 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Flow-rate-conserving CNN-based Domain Decomposition Method for Blood Flow Simulations
Sep 19, 2025



This work aims to predict blood flow with non-Newtonian viscosity in stenosed arteries using convolutional neural network (CNN) surrogate models. An alternating Schwarz domain decomposition method is proposed which uses CNN-based subdomain solvers. A universal subdomain solver (USDS) is trained on a single, fixed geometry and then applied for each subdomain solve in the Schwarz method. Results for two-dimensional stenotic arteries of varying shape and length for different inflow conditions are presented and statistically evaluated. One key finding, when using a limited amount of training data, is the need to implement a USDS which preserves some of the physics, as, in our case, flow rate conservation. A physics-aware approach outperforms purely data-driven USDS, delivering improved subdomain solutions and preventing overshooting or undershooting of the global solution during the Schwarz iterations, thereby leading to more reliable convergence.
Towards Automated Algebraic Multigrid Preconditioner Design Using Genetic Programming for Large-Scale Laser Beam Welding Simulations
Dec 11, 2024



Multigrid methods are asymptotically optimal algorithms ideal for large-scale simulations. But, they require making numerous algorithmic choices that significantly influence their efficiency. Unlike recent approaches that learn optimal multigrid components using machine learning techniques, we adopt a complementary strategy here, employing evolutionary algorithms to construct efficient multigrid cycles from available individual components. This technology is applied to finite element simulations of the laser beam welding process. The thermo-elastic behavior is described by a coupled system of time-dependent thermo-elasticity equations, leading to nonlinear and ill-conditioned systems. The nonlinearity is addressed using Newton's method, and iterative solvers are accelerated with an algebraic multigrid (AMG) preconditioner using hypre BoomerAMG interfaced via PETSc. This is applied as a monolithic solver for the coupled equations. To further enhance solver efficiency, flexible AMG cycles are introduced, extending traditional cycle types with level-specific smoothing sequences and non-recursive cycling patterns. These are automatically generated using genetic programming, guided by a context-free grammar containing AMG rules. Numerical experiments demonstrate the potential of these approaches to improve solver performance in large-scale laser beam welding simulations.
Domain-decomposed image classification algorithms using linear discriminant analysis and convolutional neural networks
Oct 30, 2024



In many modern computer application problems, the classification of image data plays an important role. Among many different supervised machine learning models, convolutional neural networks (CNNs) and linear discriminant analysis (LDA) as well as sophisticated variants thereof are popular techniques. In this work, two different domain decomposed CNN models are experimentally compared for different image classification problems. Both models are loosely inspired by domain decomposition methods and in addition, combined with a transfer learning strategy. The resulting models show improved classification accuracies compared to the corresponding, composed global CNN model without transfer learning and besides, also help to speed up the training process. Moreover, a novel decomposed LDA strategy is proposed which also relies on a localization approach and which is combined with a small neural network model. In comparison with a global LDA applied to the entire input data, the presented decomposed LDA approach shows increased classification accuracies for the considered test problems.
Model Parallel Training and Transfer Learning for Convolutional Neural Networks by Domain Decomposition
Aug 26, 2024


