 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal plannability by variance of the episode length
Paper and Code
Jan 09, 2003
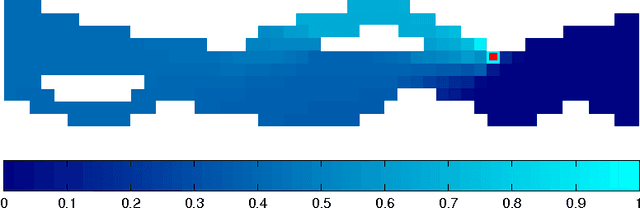

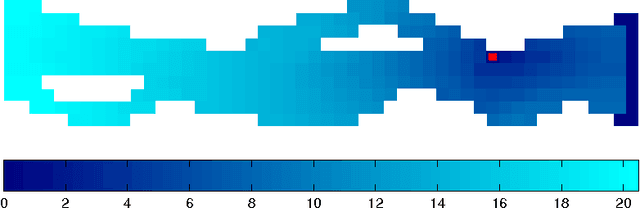
Optimization of decision problems in stochastic environments is usually concerned with maximizing the probability of achieving the goal and minimizing the expected episode length. For interacting agents in time-critical applications, learning of the possibility of scheduling of subtasks (events) or the full task is an additional relevant issue. Besides, there exist highly stochastic problems where the actual trajectories show great variety from episode to episode, but completing the task takes almost the same amount of time. The identification of sub-problems of this nature may promote e.g., planning, scheduling and segmenting Markov decision processes. In this work, formulae for the average duration as well as the standard deviation of the duration of events are derived. The emerging Bellman-type equation is a simple extension of Sobel's work (1982). Methods of dynamic programming as well as methods of reinforcement learning can be applied for our extension. Computer demonstration on a toy problem serve to highlight the principle.