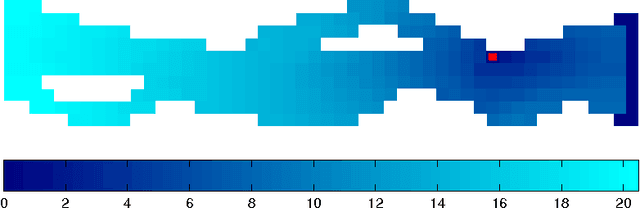
Optimization of decision problems in stochastic environments is usually concerned with maximizing the probability of achieving the goal and minimizing the expected episode length. For interacting agents in time-critical applications, learning of the possibility of scheduling of subtasks (events) or the full task is an additional relevant issue. Besides, there exist highly stochastic problems where the actual trajectories show great variety from episode to episode, but completing the task takes almost the same amount of time. The identification of sub-problems of this nature may promote e.g., planning, scheduling and segmenting Markov decision processes. In this work, formulae for the average duration as well as the standard deviation of the duration of events are derived. The emerging Bellman-type equation is a simple extension of Sobel's work (1982). Methods of dynamic programming as well as methods of reinforcement learning can be applied for our extension. Computer demonstration on a toy problem serve to highlight the principle.
Searching for Plannable Domains can Speed up Reinforcement Learning
Dec 10, 2002
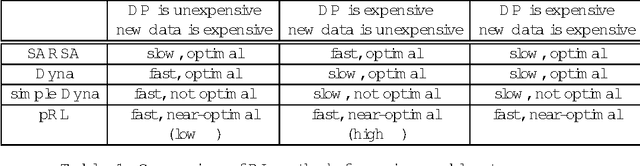
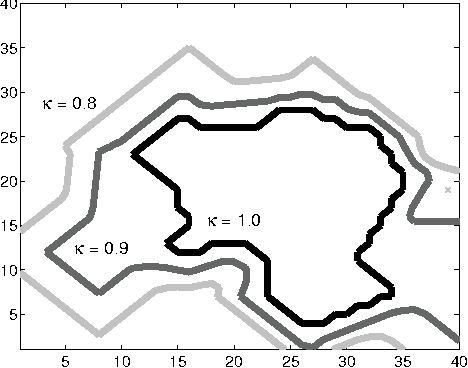

Reinforcement learning (RL) involves sequential decision making in uncertain environments. The aim of the decision-making agent is to maximize the benefit of acting in its environment over an extended period of time. Finding an optimal policy in RL may be very slow. To speed up learning, one often used solution is the integration of planning, for example, Sutton's Dyna algorithm, or various other methods using macro-actions. Here we suggest to separate plannable, i.e., close to deterministic parts of the world, and focus planning efforts in this domain. A novel reinforcement learning method called plannable RL (pRL) is proposed here. pRL builds a simple model, which is used to search for macro actions. The simplicity of the model makes planning computationally inexpensive. It is shown that pRL finds an optimal policy, and that plannable macro actions found by pRL are near-optimal. In turn, it is unnecessary to try large numbers of macro actions, which enables fast learning. The utility of pRL is demonstrated by computer simulations.