 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrapping Relation Extractors using Syntactic Search by Examples
Feb 09, 2021
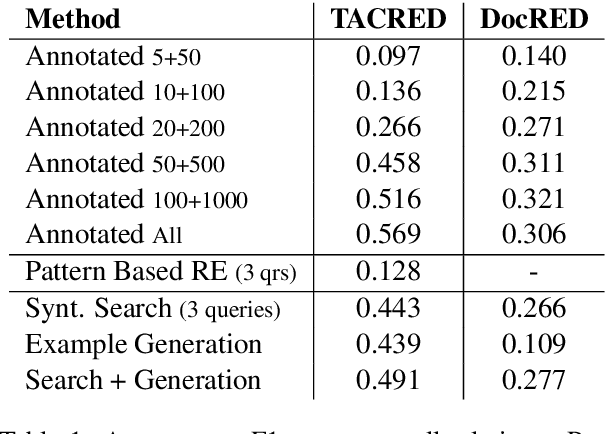
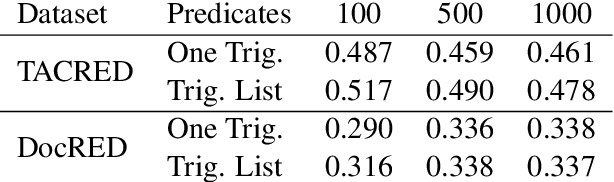
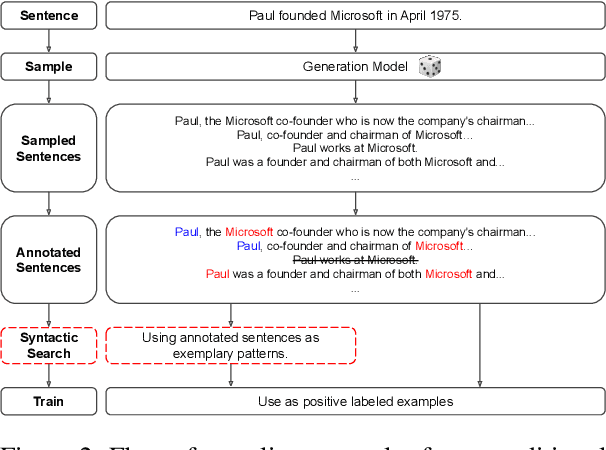
The advent of neural-networks in NLP brought with it substantial improvements in supervised relation extraction. However, obtaining a sufficient quantity of training data remains a key challenge. In this work we propose a process for bootstrapping training datasets which can be performed quickly by non-NLP-experts. We take advantage of search engines over syntactic-graphs (Such as Shlain et al. (2020)) which expose a friendly by-example syntax. We use these to obtain positive examples by searching for sentences that are syntactically similar to user input examples. We apply this technique to relations from TACRED and DocRED and show that the resulting models are competitive with models trained on manually annotated data and on data obtained from distant supervision. The models also outperform models trained using NLG data augmentation techniques. Extending the search-based approach with the NLG method further improves the results.
