 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling ML Products At Startups: A Practitioner's Guide
Apr 20, 2023How do you scale a machine learning product at a startup? In particular, how do you serve a greater volume, velocity, and variety of queries cost-effectively? We break down costs into variable costs-the cost of serving the model and performant-and fixed costs-the cost of developing and training new models. We propose a framework for conceptualizing these costs, breaking them into finer categories, and limn ways to reduce costs. Lastly, since in our experience, the most expensive fixed cost of a machine learning system is the cost of identifying the root causes of failures and driving continuous improvement, we present a way to conceptualize the issues and share our methodology for the same.
Instate: Predicting the State of Residence From Last Name
Mar 13, 2023
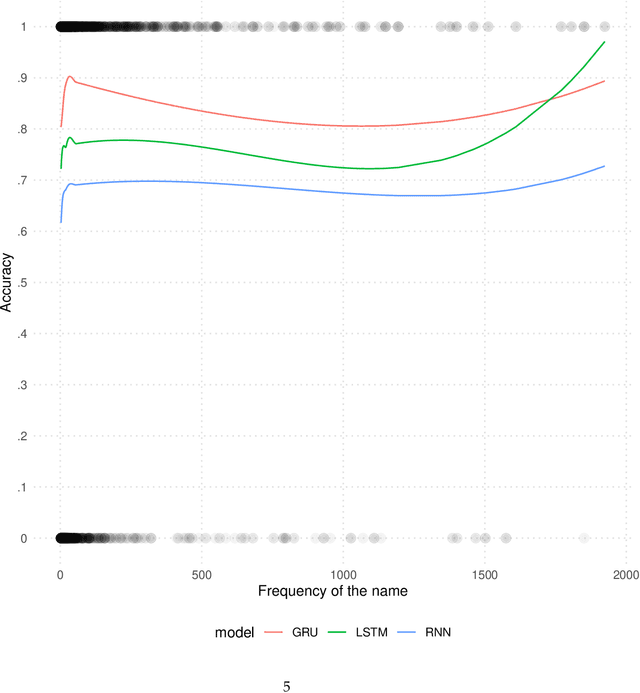
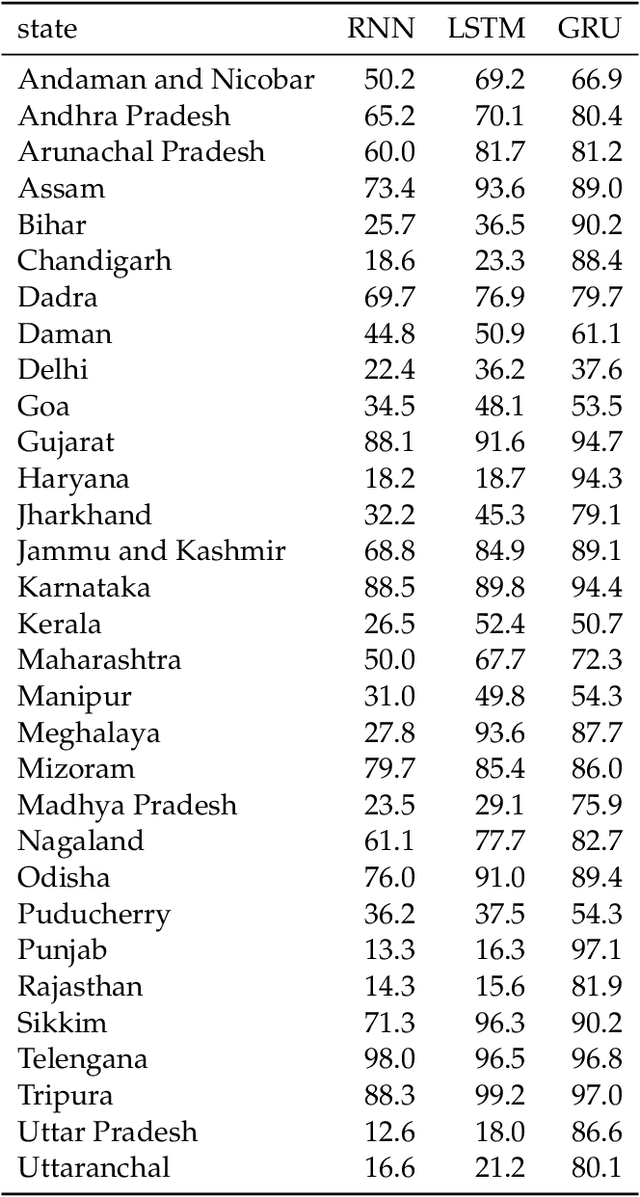
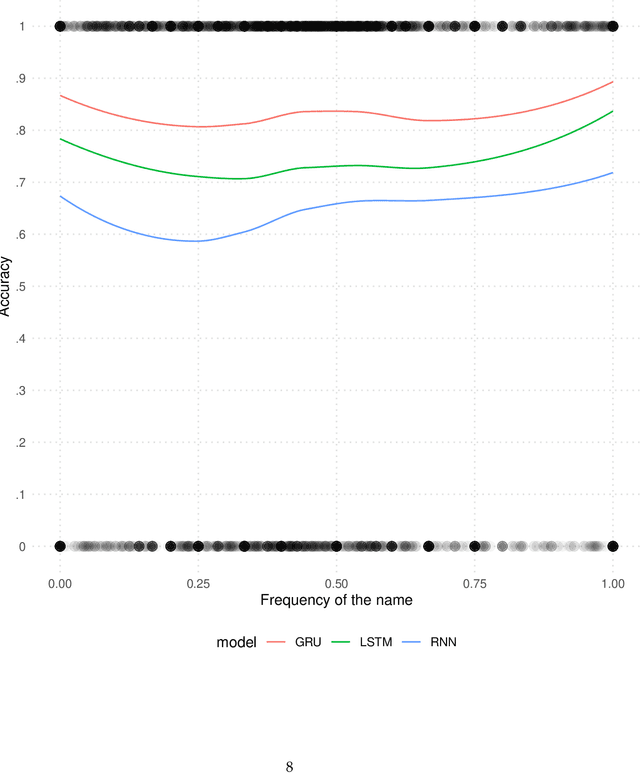
India has twenty-two official languages. Serving such a diverse language base is a challenge for survey statisticians, call center operators, software developers, and other such service providers. To help provide better services to different language communities via better localization, we introduce a new machine learning model that predicts the language(s) that the user can speak from their name. Using nearly 438M records spanning 33 Indian states and 1.13M unique last names from the Indian Electoral