 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Thin-Film Wafer Inspection With A Multi-Sensor Array And Robot Constraint Maintenance
Mar 07, 2025Thin-film inspection on large-area substrates in coating manufacture remains a critical parameter to ensure product quality; however, extending the inspection process precisely over a large area presents major challenges, due to the limitations of the available inspection equipment. An additional manipulation problem arises when automating the inspection process, as the silicon wafer requires movement constraints to ensure accurate measurements and to prevent damage. Furthermore, there are other increasingly important large-area industrial applications, such as Roll-to-Roll (R2R) manufacturing where coating thickness inspection introduces additional challenges. This paper presents an autonomous inspection system using a robotic manipulator with a novel learned constraint manifold to control a wafer to its calibration point, and a novel multi-sensor array with high potential for scalability into large substrate areas. We demonstrate that the manipulator can perform required motions whilst adhering to movement constraints. We further demonstrate that the sensor array can perform thickness measurements statically with an error of $<2\%$ compared to a commercial reflectometer, and through the use of a manipulator can dynamically detect angle variations $>0.5^\circ$ from the calibration point whilst monitoring the RMSE and $R^2$ over 1406 data points. These features are potentially useful for detecting displacement variations in R2R manufacturing processes.
Leveraging power of deep learning for fast and efficient elite pixel selection in time series SAR interferometry
Feb 26, 2024



This work proposes an improved convolutional long short-term memory (ConvLSTM) based architecture for selection of elite pixels (i.e., less noisy) in time series interferometric synthetic aperture radar (TS-InSAR). Compared to previous version, the model can process InSAR stacks of variable time steps and select both persistent (PS) and distributed scatterers (DS). We trained the model on ~20,000 training images (interferograms), each of size 100 by 100 pixels, extracted from InSAR time series interferograms containing both artificial features (buildings and infrastructure) and objects of natural environment (vegetation, forests, barren or agricultural land, water bodies). Based on such categorization, we developed two deep learning models, primarily focusing on urban and coastal sites. Training labels were generated from elite pixel selection outputs generated from the wavelet-based InSAR (WabInSAR) software developed by Shirzaei (2013) and improved in Lee and Shirzaei (2023). With 4 urban and 7 coastal sites used for training and validation, the predicted elite pixel selection maps reveal that the proposed models efficiently learn from WabInSAR-generated labels, reaching a validation accuracy of 94%. The models accurately discard pixels affected by geometric and temporal decorrelation while selecting pixels corresponding to urban objects and those with stable phase history unaffected by temporal and geometric decorrelation. The density of pixels in urban areas is comparable to and higher for coastal areas compared to WabInSAR outputs. With significantly reduced time computation (order of minutes) and improved selection of elite pixels, the proposed models can efficiently process long InSAR time series stacks and generate rapid deformation maps.
Trustworthy, responsible, ethical AI in manufacturing and supply chains: synthesis and emerging research questions
May 19, 2023While the increased use of AI in the manufacturing sector has been widely noted, there is little understanding on the risks that it may raise in a manufacturing organisation. Although various high level frameworks and definitions have been proposed to consolidate potential risks, practitioners struggle with understanding and implementing them. This lack of understanding exposes manufacturing to a multitude of risks, including the organisation, its workers, as well as suppliers and clients. In this paper, we explore and interpret the applicability of responsible, ethical, and trustworthy AI within the context of manufacturing. We then use a broadened adaptation of a machine learning lifecycle to discuss, through the use of illustrative examples, how each step may result in a given AI trustworthiness concern. We additionally propose a number of research questions to the manufacturing research community, in order to help guide future research so that the economic and societal benefits envisaged by AI in manufacturing are delivered safely and responsibly.
