 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Vision-based Abnormal Red Blood Cell Classification
Jun 01, 2021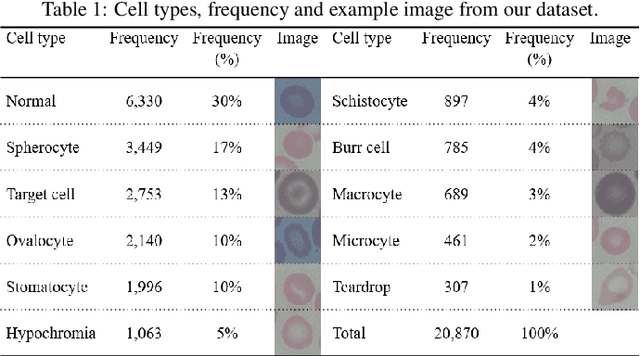
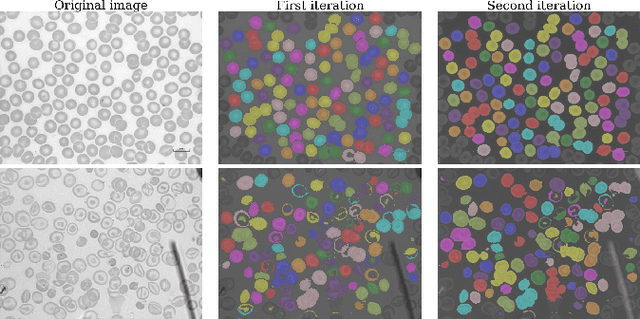
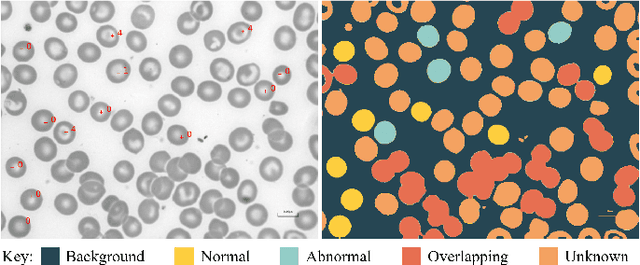
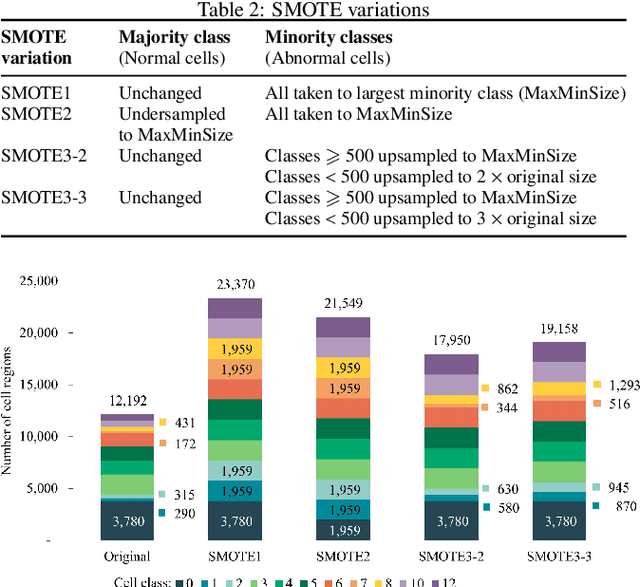
Identification of abnormalities in red blood cells (RBC) is key to diagnosing a range of medical conditions from anaemia to liver disease. Currently this is done manually, a time-consuming and subjective process. This paper presents an automated process utilising the advantages of machine learning to increase capacity and standardisation of cell abnormality detection, and its performance is analysed. Three different machine learning technologies were used: a Support Vector Machine (SVM), a classical machine learning technology; TabNet, a deep learning architecture for tabular data; U-Net, a semantic segmentation network designed for medical image segmentation. A critical issue was the highly imbalanced nature of the dataset which impacts the efficacy of machine learning. To address this, synthesising minority class samples in feature space was investigated via Synthetic Minority Over-sampling Technique (SMOTE) and cost-sensitive learning. A combination of these two methods is investigated to improve the overall performance. These strategies were found to increase sensitivity to minority classes. The impact of unknown cells on semantic segmentation is demonstrated, with some evidence of the model applying learning of labelled cells to these anonymous cells. These findings indicate both classical models and new deep learning networks as promising methods in automating RBC abnormality detection.
