 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Linear Regression: a Statistical Test of Gain
Feb 18, 2021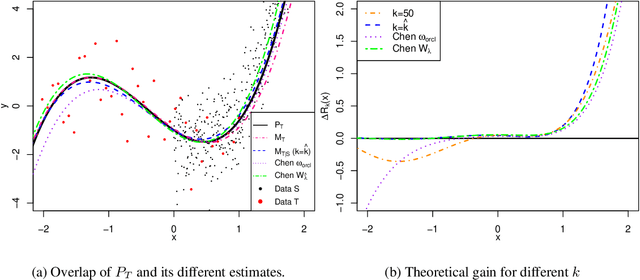
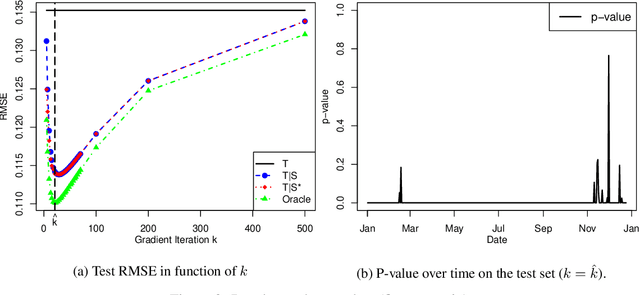
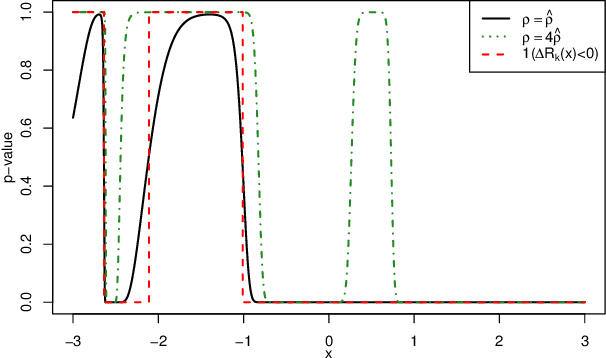
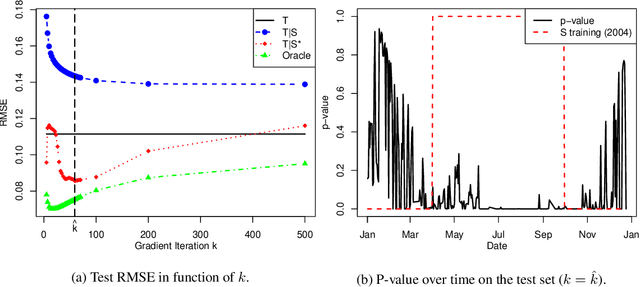
Transfer learning, also referred as knowledge transfer, aims at reusing knowledge from a source dataset to a similar target one. While many empirical studies illustrate the benefits of transfer learning, few theoretical results are established especially for regression problems. In this paper a theoretical framework for the problem of parameter transfer for the linear model is proposed. It is shown that the quality of transfer for a new input vector $x$ depends on its representation in an eigenbasis involving the parameters of the problem. Furthermore a statistical test is constructed to predict whether a fine-tuned model has a lower prediction quadratic risk than the base target model for an unobserved sample. Efficiency of the test is illustrated on synthetic data as well as real electricity consumption data.