Learning semantic Image attributes using Image recognition and knowledge graph embeddings
Sep 12, 2020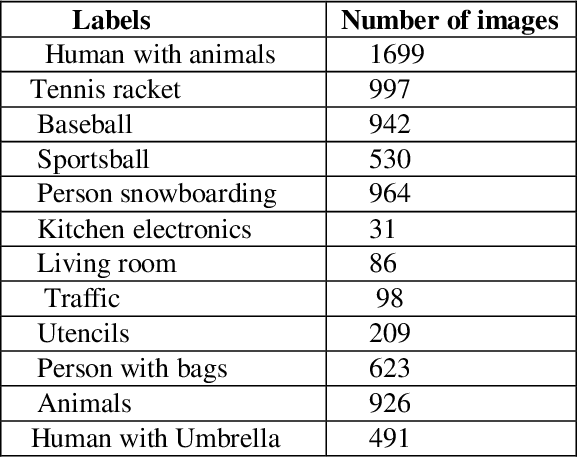
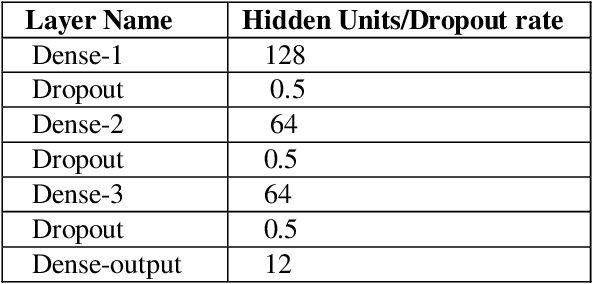
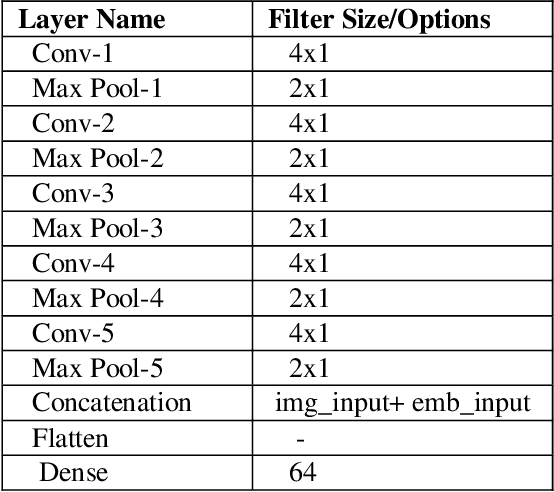
Extracting structured knowledge from texts has traditionally been used for knowledge base generation. However, other sources of information, such as images can be leveraged into this process to build more complete and richer knowledge bases. Structured semantic representation of the content of an image and knowledge graph embeddings can provide a unique representation of semantic relationships between image entities. Linking known entities in knowledge graphs and learning open-world images using language models has attracted lots of interest over the years. In this paper, we propose a shared learning approach to learn semantic attributes of images by combining a knowledge graph embedding model with the recognized attributes of images. The proposed model premises to help us understand the semantic relationship between the entities of an image and implicitly provide a link for the extracted entities through a knowledge graph embedding model. Under the limitation of using a custom user-defined knowledge base with limited data, the proposed model presents significant accuracy and provides a new alternative to the earlier approaches. The proposed approach is a step towards bridging the gap between frameworks which learn from large amounts of data and frameworks which use a limited set of predicates to infer new knowledge.
Deep learning networks for selection of persistent scatterer pixels in multi-temporal SAR interferometric processing
Sep 05, 2019



In multi-temporal SAR interferometry (MT-InSAR), persistent scatterer (PS) pixels are used to estimate geophysical parameters, essentially deformation. Conventionally, PS pixels are selected on the basis of the estimated noise present in the spatially uncorrelated phase component along with look-angle error in a temporal interferometric stack. In this study, two deep learning architectures, namely convolutional neural network for interferometric semantic segmentation (CNN-ISS) and convolutional long short term memory network for interferometric semantic segmentation (CLSTM-ISS), based on learning spatial and spatio-temporal behaviour respectively, were proposed for selection of PS pixels. These networks were trained to relate the interferometric phase history to its classification into phase stable (PS) and phase unstable (non-PS) measurement pixels using ~10,000 real world interferometric images of different study sites containing man-made objects, forests, vegetation, uncropped land, water bodies, and areas affected by lengthening, foreshortening, layover and shadowing. The networks were trained using training labels obtained from the Stanford method for Persistent Scatterer Interferometry (StaMPS) algorithm. However, pixel selection results, when compared to a combination of R-index and a classified image of the test dataset, reveal that CLSTM-ISS estimates improved the classification of PS and non-PS pixels compared to those of StaMPS and CNN-ISS. The predicted results show that CLSTM-ISS reached an accuracy of 93.50%, higher than that of CNN-ISS (89.21%). CLSTM-ISS also improved the density of reliable PS pixels compared to StaMPS and CNN-ISS and outperformed StaMPS and other conventional MT-InSAR methods in terms of computational efficiency.