 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Fine-Grained Visual Recognition in the Low-Data Regime Through Feature Magnitude Regularization
Paper and Code
Sep 03, 2024
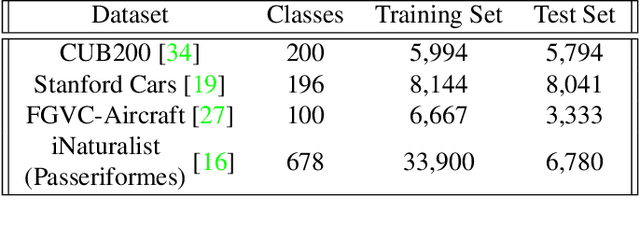
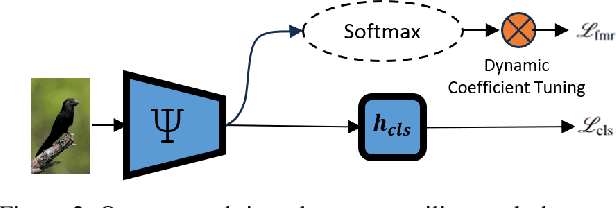
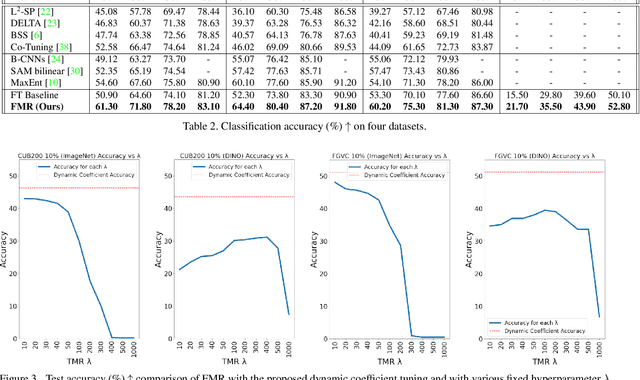
Training a fine-grained image recognition model with limited data presents a significant challenge, as the subtle differences between categories may not be easily discernible amidst distracting noise patterns. One commonly employed strategy is to leverage pretrained neural networks, which can generate effective feature representations for constructing an image classification model with a restricted dataset. However, these pretrained neural networks are typically trained for different tasks than the fine-grained visual recognition (FGVR) task at hand, which can lead to the extraction of less relevant features. Moreover, in the context of building FGVR models with limited data, these irrelevant features can dominate the training process, overshadowing more useful, generalizable discriminative features. Our research has identified a surprisingly simple solution to this challenge: we introduce a regularization technique to ensure that the magnitudes of the extracted features are evenly distributed. This regularization is achieved by maximizing the uniformity of feature magnitude distribution, measured through the entropy of the normalized features. The motivation behind this regularization is to remove bias in feature magnitudes from pretrained models, where some features may be more prominent and, consequently, more likely to be used for classification. Additionally, we have developed a dynamic weighting mechanism to adjust the strength of this regularization throughout the learning process. Despite its apparent simplicity, our approach has demonstrated significant performance improvements across various fine-grained visual recognition datasets.