 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-effective vibration analysis through data-backed pipeline optimisation
Aug 16, 2021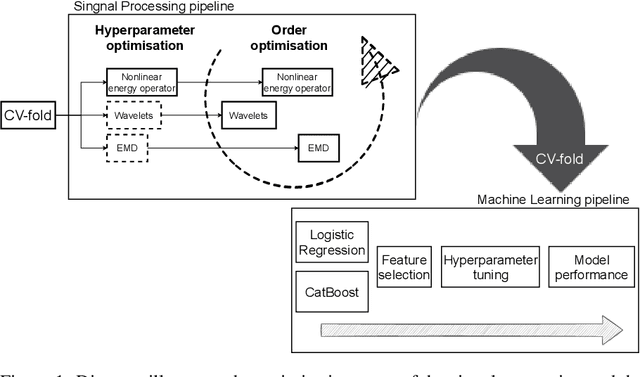

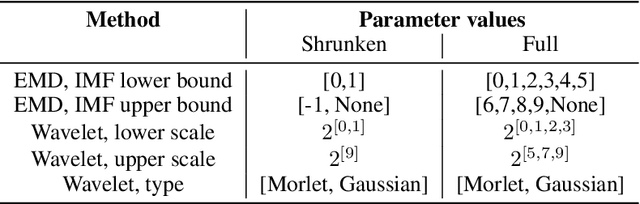
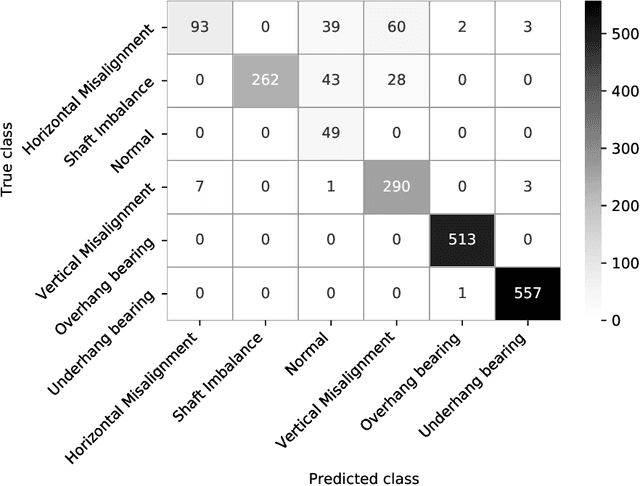
Vibration analysis is an active area of research, aimed, among other targets, at an accurate classification of machinery failure modes. This often leads to complex and convoluted signal processing pipeline designs, which are computationally demanding and cannot be deployed in the Edge devices. In the current work, we address this issue by proposing a data-driven methodology that allows optimising and justifying the complexity of the signal processing pipelines. Additionally, aiming to make IoT vibration analysis systems more cost- and computationally effective, on the example of MAFAULDA vibration dataset, we assess the changes in the failure classification performance at low sampling rates as well as short observation time windows. We find out that a decrease of the sampling rate from 50 kHz to 1 kHz leads to a statistically significant classification performance drop. A statistically significant decrease is also observed for the 0.1 second time windows compared to the 5-second ones. However, the effect sizes are small to medium, suggesting that in certain settings lower sampling rates and shorter observation windows can be used. The proposed optimisation approach, as well as statistically supported findings of the study, allow a more efficient design of IoT vibration analysis systems, both in terms of complexity and costs, bringing us one step closer to the IoT/Edge-based vibration analysis.
Explainable Machine Learning-driven Strategy for Automated Trading Pattern Extraction
Apr 13, 2021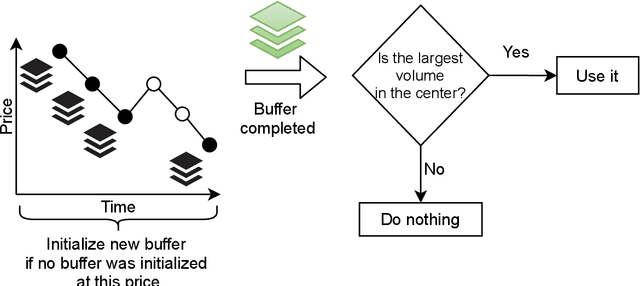

Financial markets are a source of non-stationary multidimensional time series which has been drawing attention for decades. Each financial instrument has its specific changing over time properties, making their analysis a complex task. Improvement of understanding and development of methods for financial time series analysis is essential for successful operation on financial markets. In this study we propose a volume-based data pre-processing method for making financial time series more suitable for machine learning pipelines. We use a statistical approach for assessing the performance of the method. Namely, we formally state the hypotheses, set up associated classification tasks, compute effect sizes with confidence intervals, and run statistical tests to validate the hypotheses. We additionally assess the trading performance of the proposed method on historical data and compare it to a previously published approach. Our analysis shows that the proposed volume-based method allows successful classification of the financial time series patterns, and also leads to better classification performance than a price action-based method, excelling specifically on more liquid financial instruments. Finally, we propose an approach for obtaining feature interactions directly from tree-based models on example of CatBoost estimator, as well as formally assess the relatedness of the proposed approach and SHAP feature interactions with a positive outcome.
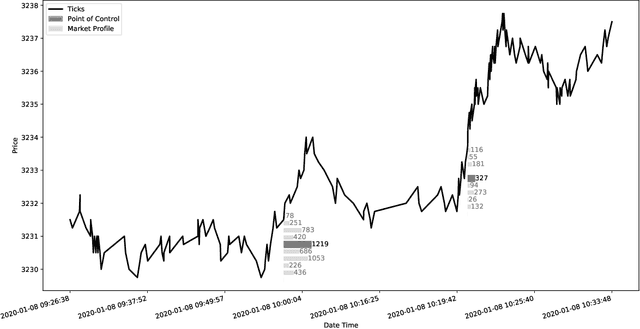
Machine Learning Classification of Price Extrema Based on Market Microstructure Features: A Case Study of S&P500 E-mini Futures
Sep 21, 2020

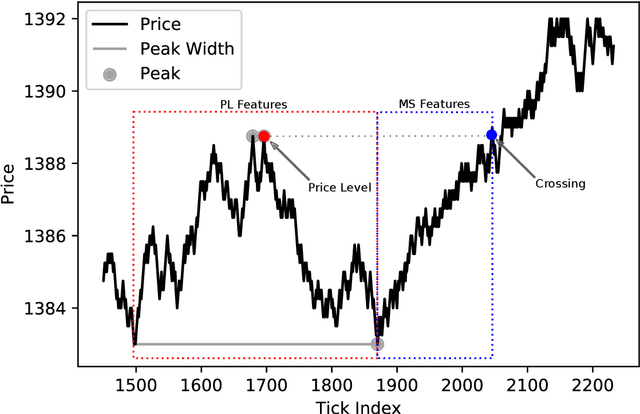
The study introduces an automated trading system for S\&P500 E-mini futures (ES) based on state-of-the-art machine learning. Concretely: we extract a set of scenarios from the tick market data to train the model and further use the predictions to model trading. We define the scenarios from the local extrema of the price action. Price extrema is a commonly traded pattern, however, to the best of our knowledge, there is no study presenting a pipeline for automated classification and profitability evaluation. Our study is filling this gap by presenting a broad evaluation of the approach showing the resulting average Sharpe ratio of 6.32. However, we do not take into account order execution queues, which of course affect the result in the live-trading setting. The obtained performance results give us confidence that this approach is worthwhile.