 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConnectivity structure and dynamics of nonlinear recurrent neural networks
Sep 03, 2024



We develop a theory to analyze how structure in connectivity shapes the high-dimensional, internally generated activity of nonlinear recurrent neural networks. Using two complementary methods -- a path-integral calculation of fluctuations around the saddle point, and a recently introduced two-site cavity approach -- we derive analytic expressions that characterize important features of collective activity, including its dimensionality and temporal correlations. To model structure in the coupling matrices of real neural circuits, such as synaptic connectomes obtained through electron microscopy, we introduce the random-mode model, which parameterizes a coupling matrix using random input and output modes and a specified spectrum. This model enables systematic study of the effects of low-dimensional structure in connectivity on neural activity. These effects manifest in features of collective activity, that we calculate, and can be undetectable when analyzing only single-neuron activities. We derive a relation between the effective rank of the coupling matrix and the dimension of activity. By extending the random-mode model, we compare the effects of single-neuron heterogeneity and low-dimensional connectivity. We also investigate the impact of structured overlaps between input and output modes, a feature of biological coupling matrices. Our theory provides tools to relate neural-network architecture and collective dynamics in artificial and biological systems.
Dimension of Activity in Random Neural Networks
Aug 07, 2022

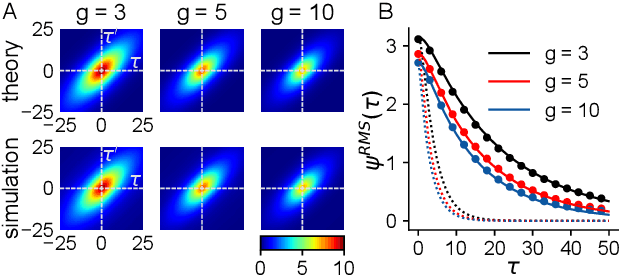
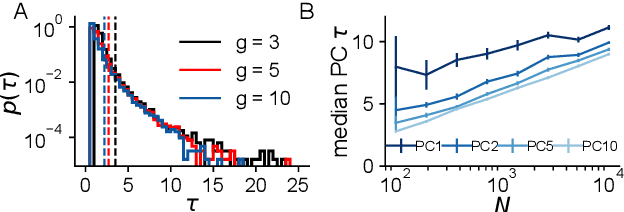
Neural networks are high-dimensional nonlinear dynamical systems that process information through the coordinated activity of many interconnected units. Understanding how biological and machine-learning networks function and learn requires knowledge of the structure of this coordinated activity, information contained in cross-covariances between units. Although dynamical mean field theory (DMFT) has elucidated several features of random neural networks -- in particular, that they can generate chaotic activity -- existing DMFT approaches do not support the calculation of cross-covariances. We solve this longstanding problem by extending the DMFT approach via a two-site cavity method. This reveals, for the first time, several spatial and temporal features of activity coordination, including the effective dimension, defined as the participation ratio of the spectrum of the covariance matrix. Our results provide a general analytical framework for studying the structure of collective activity in random neural networks and, more broadly, in high-dimensional nonlinear dynamical systems with quenched disorder.
Action-modulated midbrain dopamine activity arises from distributed control policies
Jul 01, 2022
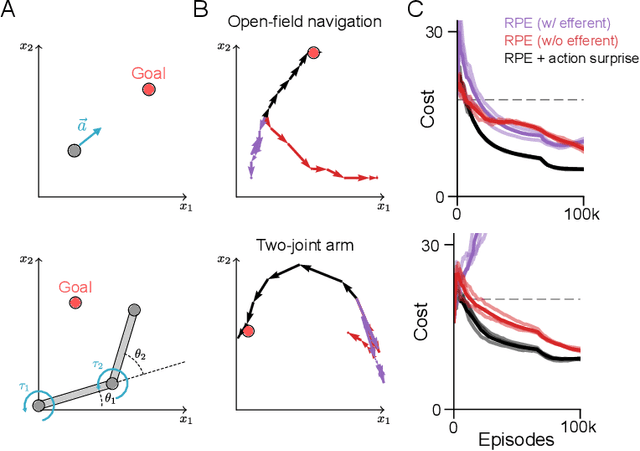


