 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Parallel Training and Transfer Learning for Convolutional Neural Networks by Domain Decomposition
Paper and Code
Aug 26, 2024


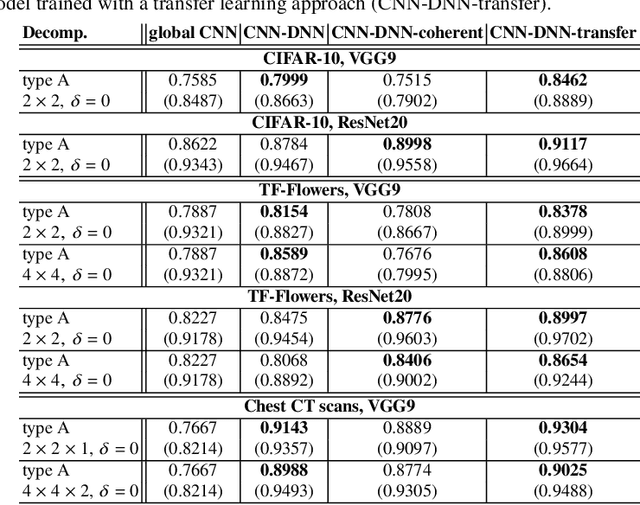
Deep convolutional neural networks (CNNs) have been shown to be very successful in a wide range of image processing applications. However, due to their increasing number of model parameters and an increasing availability of large amounts of training data, parallelization strategies to efficiently train complex CNNs are necessary. In previous work by the authors, a novel model parallel CNN architecture was proposed which is loosely inspired by domain decomposition. In particular, the novel network architecture is based on a decomposition of the input data into smaller subimages. For each of these subimages, local CNNs with a proportionally smaller number of parameters are trained in parallel and the resulting local classifications are then aggregated in a second step by a dense feedforward neural network (DNN). In the present work, we compare the resulting CNN-DNN architecture to less costly alternatives to combine the local classifications into a final, global decision. Additionally, we investigate the performance of the CNN-DNN trained as one coherent model as well as using a transfer learning strategy, where the parameters of the pre-trained local CNNs are used as initial values for a subsequently trained global coherent CNN-DNN model.