Rolls Corpus (?), we build a character-level transformer-based machine-learning model that predicts the state of residence based on the last name. The model has a top-3 accuracy of 85.3% on unseen names. We map the states to languages using the Indian census to infer languages understood by the respondent. We provide open-source software that implements the method discussed in the paper.
Neurorehab: An Interface for Rehabilitation
Jan 26, 2023About 15% of the world population is affected by a disability in some form, amongst whom only 31% perform the recommended exercises without intervention. We are working on developing a motivating and effective way to encourage people. In our work, we leverage the fact that repetitive exercises can help people with motor disabilities due to the robust plasticity of the pre-frontal cognitive control system in the brain. We investigate the role of repetitive activities for neurorehabilitation with the help of a brain computer interface, formulated using immersive game design with Kinect v2.0 and Unity 3D. We also introduce a game design paradigm for adaptive learning for the patients.
Learning Large Scale Sparse Models
Jan 26, 2023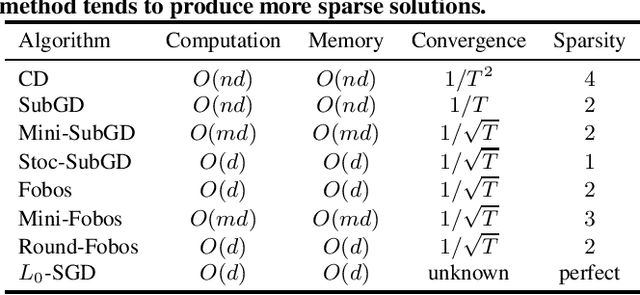
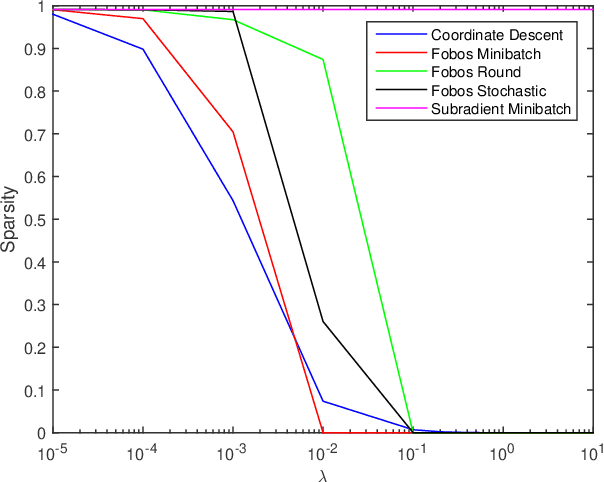
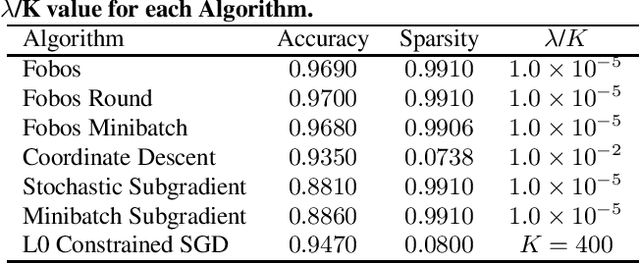
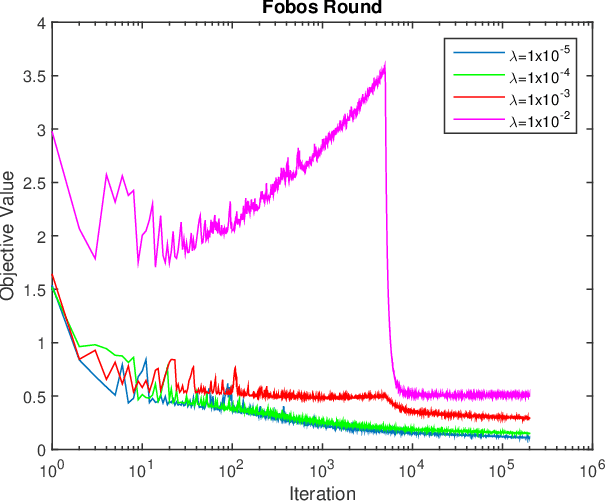
