 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Fine-Grained Visual Recognition in the Low-Data Regime Through Feature Magnitude Regularization
Sep 03, 2024
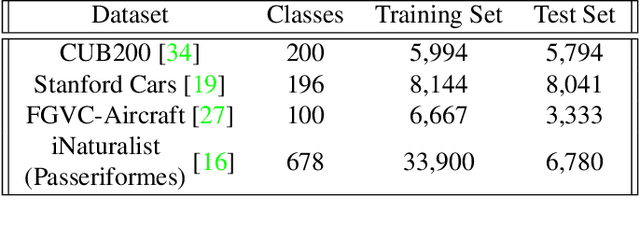
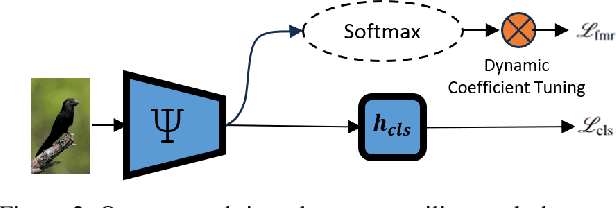
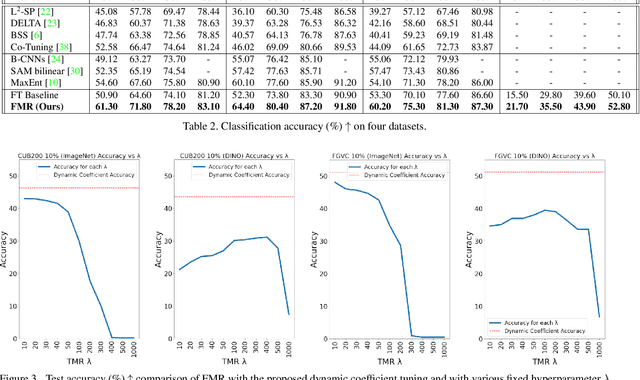
Training a fine-grained image recognition model with limited data presents a significant challenge, as the subtle differences between categories may not be easily discernible amidst distracting noise patterns. One commonly employed strategy is to leverage pretrained neural networks, which can generate effective feature representations for constructing an image classification model with a restricted dataset. However, these pretrained neural networks are typically trained for different tasks than the fine-grained visual recognition (FGVR) task at hand, which can lead to the extraction of less relevant features. Moreover, in the context of building FGVR models with limited data, these irrelevant features can dominate the training process, overshadowing more useful, generalizable discriminative features. Our research has identified a surprisingly simple solution to this challenge: we introduce a regularization technique to ensure that the magnitudes of the extracted features are evenly distributed. This regularization is achieved by maximizing the uniformity of feature magnitude distribution, measured through the entropy of the normalized features. The motivation behind this regularization is to remove bias in feature magnitudes from pretrained models, where some features may be more prominent and, consequently, more likely to be used for classification. Additionally, we have developed a dynamic weighting mechanism to adjust the strength of this regularization throughout the learning process. Despite its apparent simplicity, our approach has demonstrated significant performance improvements across various fine-grained visual recognition datasets.
On Interpretable Approaches to Cluster, Classify and Represent Multi-Subspace Data via Minimum Lossy Coding Length based on Rate-Distortion Theory
Feb 21, 2023To cluster, classify and represent are three fundamental objectives of learning from high-dimensional data with intrinsic structure. To this end, this paper introduces three interpretable approaches, i.e., segmentation (clustering) via the Minimum Lossy Coding Length criterion, classification via the Minimum Incremental Coding Length criterion and representation via the Maximal Coding Rate Reduction criterion. These are derived based on the lossy data coding and compression framework from the principle of rate distortion in information theory. These algorithms are particularly suitable for dealing with finite-sample data (allowed to be sparse or almost degenerate) of mixed Gaussian distributions or subspaces. The theoretical value and attractive features of these methods are summarized by comparison with other learning methods or evaluation criteria. This summary note aims to provide a theoretical guide to researchers (also engineers) interested in understanding 'white-box' machine (deep) learning methods.
Regularizing Neural Network Training via Identity-wise Discriminative Feature Suppression
Oct 02, 2022



It is well-known that a deep neural network has a strong fitting capability and can easily achieve a low training error even with randomly assigned class labels. When the number of training samples is small, or the class labels are noisy, networks tend to memorize patterns specific to individual instances to minimize the training error. This leads to the issue of overfitting and poor generalisation performance. This paper explores a remedy by suppressing the network's tendency to rely on instance-specific patterns for empirical error minimisation. The proposed method is based on an adversarial training framework. It suppresses features that can be utilized to identify individual instances among samples within each class. This leads to classifiers only using features that are both discriminative across classes and common within each class. We call our method Adversarial Suppression of Identity Features (ASIF), and demonstrate the usefulness of this technique in boosting generalisation accuracy when faced with small datasets or noisy labels. Our source code is available.