 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Heavy-tailed Change-point detection
Jul 03, 2023We study algorithms for online change-point detection (OCPD), where samples that are potentially heavy-tailed, are presented one at a time and a change in the underlying mean must be detected as early as possible. We present an algorithm based on clipped Stochastic Gradient Descent (SGD), that works even if we only assume that the second moment of the data generating process is bounded. We derive guarantees on worst-case, finite-sample false-positive rate (FPR) over the family of all distributions with bounded second moment. Thus, our method is the first OCPD algorithm that guarantees finite-sample FPR, even if the data is high dimensional and the underlying distributions are heavy-tailed. The technical contribution of our paper is to show that clipped-SGD can estimate the mean of a random vector and simultaneously provide confidence bounds at all confidence values. We combine this robust estimate with a union bound argument and construct a sequential change-point algorithm with finite-sample FPR guarantees. We show empirically that our algorithm works well in a variety of situations, whether the underlying data are heavy-tailed, light-tailed, high dimensional or discrete. No other algorithm achieves bounded FPR theoretically or empirically, over all settings we study simultaneously.
Imitation-Regularized Offline Learning
Jan 15, 2019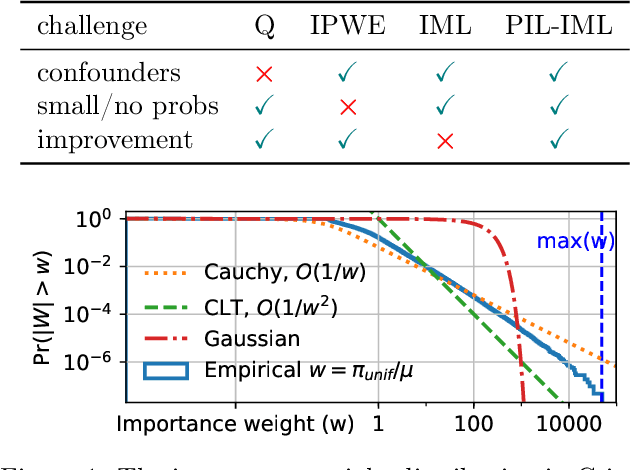
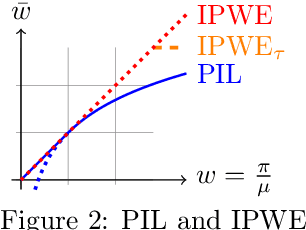

We study the problem of offline learning in automated decision systems under the contextual bandits model. We are given logged historical data consisting of contexts, (randomized) actions, and (nonnegative) rewards. A common goal is to evaluate what would happen if different actions were taken in the same contexts, so as to optimize the action policies accordingly. The typical approach to this problem, inverse probability weighted estimation (IPWE) [Bottou et al., 2013], requires logged action probabilities, which may be missing in practice due to engineering complications. Even when available, small action probabilities cause large uncertainty in IPWE, rendering the corresponding results insignificant. To solve both problems, we show how one can use policy improvement (PIL) objectives, regularized by policy imitation (IML). We motivate and analyze PIL as an extension to Clipped-IPWE, by showing that both are lower-bound surrogates to the vanilla IPWE. We also formally connect IML to IPWE variance estimation [Swaminathan and Joachims 2015] and natural policy gradients. Without probability logging, our PIL-IML interpretations justify and improve, by reward-weighting, the state-of-art cross-entropy (CE) loss that predicts the action items among all action candidates available in the same contexts. With probability logging, our main theoretical contribution connects IML-underfitting to the existence of either confounding variables or model misspecification. We show the value and accuracy of our insights by simulations based on Simpson's paradox, standard UCI multiclass-to-bandit conversions and on the Criteo counterfactual analysis challenge dataset.