 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Score Follower for Computer Accompaniment of Polyphonic Musical Instruments
Mar 08, 2025Real-time computer-based accompaniment for human musical performances entails three critical tasks: identifying what the performer is playing, locating their position within the score, and synchronously playing the accompanying parts. Among these, the second task (score following) has been addressed through methods such as dynamic programming on string sequences, Hidden Markov Models (HMMs), and Online Time Warping (OLTW). Yet, the remarkably successful techniques of Deep Learning (DL) have not been directly applied to this problem. Therefore, we introduce HeurMiT, a novel DL-based score-following framework, utilizing a neural architecture designed to learn compressed latent representations that enables precise performer tracking despite deviations from the score. Parallelly, we implement a real-time MIDI data augmentation toolkit, aimed at enhancing the robustness of these learned representations. Additionally, we integrate the overall system with simple heuristic rules to create a comprehensive framework that can interface seamlessly with existing transcription and accompaniment technologies. However, thorough experimentation reveals that despite its impressive computational efficiency, HeurMiT's underlying limitations prevent it from being practical in real-world score following scenarios. Consequently, we present our work as an introductory exploration into the world of DL-based score followers, while highlighting some promising avenues to encourage future research towards robust, state-of-the-art neural score following systems.
Exploring Domain-Specific Enhancements for a Neural Foley Synthesizer
Sep 08, 2023



Foley sound synthesis refers to the creation of authentic, diegetic sound effects for media, such as film or radio. In this study, we construct a neural Foley synthesizer capable of generating mono-audio clips across seven predefined categories. Our approach introduces multiple enhancements to existing models in the text-to-audio domain, with the goal of enriching the diversity and acoustic characteristics of the generated foleys. Notably, we utilize a pre-trained encoder that retains acoustical and musical attributes in intermediate embeddings, implement class-conditioning to enhance differentiability among foley classes in their intermediate representations, and devise an innovative transformer-based architecture for optimizing self-attention computations on very large inputs without compromising valuable information. Subsequent to implementation, we present intermediate outcomes that surpass the baseline, discuss practical challenges encountered in achieving optimal results, and outline potential pathways for further research.
Real-Time Detection of Drowsiness Among Vehicle Drivers: A Machine Learning Algorithm for Embedded Systems
Nov 04, 2021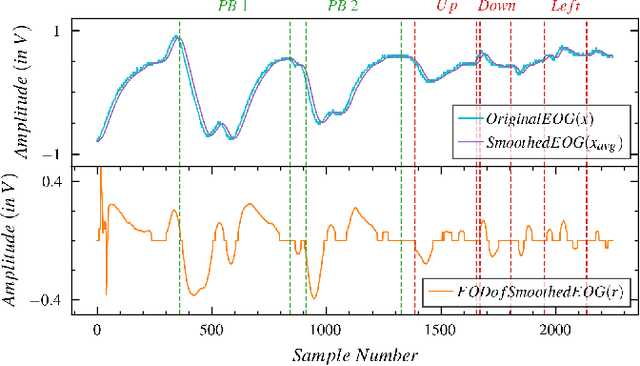
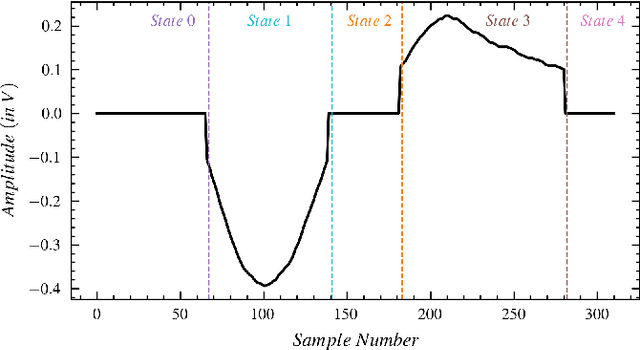
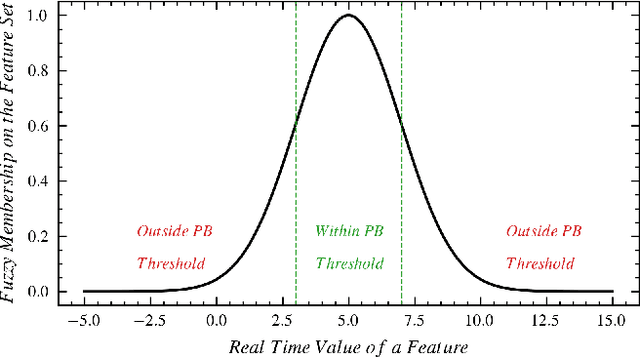

Numerous studies have established the necessity for developing safety equipment to detect drowsiness among vehicle drivers. However, for reliable implementations, such systems must employ dependable sources of stimuli; through Electrooculography (EOG), the tendencies of drowsiness can be directly sensed by measuring blinks of prolonged durations. While conventional machine learning (ML) algorithms can be utilized for the detection and classification of these prolonged blinks (PB), executing them on microcontroller units (MCU) may prove to be a laborious task. Hence, by keeping resource constraints and practicality in mind, an ML algorithm is proposed in this study to identify PBs executed by an individual with desirable accuracy and precision while being efficient enough to be deployed on portable wearables using economic MCUs. Furthermore, the suggested algorithm is subjected to multiple rounds of testing in this study thereby, establishing its possibility as a feasible drowsiness detection measure for wearable systems.
An Audio Synthesis Framework Derived from Industrial Process Control
Sep 21, 2021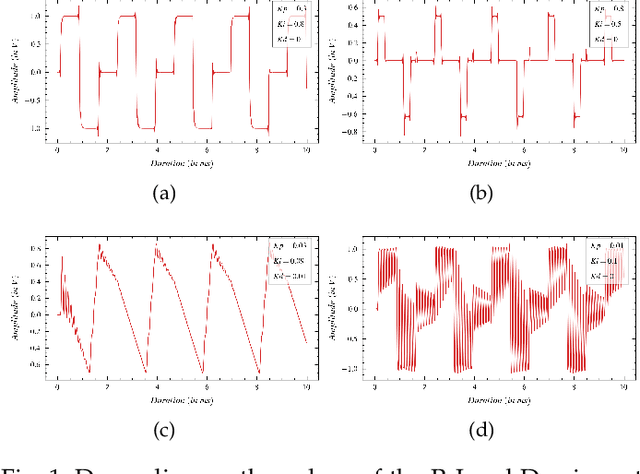



