 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredição de Incidência de Lesão por Pressão em Pacientes de UTI usando Aprendizado de Máquina
Dec 23, 2021Pressure ulcers have high prevalence in ICU patients but are preventable if identified in initial stages. In practice, the Braden scale is used to classify high-risk patients. This paper investigates the use of machine learning in electronic health records data for this task, by using data available in MIMIC-III v1.4. Two main contributions are made: a new approach for evaluating models that considers all predictions made during a stay, and a new training method for the machine learning models. The results show a superior performance in comparison to the state of the art; moreover, all models surpass the Braden scale in every operating point in the precision-recall curve. -- -- Les\~oes por press\~ao possuem alta preval\^encia em pacientes de UTI e s\~ao preven\'iveis ao serem identificadas em est\'agios iniciais. Na pr\'atica utiliza-se a escala de Braden para classifica\c{c}\~ao de pacientes em risco. Este artigo investiga o uso de aprendizado de m\'aquina em dados de registros eletr\^onicos para este fim, a partir da base de dados MIMIC-III v1.4. S\~ao feitas duas contribui\c{c}\~oes principais: uma nova abordagem para a avalia\c{c}\~ao dos modelos e da escala de Braden levando em conta todas as predi\c{c}\~oes feitas ao longo das interna\c{c}\~oes, e um novo m\'etodo de treinamento para os modelos de aprendizado de m\'aquina. Os resultados obtidos superam o estado da arte e verifica-se que os modelos superam significativamente a escala de Braden em todos os pontos de opera\c{c}\~ao da curva de precis\~ao por sensibilidade.
Predição da Idade Cerebral a partir de Imagens de Ressonância Magnética utilizando Redes Neurais Convolucionais
Dec 23, 2021In this work, deep learning techniques for brain age prediction from magnetic resonance images are investigated, aiming to assist in the identification of biomarkers of the natural aging process. The identification of biomarkers is useful for detecting an early-stage neurodegenerative process, as well as for predicting age-related or non-age-related cognitive decline. Two techniques are implemented and compared in this work: a 3D Convolutional Neural Network applied to the volumetric image and a 2D Convolutional Neural Network applied to slices from the axial plane, with subsequent fusion of individual predictions. The best result was obtained by the 2D model, which achieved a mean absolute error of 3.83 years. -- Neste trabalho s\~ao investigadas t\'ecnicas de aprendizado profundo para a predi\c{c}\~ao da idade cerebral a partir de imagens de resson\^ancia magn\'etica, visando auxiliar na identifica\c{c}\~ao de biomarcadores do processo natural de envelhecimento. A identifica\c{c}\~ao de biomarcadores \'e \'util para a detec\c{c}\~ao de um processo neurodegenerativo em est\'agio inicial, al\'em de possibilitar prever um decl\'inio cognitivo relacionado ou n\~ao \`a idade. Duas t\'ecnicas s\~ao implementadas e comparadas neste trabalho: uma Rede Neural Convolucional 3D aplicada na imagem volum\'etrica e uma Rede Neural Convolucional 2D aplicada a fatias do plano axial, com posterior fus\~ao das predi\c{c}\~oes individuais. O melhor resultado foi obtido pelo modelo 2D, que alcan\c{c}ou um erro m\'edio absoluto de 3.83 anos.
Predicting Multiple ICD-10 Codes from Brazilian-Portuguese Clinical Notes
Jul 29, 2020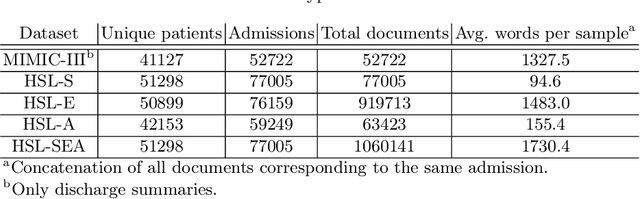



ICD coding from electronic clinical records is a manual, time-consuming and expensive process. Code assignment is, however, an important task for billing purposes and database organization. While many works have studied the problem of automated ICD coding from free text using machine learning techniques, most use records in the English language, especially from the MIMIC-III public dataset. This work presents results for a dataset with Brazilian Portuguese clinical notes. We develop and optimize a Logistic Regression model, a Convolutional Neural Network (CNN), a Gated Recurrent Unit Neural Network and a CNN with Attention (CNN-Att) for prediction of diagnosis ICD codes. We also report our results for the MIMIC-III dataset, which outperform previous work among models of the same families, as well as the state of the art. Compared to MIMIC-III, the Brazilian Portuguese dataset contains far fewer words per document, when only discharge summaries are used. We experiment concatenating additional documents available in this dataset, achieving a great boost in performance. The CNN-Att model achieves the best results on both datasets, with micro-averaged F1 score of 0.537 on MIMIC-III and 0.485 on our dataset with additional documents.