 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling ML Products At Startups: A Practitioner's Guide
Apr 20, 2023How do you scale a machine learning product at a startup? In particular, how do you serve a greater volume, velocity, and variety of queries cost-effectively? We break down costs into variable costs-the cost of serving the model and performant-and fixed costs-the cost of developing and training new models. We propose a framework for conceptualizing these costs, breaking them into finer categories, and limn ways to reduce costs. Lastly, since in our experience, the most expensive fixed cost of a machine learning system is the cost of identifying the root causes of failures and driving continuous improvement, we present a way to conceptualize the issues and share our methodology for the same.
Instate: Predicting the State of Residence From Last Name
Mar 13, 2023
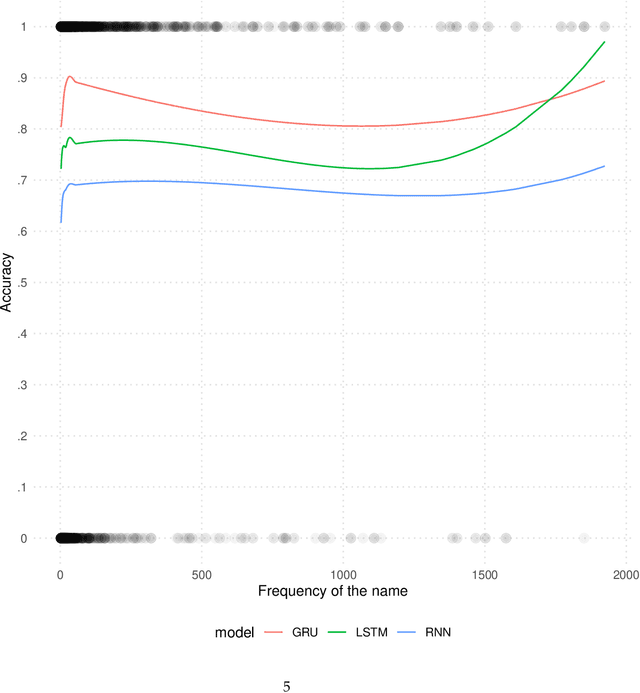
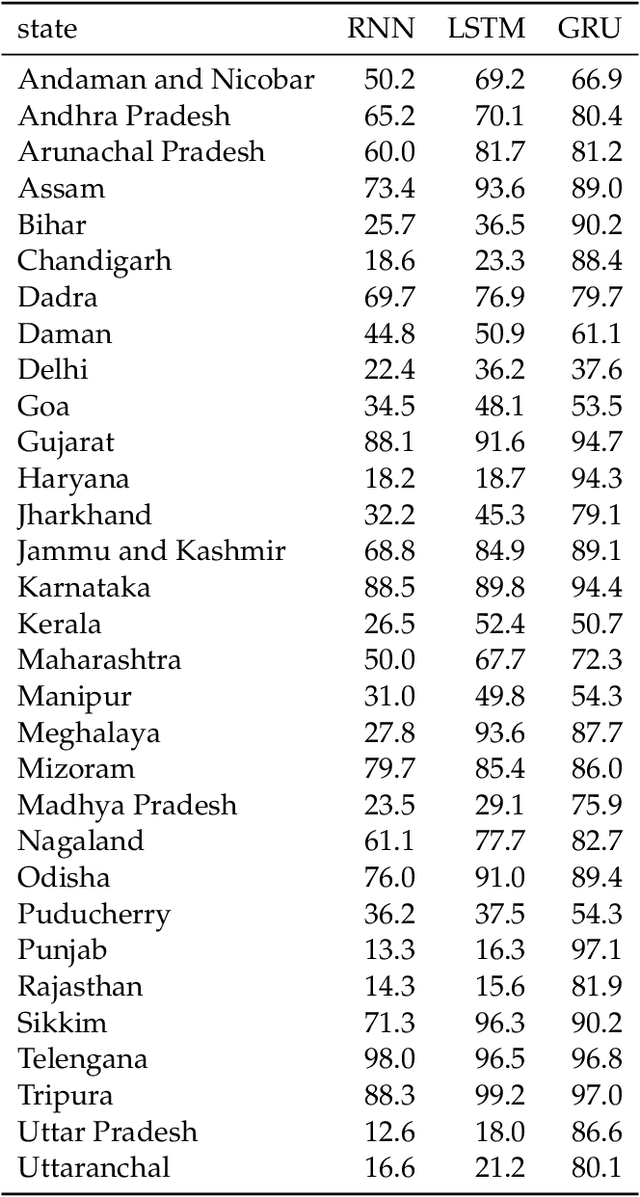
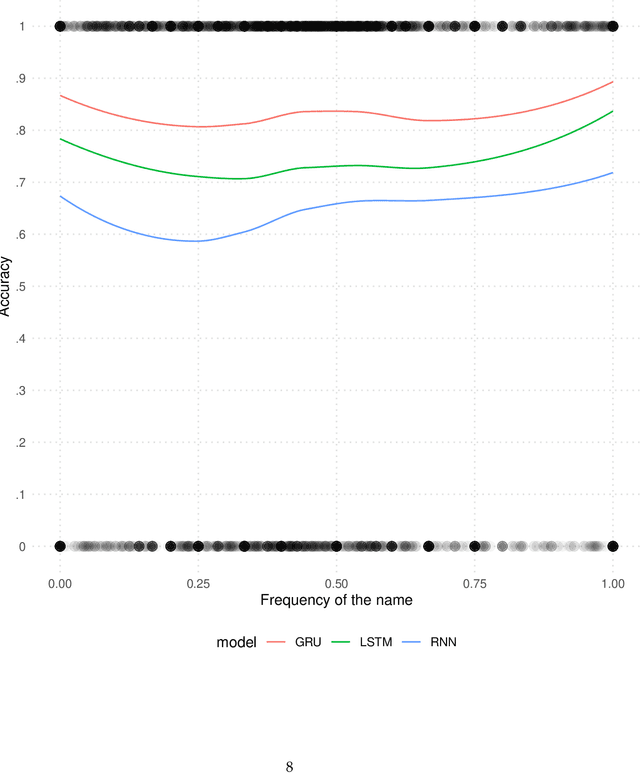
India has twenty-two official languages. Serving such a diverse language base is a challenge for survey statisticians, call center operators, software developers, and other such service providers. To help provide better services to different language communities via better localization, we introduce a new machine learning model that predicts the language(s) that the user can speak from their name. Using nearly 438M records spanning 33 Indian states and 1.13M unique last names from the Indian Electoral Rolls Corpus (?), we build a character-level transformer-based