In this work, we consider learning sparse models in large scale settings, where the number of samples and the feature dimension can grow as large as millions or billions. Two immediate issues occur under such challenging scenario: (i) computational cost; (ii) memory overhead. In particular, the memory issue precludes a large volume of prior algorithms that are based on batch optimization technique. To remedy the problem, we propose to learn sparse models such as Lasso in an online manner where in each iteration, only one randomly chosen sample is revealed to update a sparse iterate. Thereby, the memory cost is independent of the sample size and gradient evaluation for one sample is efficient. Perhaps amazingly, we find that with the same parameter, sparsity promoted by batch methods is not preserved in online fashion. We analyze such interesting phenomenon and illustrate some effective variants including mini-batch methods and a hard thresholding based stochastic gradient algorithm. Extensive experiments are carried out on a public dataset which supports our findings and algorithms.
Model Complexity-Accuracy Trade-off for a Convolutional Neural Network
May 09, 2017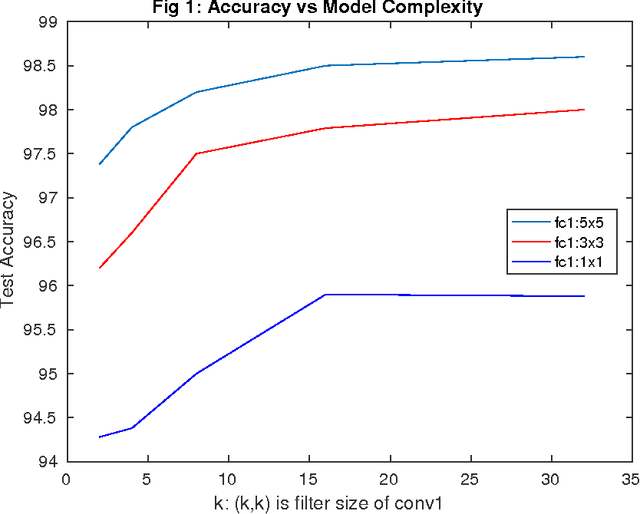
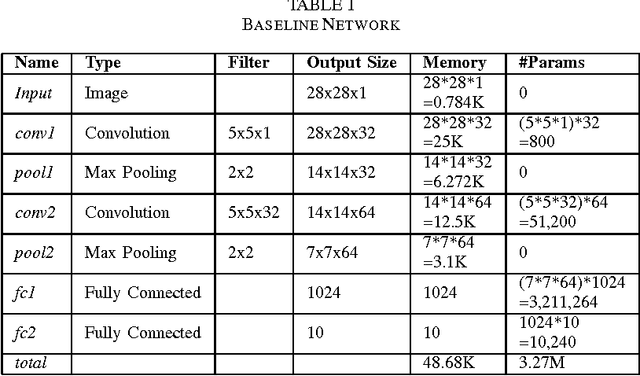
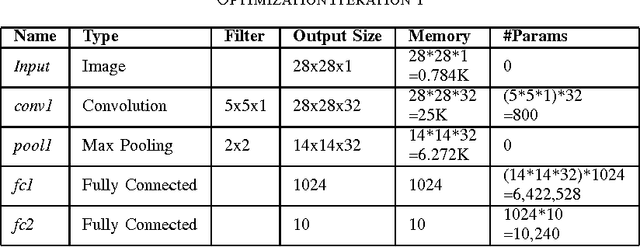
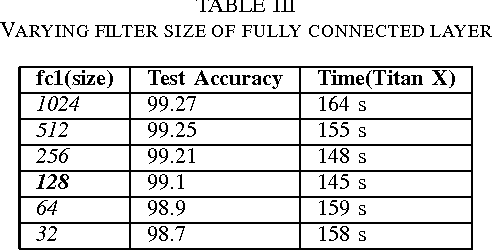
Convolutional Neural Networks(CNN) has had a great success in the recent past, because of the advent of faster GPUs and memory access. CNNs are really powerful as they learn the features from data in layers such that they exhibit the structure of the V-1 features of the human brain. A huge bottleneck, in this case, is that CNNs are very large and