 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Analysis and Method for Domain Generalization for a Family of Recurrent Neural Networks
Jan 13, 2026Deep learning (DL) has driven broad advances across scientific and engineering domains. Despite its success, DL models often exhibit limited interpretability and generalization, which can undermine trust, especially in safety-critical deployments. As a result, there is growing interest in (i) analyzing interpretability and generalization and (ii) developing models that perform robustly under data distributions different from those seen during training (i.e. domain generalization). However, the theoretical analysis of DL remains incomplete. For example, many generalization analyses assume independent samples, which is violated in sequential data with temporal correlations. Motivated by these limitations, this paper proposes a method to analyze interpretability and out-of-domain (OOD) generalization for a family of recurrent neural networks (RNNs). Specifically, the evolution of a trained RNN's states is modeled as an unknown, discrete-time, nonlinear closed-loop feedback system. Using Koopman operator theory, these nonlinear dynamics are approximated with a linear operator, enabling interpretability. Spectral analysis is then used to quantify the worst-case impact of domain shifts on the generalization error. Building on this analysis, a domain generalization method is proposed that reduces the OOD generalization error and improves the robustness to distribution shifts. Finally, the proposed analysis and domain generalization approach are validated on practical temporal pattern-learning tasks.
Beamforming Control in RIS-Aided Wireless Communications: A Predictive Physics-Based Approach
Aug 23, 2025Integrating reconfigurable intelligent surfaces (RIS) into wireless communication systems is a promising approach for enhancing coverage and data rates by intelligently redirecting signals, through a process known as beamforming. However, the process of RIS beamforming (or passive beamforming) control is associated with multiple latency-inducing factors. As a result, by the time the beamforming is effectively updated, the channel conditions may have already changed. For example, the low update rate of localization systems becomes a critical limitation, as a mobile UE's position may change significantly between two consecutive measurements. To address this issue, this work proposes a practical and scalable physics-based solution that is effective across a wide range of UE movement models. Specifically, we propose a kinematic observer and predictor to enable proactive RIS control. From low-rate position estimates provided by a localizer, the kinematic observer infers the UE's speed and acceleration. These motion parameters are then used by a predictor to estimate the UE's future positions at a higher rate, allowing the RIS to adjust promptly and compensate for inherent delays in both the RIS control and localization systems. Numerical results validate the effectiveness of the proposed approach, demonstrating real-time RIS adjustments with low computational complexity, even in scenarios involving rapid UE movement.
Koopman-Based Generalization of Deep Reinforcement Learning With Application to Wireless Communications