machine-learning model that predicts the state of residence based on the last name. The model has a top-3 accuracy of 85.3% on unseen names. We map the states to languages using the Indian census to infer languages understood by the respondent. We provide open-source software that implements the method discussed in the paper.
Predicting Race and Ethnicity From the Sequence of Characters in a Name
May 05, 2018

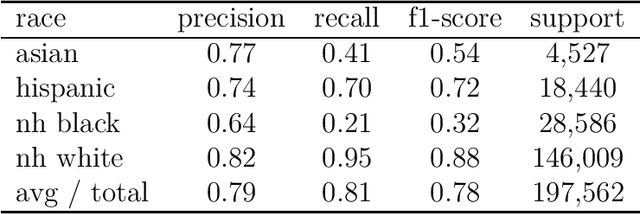
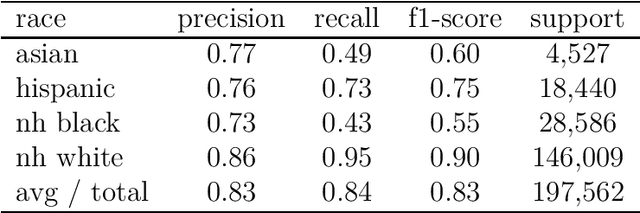
To answer questions about racial inequality, we often need a way to infer race and ethnicity from a name. Until now, a bulk of the focus has been on optimally exploiting the last names list provided by the Census Bureau. But there is more information in the first names, especially for African Americans. To estimate the relationship between full names and race, we exploit the Florida voter registration data and the Wikipedia data. In particular, we model the relationship between the sequence of characters in a name, and race and ethnicity using Long Short Term Memory Networks. Our out of sample (OOS) precision and recall for the full name model estimated on the Florida Voter Registration data is .83 and .84 respectively. This compares to OOS precision and recall of .79 and .81 for the last name only model. Commensurate numbers for Wikipedia data are .73 and .73 for the full name model and .66 and .67 for the last name model. To illustrate the use of this method, we apply our method to the campaign finance data to estimate the share of donations made by people of various racial groups.