 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTukey g-and-h neural network regression for non-Gaussian data
Nov 12, 2024This paper addresses non-Gaussian regression with neural networks via the use of the Tukey g-and-h distribution.The Tukey g-and-h transform is a flexible parametric transform with two parameters $g$ and $h$ which, when applied to a standard normal random variable, introduces both skewness and kurtosis, resulting in a distribution commonly called the Tukey g-and-h distribution. Specific values of $g$ and $h$ produce good approximations to other families of distributions, such as the Cauchy and student-t distributions. The flexibility of the Tukey g-and-h distribution has driven its popularity in the statistical community, in applied sciences and finance. In this work we consider the training of a neural network to predict the parameters of a Tukey g-and-h distribution in a regression framework via the minimization of the corresponding negative log-likelihood, despite the latter having no closed-form expression. We demonstrate the efficiency of our procedure in simulated examples and apply our method to a real-world dataset of global crop yield for several types of crops. Finally, we show how we can carry out a goodness-of-fit analysis between the predicted distributions and the test data. A Pytorch implementation is made available on Github and as a Pypi package.
Efficient Parameter Estimation of Sampled Random Fields
Jul 15, 2019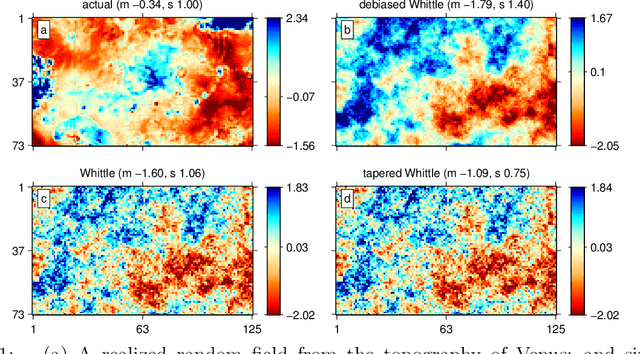


We provide a computationally and statistically efficient method for estimating the parameters of a stochastic Gaussian model observed on a spatial grid, which need not be rectangular. Standard methods are plagued by computational intractability, where designing methods that can be implemented for realistically sized problems has been an issue for a long time. This has motivated the use of the Fourier Transform and the Whittle likelihood approximation. The challenge of frequency-domain methods is to determine and account for observational boundary effects, missing data, and the shape of the observed spatial grid. In this paper we address these effects explicitly by proposing a new quasi-likelihood estimator. We prove consistency and asymptotic normality of our estimator, and show that the proposed method solves boundary issues with Whittle estimation for finite samples, yielding parameter estimates with significantly reduced bias and error. We demonstrate the effectiveness of our method for incomplete lattices, in comparison to other recent methods. Finally, we apply our method to estimate the parameters of a Mat\'ern process used to model data from Venus' topography.
The De-Biased Whittle Likelihood
Sep 12, 2018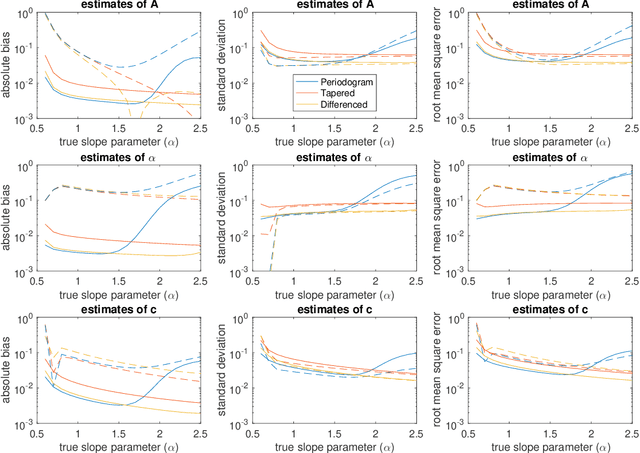
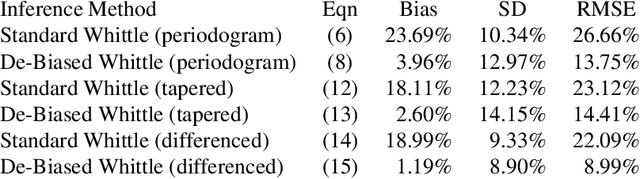
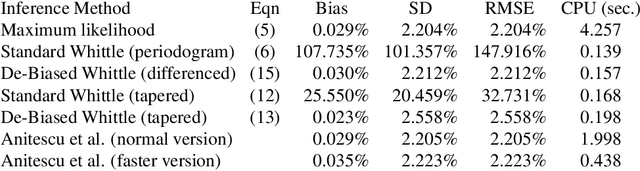
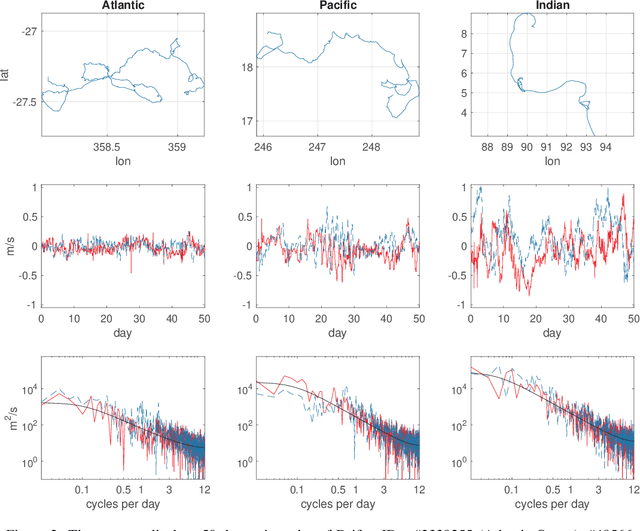
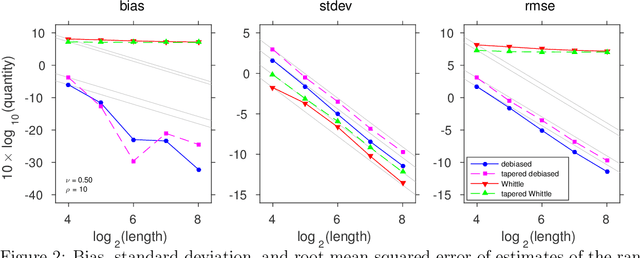
The Whittle likelihood is a widely used and computationally efficient pseudo-likelihood. However, it is known to produce biased parameter estimates for large classes of models. We propose a method for de-biasing Whittle estimates for second-order stationary stochastic processes. The de-biased Whittle likelihood can be computed in the same $\mathcal{O}(n\log n)$ operations as the standard approach. We demonstrate the superior performance of the method in simulation studies and in application to a large-scale oceanographic dataset, where in both cases the de-biased approach reduces bias by up to two orders of magnitude, achieving estimates that are close to exact maximum likelihood, at a fraction of the computational cost. We prove that the method yields estimates that are consistent at an optimal convergence rate of $n^{-1/2}$, under weaker assumptions than standard theory, where we do not require that the power spectral density is continuous in frequency. We describe how the method can be easily combined with standard methods of bias reduction, such as tapering and differencing, to further reduce bias in parameter estimates.