Red Blood Cell Segmentation with Overlapping Cell Separation and Classification on Imbalanced Dataset
Dec 09, 2020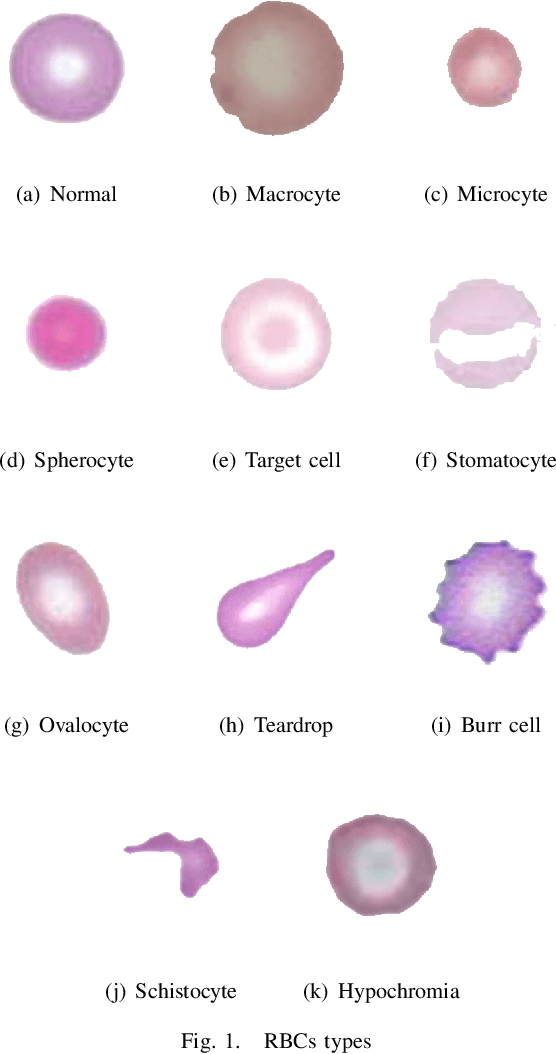
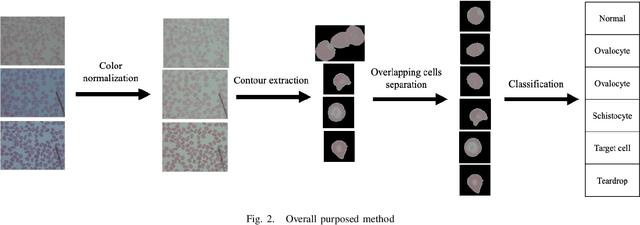


Automated red blood cell classification on blood smear images helps hematologist to analyze RBC lab results in less time and cost. Overlapping cells can cause incorrect predicted results that have to separate into multiple single RBCs before classifying. To classify multiple classes with deep learning, imbalance problems are common in medical imaging because normal samples are always higher than rare disease samples. This paper presents a new method to segment and classify red blood cells from blood smear images, specifically to tackle cell overlapping and data imbalance problems. Focusing on overlapping cell separation, our segmentation process first estimates ellipses to represent red blood cells. The method detects the concave points and then finds the ellipses using directed ellipse fitting. The accuracy is 0.889 on 20 blood smear images. Classification requires balanced training datasets. However, some RBC types are rare. The imbalance ratio is 34.538 on 12 classes with 20,875 individual red blood cell samples. The use of machine learning for RBC classification with an imbalance dataset is hence more challenging than many other applications. We analyze techniques to deal with this problem. The best accuracy and f1 score are 0.921 and 0.8679 on EfficientNet-b1 with augmentation. Experimental results show that the weight balancing technique with augmentation has the potential to deal with imbalance problems by improving the f1 score on minority classes while data augmentation significantly improves the overall classification performance.