have a very high memory footprint, and hence they cannot be employed on devices with limited storage such as mobile phone, IoT etc. In this work, we study the model complexity versus accuracy trade-off on MNSIT dataset, and give a concrete framework for handling such a problem, given the worst case accuracy that a system can tolerate. In our work, we reduce the model complexity by 236 times, and memory footprint by 19.5 times compared to the base model while achieving worst case accuracy threshold.
Face Identification and Clustering
Apr 26, 2017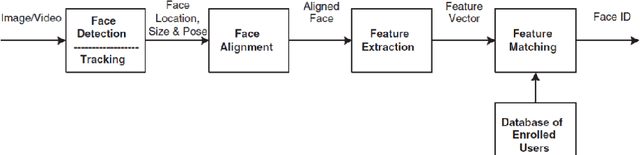
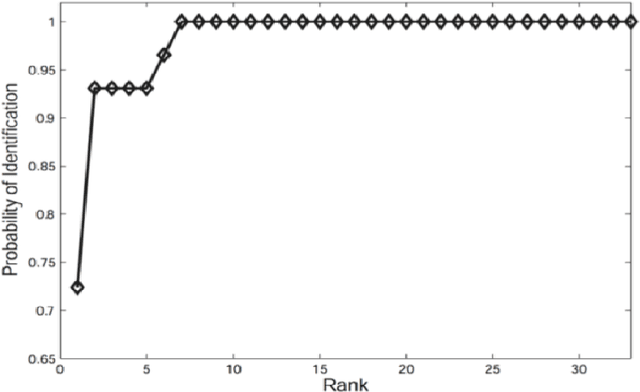

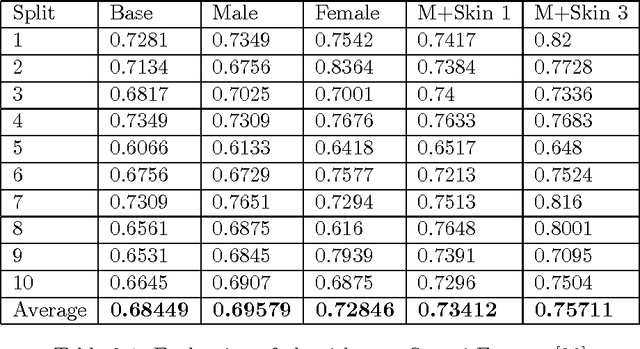
In this thesis, we study two problems based on clustering algorithms. In the first problem, we study the role of visual attributes using an agglomerative clustering algorithm to whittle down the search area where the number of classes is high to improve the performance of clustering. We observe that as we add more attributes, the clustering performance increases overall. In the second problem, we study the role of clustering in aggregating templates in a 1:N open set protocol using multi-shot video as a probe. We observe that by increasing the number of clusters, the performance increases with respect to the baseline and reaches a peak, after which increasing the number of clusters causes the performance to degrade. Experiments are conducted using recently introduced unconstrained IARPA Janus IJB-A, CS2, and CS3 face recognition datasets.