A simple geometric proof for the benefit of depth in ReLU networks
Jan 18, 2021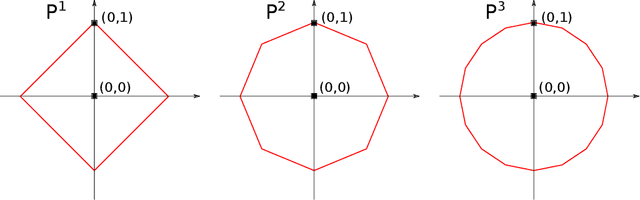
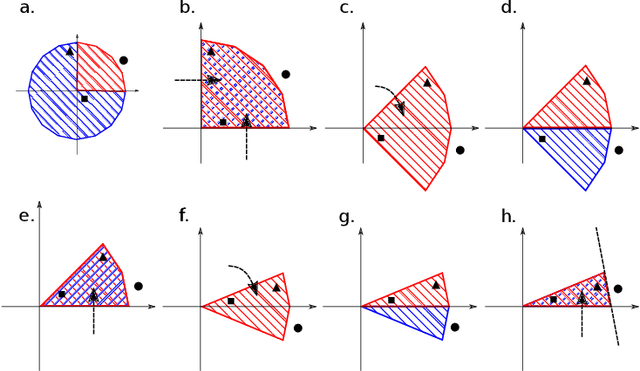
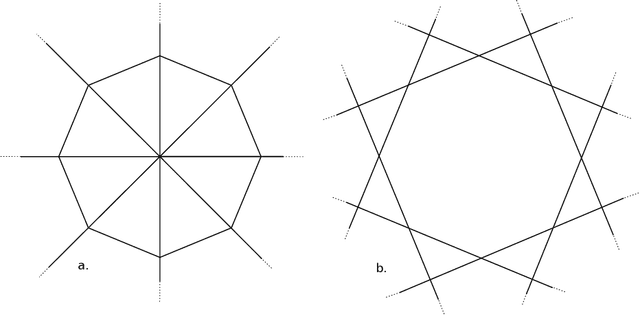
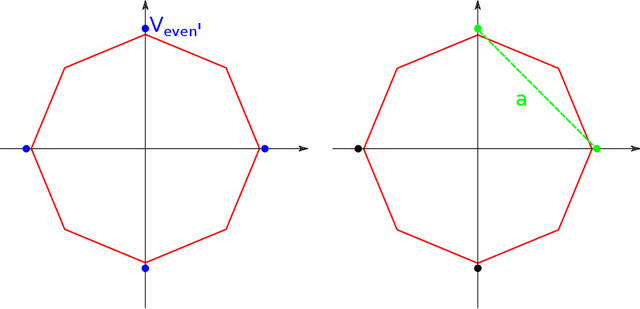
We present a simple proof for the benefit of depth in multi-layer feedforward network with rectified activation ("depth separation"). Specifically we present a sequence of classification problems indexed by $m$ such that (a) for any fixed depth rectified network there exist an $m$ above which classifying problem $m$ correctly requires exponential number of parameters (in $m$); and (b) for any problem in the sequence, we present a concrete neural network with linear depth (in $m$) and small constant width ($\leq 4$) that classifies the problem with zero error. The constructive proof is based on geometric arguments and a space folding construction. While stronger bounds and results exist, our proof uses substantially simpler tools and techniques, and should be accessible to undergraduate students in computer science and people with similar backgrounds.
Towards better substitution-based word sense induction
May 31, 2019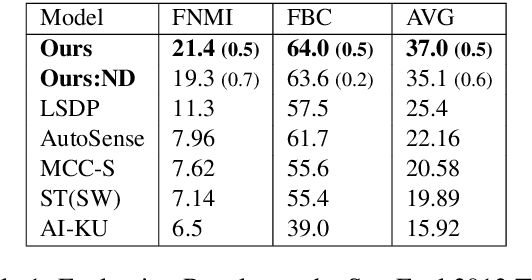


Word sense induction (WSI) is the task of unsupervised clustering of word usages within a sentence to distinguish senses. Recent work obtain strong results by clustering lexical substitutes derived from pre-trained RNN language models (ELMo). Adapting the method to BERT improves the scores even further. We extend the previous method to support a dynamic rather than a fixed number of clusters as supported by other prominent methods, and propose a method for interpreting the resulting clusters by associating them with their most informative substitutes. We then perform extensive error analysis revealing the remaining sources of errors in the WSI task. Our code is available at https://github.com/asafamr/bertwsi.
Word Sense Induction with Neural biLM and Symmetric Patterns
Aug 30, 2018



An established method for Word Sense Induction (WSI) uses a language model to predict probable substitutes for target words, and induces senses by clustering these resulting substitute vectors. We replace the ngram-based language model (LM) with a recurrent one. Beyond being more accurate, the use of the recurrent LM allows us to effectively query it in a creative way, using what we call dynamic symmetric patterns. The combination of the RNN-LM and the dynamic symmetric patterns results in strong substitute vectors for WSI, allowing to surpass the current state-of-the-art on the SemEval 2013 WSI shared task by a large margin.