Textual Data for Time Series Forecasting
Oct 29, 2019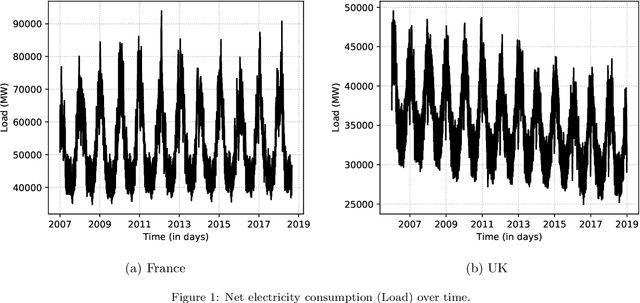
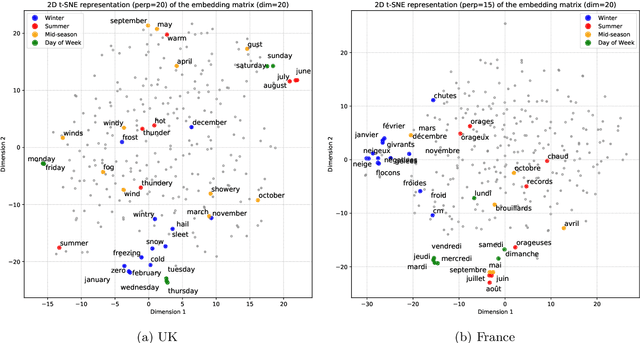
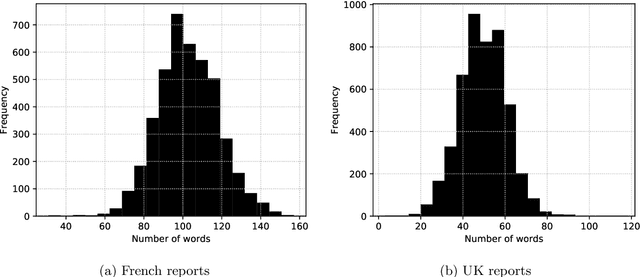

While ubiquitous, textual sources of information such as company reports, social media posts, etc. are hardly included in prediction algorithms for time series, despite the relevant information they may contain. In this work, openly accessible daily weather reports from France and the United-Kingdom are leveraged to predict time series of national electricity consumption, average temperature and wind-speed with a single pipeline. Two methods of numerical representation of text are considered, namely traditional Term Frequency - Inverse Document Frequency (TF-IDF) as well as our own neural word embedding. Using exclusively text, we are able to predict the aforementioned time series with sufficient accuracy to be used to replace missing data. Furthermore the proposed word embeddings display geometric properties relating to the behavior of the time series and context similarity between words.
Inferring linear and nonlinear Interaction networks using neighborhood support vector machines
Aug 02, 2019


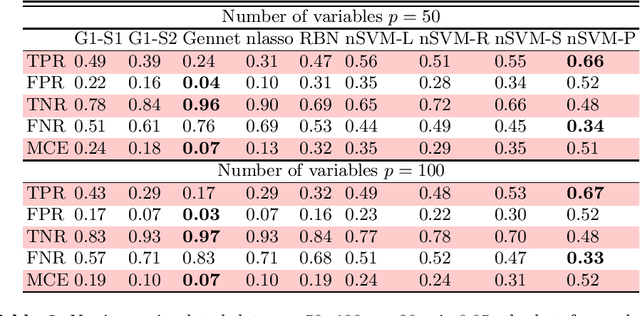
In this paper, we consider modelling interaction between a set of variables in the context of time series and high dimension. We suggest two approaches. The first is similar to the neighborhood lasso when the lasso model is replaced by a support vector machine (SVMs). The second is a restricted Bayesian network adapted for time series. We show the efficiency of our approaches by simulations using linear, nonlinear data set and a mixture of both.