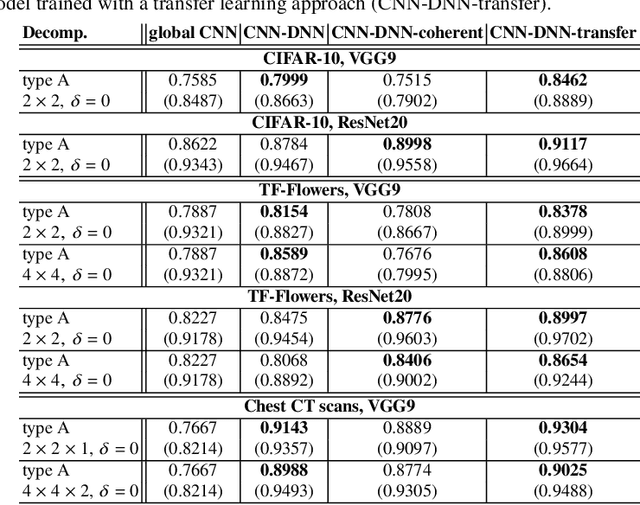
Deep convolutional neural networks (CNNs) have been shown to be very successful in a wide range of image processing applications. However, due to their increasing number of model parameters and an increasing availability of large amounts of training data, parallelization strategies to efficiently train complex CNNs are necessary. In previous work by the authors, a novel model parallel CNN architecture was proposed which is loosely inspired by domain decomposition. In particular, the novel network architecture is based on a decomposition of the input data into smaller subimages. For each of these subimages, local CNNs with a proportionally smaller number of parameters are trained in parallel and the resulting local classifications are then aggregated in a second step by a dense feedforward neural network (DNN). In the present work, we compare the resulting CNN-DNN architecture to less costly alternatives to combine the local classifications into a final, global decision. Additionally, we investigate the performance of the CNN-DNN trained as one coherent model as well as using a transfer learning strategy, where the parameters of the pre-trained local CNNs are used as initial values for a subsequently trained global coherent CNN-DNN model.
Machine learning and domain decomposition methods -- a survey
Dec 21, 2023


Hybrid algorithms, which combine black-box machine learning methods with experience from traditional numerical methods and domain expertise from diverse application areas, are progressively gaining importance in scientific machine learning and various industrial domains, especially in computational science and engineering. In the present survey, several promising avenues of research will be examined which focus on the combination of machine learning (ML) and domain decomposition methods (DDMs). The aim of this survey is to provide an overview of existing work within this field and to structure it into domain decomposition for machine learning and machine learning-enhanced domain decomposition, including: domain decomposition for classical machine learning, domain decomposition to accelerate the training of physics-aware neural networks, machine learning to enhance the convergence properties or computational efficiency of DDMs, and machine learning as a discretization method in a DDM for the solution of PDEs. In each of these fields, we summarize existing work and key advances within a common framework and, finally, disuss ongoing challenges and opportunities for future research.
Learning the solution operator of two-dimensional incompressible Navier-Stokes equations using physics-aware convolutional neural networks
Aug 04, 2023



In recent years, the concept of introducing physics to machine learning has become widely popular. Most physics-inclusive ML-techniques however are still limited to a single geometry or a set of parametrizable geometries. Thus, there remains the need to train a new model for a new geometry, even if it is only slightly modified. With this work we introduce a technique with which it is possible to learn approximate solutions to the steady-state Navier--Stokes equations in varying geometries without the need of parametrization. This technique is based on a combination of a U-Net-like CNN and well established discretization methods from the field of the finite difference method.The results of our physics-aware CNN are compared to a state-of-the-art data-based approach. Additionally, it is also shown how our approach performs when combined with the data-based approach.
A Domain Decomposition-Based CNN-DNN Architecture for Model Parallel Training Applied to Image Recognition Problems
Feb 13, 2023



Deep neural networks (DNNs) and, in particular, convolutional neural networks (CNNs) have brought significant advances in a wide range of modern computer application problems. However, the increasing availability of large amounts of datasets as well as the increasing available computational power of modern computers lead to a steady growth in the complexity and size of DNN and CNN models, and thus, to longer training times. Hence, various methods and attempts have been developed to accelerate and parallelize the training of complex network architectures. In this work, a novel CNN-DNN architecture is proposed that naturally supports a model parallel training strategy and that is loosely inspired by two-level domain decomposition methods (DDM). First, local CNN models, that is, subnetworks, are defined that operate on overlapping or nonoverlapping parts of the input data, for example, sub-images. The subnetworks can be trained completely in parallel. Each subnetwork outputs a local decision for the given machine learning problem which is exclusively based on the respective local input data. Subsequently, an additional DNN model is trained which evaluates the local decisions of the local subnetworks and generates a final, global decision. With respect to the analogy to DDM, the DNN can be interpreted as a coarse problem and hence, the new approach can be interpreted as a two-level domain decomposition. In this paper, solely image classification problems using CNNs are considered. Experimental results for different 2D image classification problems are provided as well as a face recognition problem, and a classification problem for 3D computer tomography (CT) scans. The results show that the proposed approach can significantly accelerate the required training time compared to the global model and, additionally, can also help to improve the accuracy of the underlying classification problem.