Mar 04, 2025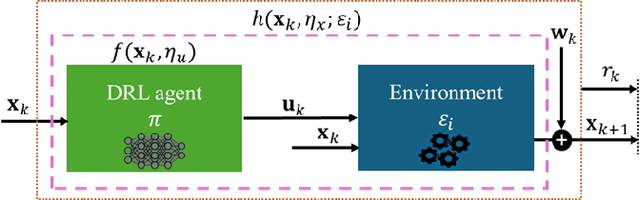
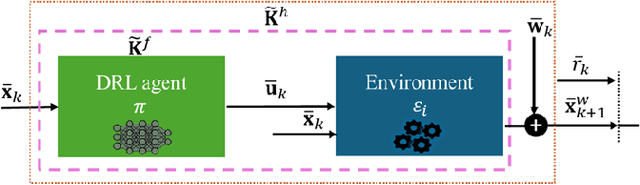
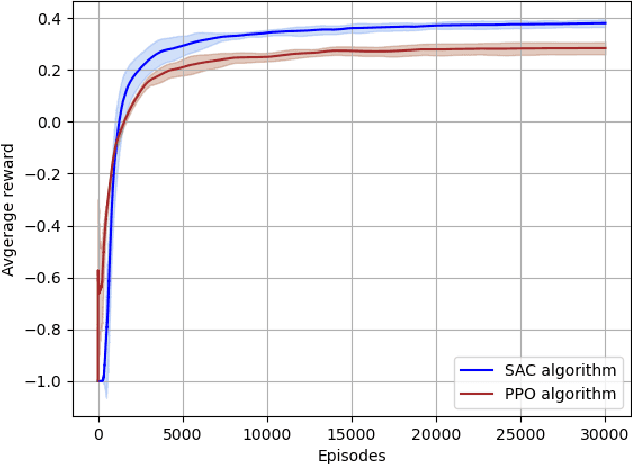
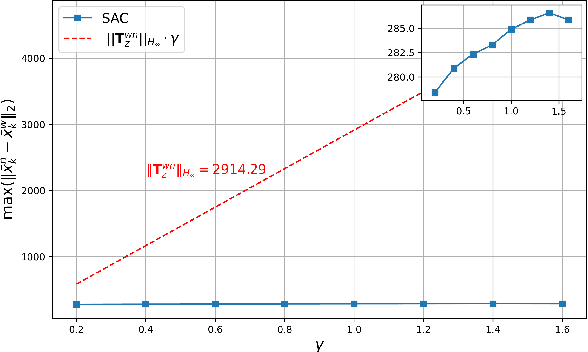
Deep Reinforcement Learning (DRL) is a key machine learning technology driving progress across various scientific and engineering fields, including wireless communication. However, its limited interpretability and generalizability remain major challenges. In supervised learning, generalizability is commonly evaluated through the generalization error using information-theoretic methods. In DRL, the training data is sequential and not independent and identically distributed (i.i.d.), rendering traditional information-theoretic methods unsuitable for generalizability analysis. To address this challenge, this paper proposes a novel analytical method for evaluating the generalizability of DRL. Specifically, we first model the evolution of states and actions in trained DRL algorithms as unknown discrete, stochastic, and nonlinear dynamical functions. Then, we employ a data-driven identification method, the Koopman operator, to approximate these functions, and propose two interpretable representations. Based on these interpretable representations, we develop a rigorous mathematical approach to evaluate the generalizability of DRL algorithms. This approach is formulated using the spectral feature analysis of the Koopman operator, leveraging the H_\infty norm. Finally, we apply this generalization analysis to compare the soft actor-critic method, widely recognized as a robust DRL approach, against the proximal policy optimization algorithm for an unmanned aerial vehicle-assisted mmWave wireless communication scenario.
Science-Informed Deep Learning (ScIDL) With Applications to Wireless Communications
Jun 29, 2024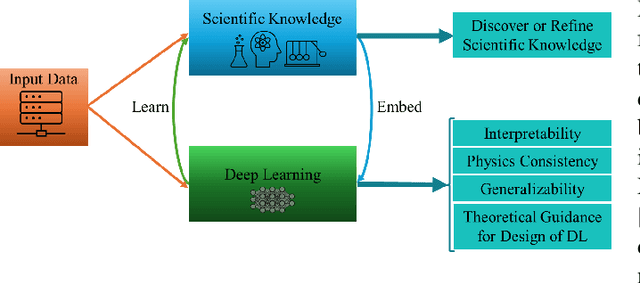
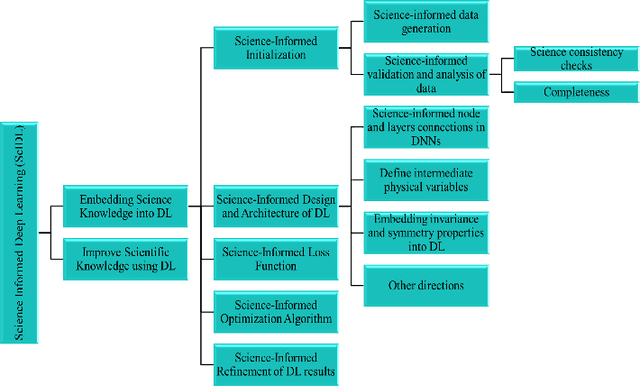
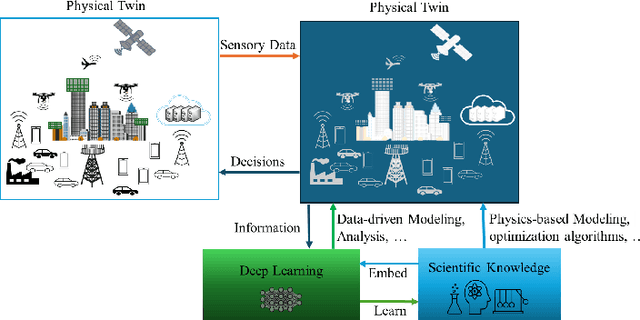
Given the extensive and growing capabilities offered by deep learning (DL), more researchers are turning to DL to address complex challenges in next-generation (xG) communications. However, despite its progress, DL also reveals several limitations that are becoming increasingly evident. One significant issue is its lack of interpretability, which is especially critical for safety-sensitive applications. Another significant consideration is that DL may not comply with the constraints set by physics laws or given security standards, which are essential for reliable DL. Additionally, DL models often struggle outside their training data distributions, which is known as poor generalization. Moreover, there is a scarcity of theoretical guidance on designing DL algorithms. These challenges have prompted the emergence of a burgeoning field known as science-informed DL (ScIDL). ScIDL aims to integrate existing scientific knowledge with DL techniques to develop more powerful algorithms. The core objective of this article is to provide a brief tutorial on ScIDL that illustrates its building blocks and distinguishes it from conventional DL. Furthermore, we discuss both recent applications of ScIDL and potential future research directions in the field of wireless communications.