Clustering using Unsupervised Binary Trees: CUBT
Oct 27, 2011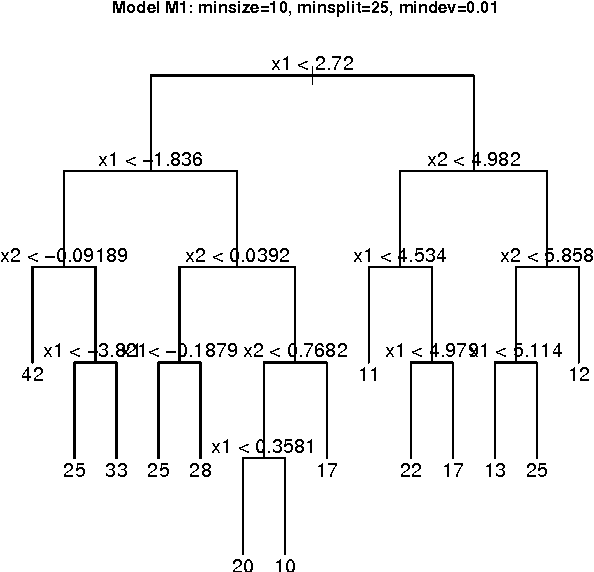
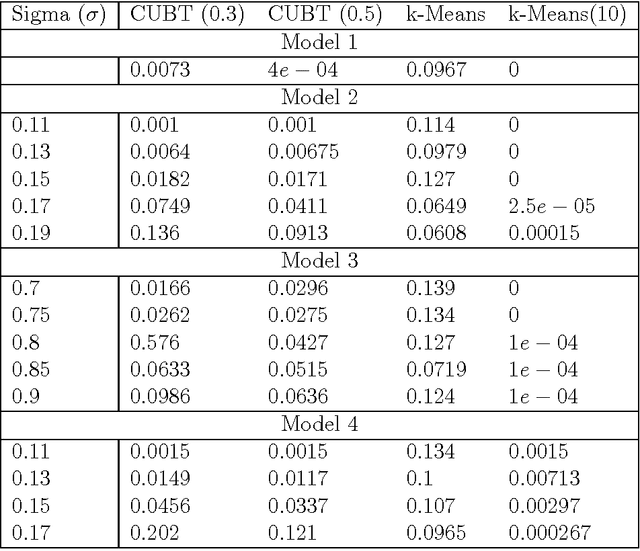
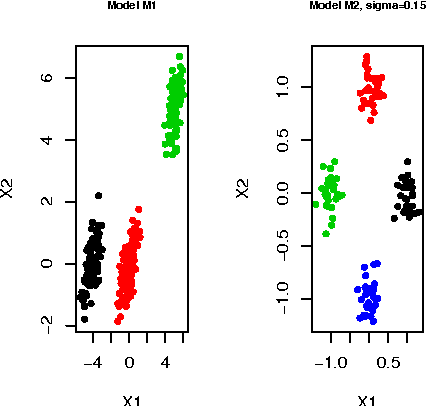
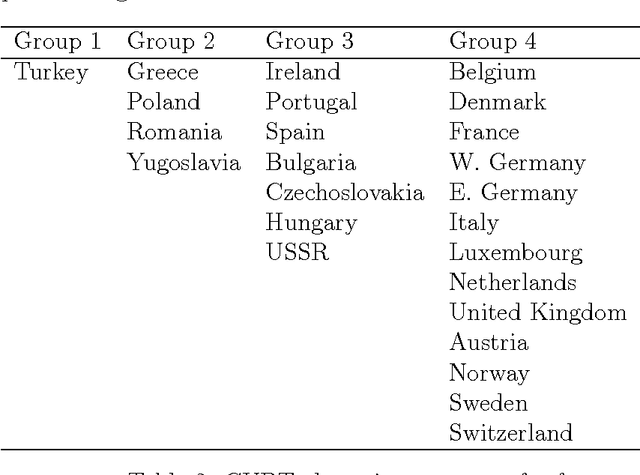
We herein introduce a new method of interpretable clustering that uses unsupervised binary trees. It is a three-stage procedure, the first stage of which entails a series of recursive binary splits to reduce the heterogeneity of the data within the new subsamples. During the second stage (pruning), consideration is given to whether adjacent nodes can be aggregated. Finally, during the third stage (joining), similar clusters are joined together, even if they do not share the same parent originally. Consistency results are obtained, and the procedure is used on simulated and real data sets.