 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoopman-Based Generalization of Deep Reinforcement Learning With Application to Wireless Communications
Paper and Code
Mar 04, 2025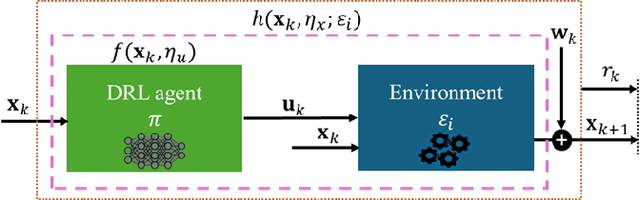
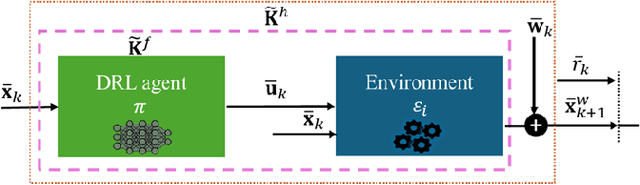
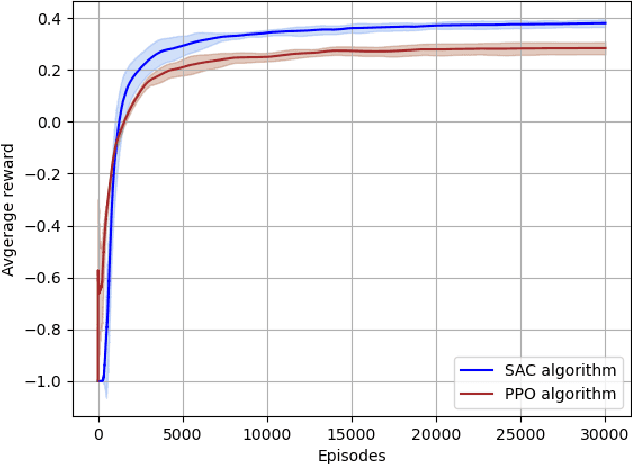
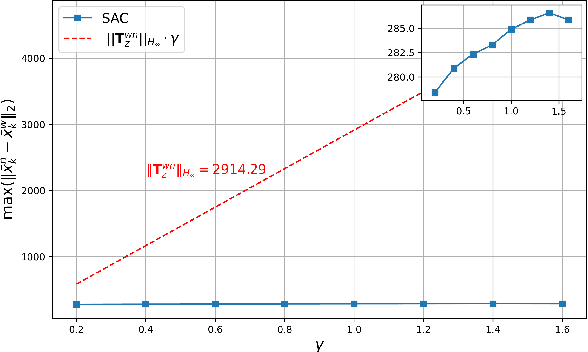
Deep Reinforcement Learning (DRL) is a key machine learning technology driving progress across various scientific and engineering fields, including wireless communication. However, its limited interpretability and generalizability remain major challenges. In supervised learning, generalizability is commonly evaluated through the generalization error using information-theoretic methods. In DRL, the training data is sequential and not independent and identically distributed (i.i.d.), rendering traditional information-theoretic methods unsuitable for generalizability analysis. To address this challenge, this paper proposes a novel analytical method for evaluating the generalizability of DRL. Specifically, we first model the evolution of states and actions in trained DRL algorithms as unknown discrete, stochastic, and nonlinear dynamical functions. Then, we employ a data-driven identification method, the Koopman operator, to approximate these functions, and propose two interpretable representations. Based on these interpretable representations, we develop a rigorous mathematical approach to evaluate the generalizability of DRL algorithms. This approach is formulated using the spectral feature analysis of the Koopman operator, leveraging the H_\infty norm. Finally, we apply this generalization analysis to compare the soft actor-critic method, widely recognized as a robust DRL approach, against the proximal policy optimization algorithm for an unmanned aerial vehicle-assisted mmWave wireless communication scenario.