A Learning Approach for Joint Design of Event-triggered Control and Power-Efficient Resource Allocation
May 14, 2022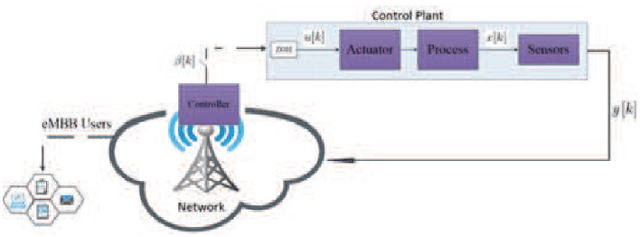

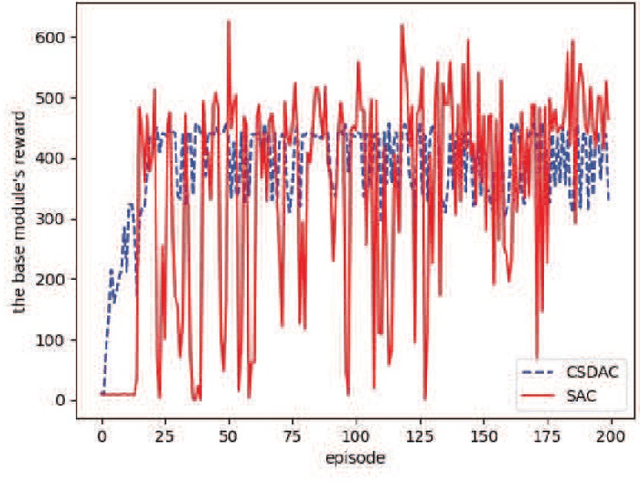
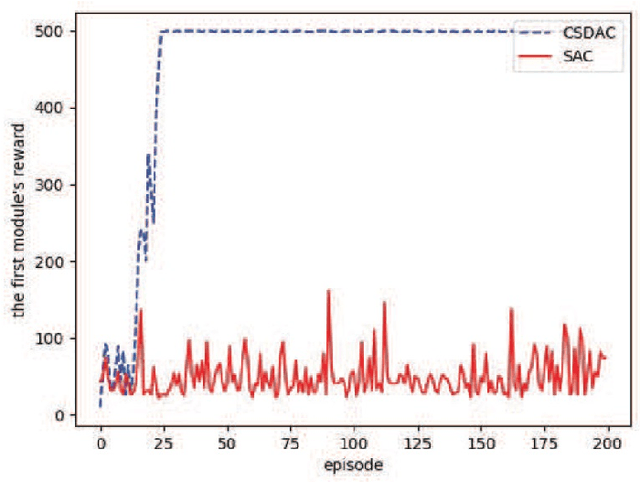
In emerging Industrial Cyber-Physical Systems (ICPSs), the joint design of communication and control sub-systems is essential, as these sub-systems are interconnected. In this paper, we study the joint design problem of an event-triggered control and an energy-efficient resource allocation in a fifth generation (5G) wireless network. We formally state the problem as a multi-objective optimization one, aiming to minimize the number of updates on the actuators' input and the power consumption in the downlink transmission. To address the problem, we propose a model-free hierarchical reinforcement learning approach \textcolor{blue}{with uniformly ultimate boundedness stability guarantee} that learns four policies simultaneously. These policies contain an update time policy on the actuators' input, a control policy, and energy-efficient sub-carrier and power allocation policies. Our simulation results show that the proposed approach can properly control a simulated ICPS and significantly decrease the number of updates on the actuators' input as well as the downlink power consumption.