 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Combination Framework for Dependent Tests with Applications to Microbiome Association Studies
Apr 14, 2024We introduce a novel meta-analysis framework to combine dependent tests under a general setting, and utilize it to synthesize various microbiome association tests that are calculated from the same dataset. Our development builds upon the classical meta-analysis methods of aggregating $p$-values and also a more recent general method of combining confidence distributions, but makes generalizations to handle dependent tests. The proposed framework ensures rigorous statistical guarantees, and we provide a comprehensive study and compare it with various existing dependent combination methods. Notably, we demonstrate that the widely used Cauchy combination method for dependent tests, referred to as the vanilla Cauchy combination in this article, can be viewed as a special case within our framework. Moreover, the proposed framework provides a way to address the problem when the distributional assumptions underlying the vanilla Cauchy combination are violated. Our numerical results demonstrate that ignoring the dependence among the to-be-combined components may lead to a severe size distortion phenomenon. Compared to the existing $p$-value combination methods, including the vanilla Cauchy combination method, the proposed combination framework can handle the dependence accurately and utilizes the information efficiently to construct tests with accurate size and enhanced power. The development is applied to Microbiome Association Studies, where we aggregate information from multiple existing tests using the same dataset. The combined tests harness the strengths of each individual test across a wide range of alternative spaces, %resulting in a significant enhancement of testing power across a wide range of alternative spaces, enabling more efficient and meaningful discoveries of vital microbiome associations.
Calibrating Black Box Classification Models through the Thresholding Method
Jun 05, 2017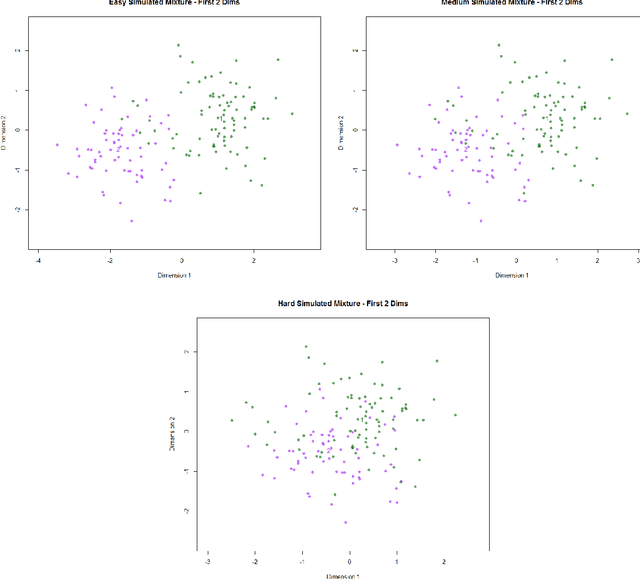

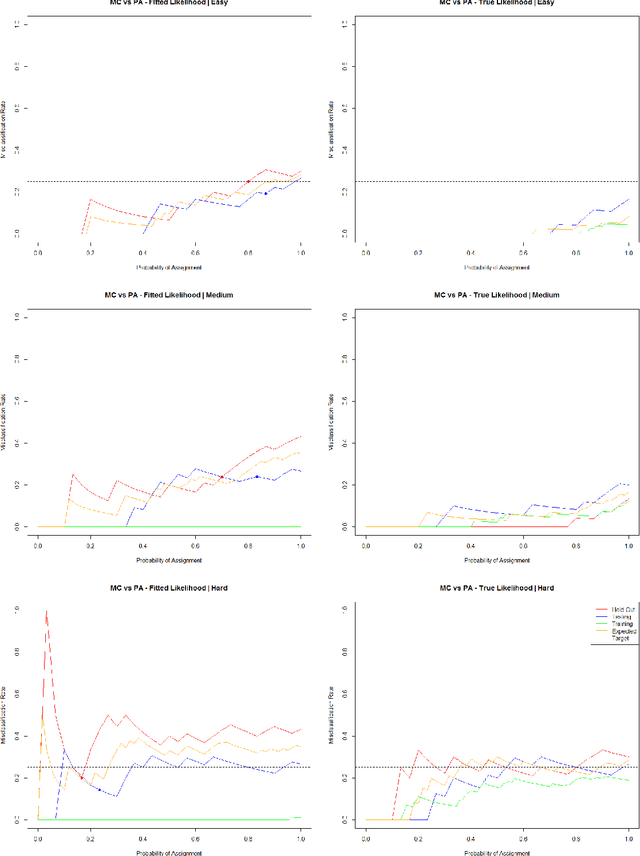

In high-dimensional classification settings, we wish to seek a balance between high power and ensuring control over a desired loss function. In many settings, the points most likely to be misclassified are those who lie near the decision boundary of the given classification method. Often, these uninformative points should not be classified as they are noisy and do not exhibit strong signals. In this paper, we introduce the Thresholding Method to parameterize the problem of determining which points exhibit strong signals and should be classified. We demonstrate the empirical performance of this novel calibration method in providing loss function control at a desired level, as well as explore how the method assuages the effect of overfitting. We explore the benefits of error control through the Thresholding Method in difficult, high-dimensional, simulated settings. Finally, we show the flexibility of the Thresholding Method through applying the method in a variety of real data settings.