Since its conception, digital synthesis has significantly influenced the advancement of music, leading to new genres and production styles. Through existing synthesis techniques, one can recreate naturally occurring sounds as well as generate innovative artificial timbres. However, research in audio technology continues to pursue new methods of synthesizing sounds, keeping the transformation of music constant. This research attempts to formulate the framework of a new synthesis technique by redefining the popular Proportional-Integral-Derivative (PID) algorithm used in feedback-based process control. The framework is then implemented as a Python application to study the available control parameters and their effect on the synthesized output. Further, applications of this technique as an audio signal and LFO generator, including its potentiality as an alternative to FM and Wavetable synthesis techniques, are studied in detail. The research concludes by highlighting some of the imperfections in the current framework and the possible research directions to be considered to address them.
An Audio Envelope Generator Derived from Industrial Process Control
Jun 26, 2021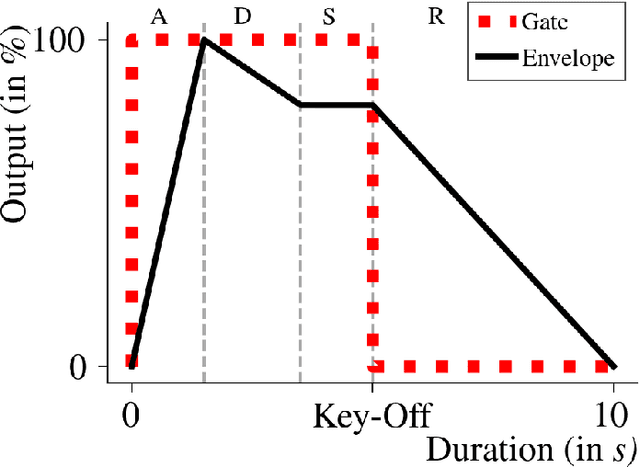
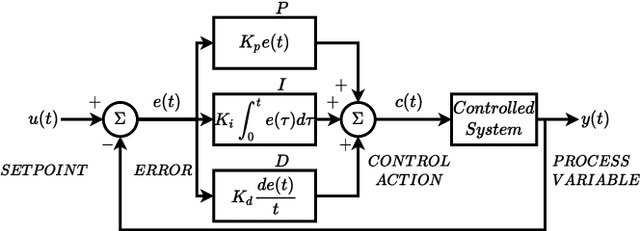
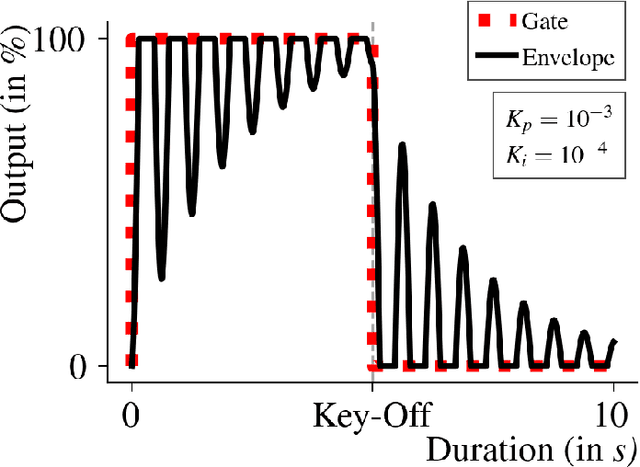
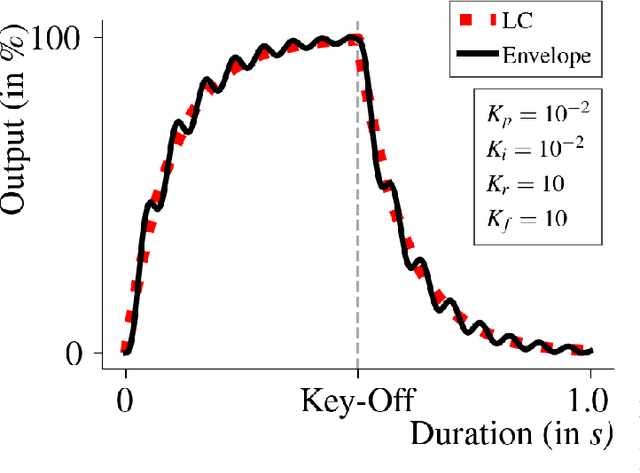
Audio envelopes serve a crucial role in ensuring the versatility of synthesizers in producing timbres. To this end, the Attack, Decay, Release and Sustain (ADSR) envelope generator and its derivatives have been established as a mainstay in modern music. However, there may be merit in exploring alternate techniques to produce envelopes that could not only resemble ADSR but also be used to create novel timbres. Consequently, an attempt is made in this research to formulate the framework of a new envelope generator by redefining the Proportional-Integral-Derivative (PID) algorithm used in feedback-based process control. Additionally, a detailed analysis is made on the modes of operation and the nature of envelopes thus generated to establish it as a potential harbinger of distinctive styles of music.