Animal behavior is driven by multiple brain regions working in parallel with distinct control policies. We present a biologically plausible model of off-policy reinforcement learning in the basal ganglia, which enables learning in such an architecture. The model accounts for action-related modulation of dopamine activity that is not captured by previous models that implement on-policy algorithms. In particular, the model predicts that dopamine activity signals a combination of reward prediction error (as in classic models) and "action surprise," a measure of how unexpected an action is relative to the basal ganglia's current policy. In the presence of the action surprise term, the model implements an approximate form of Q-learning. On benchmark navigation and reaching tasks, we show empirically that this model is capable of learning from data driven completely or in part by other policies (e.g. from other brain regions). By contrast, models without the action surprise term suffer in the presence of additional policies, and are incapable of learning at all from behavior that is completely externally driven. The model provides a computational account for numerous experimental findings about dopamine activity that cannot be explained by classic models of reinforcement learning in the basal ganglia. These include differing levels of action surprise signals in dorsal and ventral striatum, decreasing amounts movement-modulated dopamine activity with practice, and representations of action initiation and kinematics in dopamine activity. It also provides further predictions that can be tested with recordings of striatal dopamine activity.
Learning to Learn with Feedback and Local Plasticity
Jun 16, 2020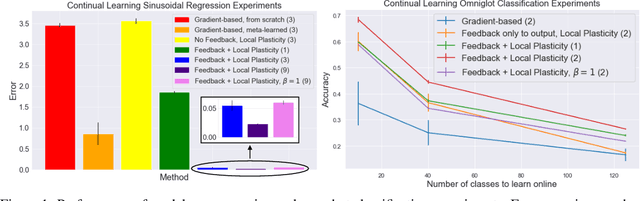
Interest in biologically inspired alternatives to backpropagation is driven by the desire to both advance connections between deep learning and neuroscience and address backpropagation's shortcomings on tasks such as online, continual learning. However, local synaptic learning rules like those employed by the brain have so far failed to match the performance of backpropagation in deep networks. In this study, we employ meta-learning to discover networks that learn using feedback connections and local, biologically inspired learning rules. Importantly, the feedback connections are not tied to the feedforward weights, avoiding biologically implausible weight transport. Our experiments show that meta-trained networks effectively use feedback connections to perform online credit assignment in multi-layer architectures. Surprisingly, this approach matches or exceeds a state-of-the-art gradient-based online meta-learning algorithm on regression and classification tasks, excelling in particular at continual learning. Analysis of the weight updates employed by these models reveals that they differ qualitatively from gradient descent in a way that reduces interference between updates. Our results suggest the existence of a class of biologically plausible learning mechanisms that not only match gradient descent-based learning, but also overcome its limitations.
Feedback alignment in deep convolutional networks
Dec 12, 2018

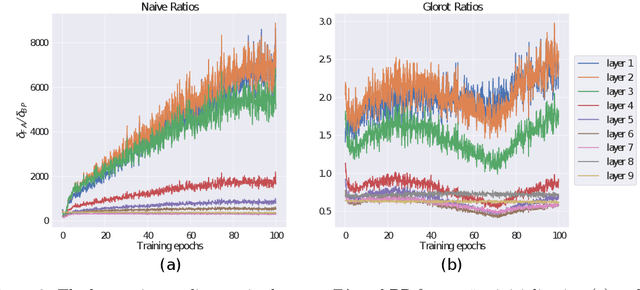

Ongoing studies have identified similarities between neural representations in biological networks and in deep artificial neural networks. This has led to renewed interest in developing analogies between the backpropagation learning algorithm used to train artificial networks and the synaptic plasticity rules operative in the brain. These efforts are challenged by biologically implausible features of backpropagation, one of which is a reliance on symmetric forward and backward synaptic weights. A number of methods have been proposed that do not rely on weight symmetry but, thus far, these have failed to scale to deep convolutional networks and complex data. We identify principal obstacles to the scalability of such algorithms and introduce several techniques to mitigate them. We demonstrate that a modification of the feedback alignment method that enforces a weaker form of weight symmetry, one that requires agreement of weight sign but not magnitude, can achieve performance competitive with backpropagation. Our results complement those of Bartunov et al. (2018) and Xiao et al. (2018b) and suggest that mechanisms that promote alignment of feedforward and feedback weights are critical for learning in deep networks.