 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance and Interpretability Comparisons of Supervised Machine Learning Algorithms: An Empirical Study
May 05, 2022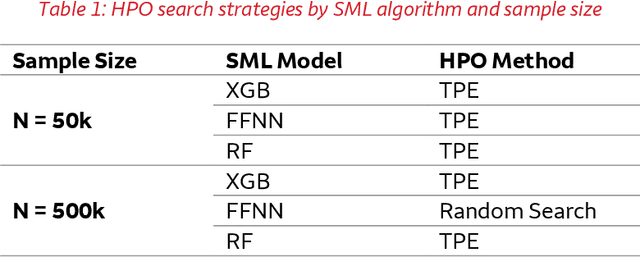
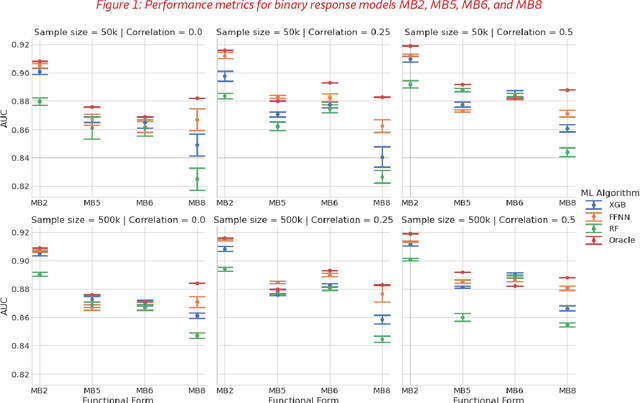
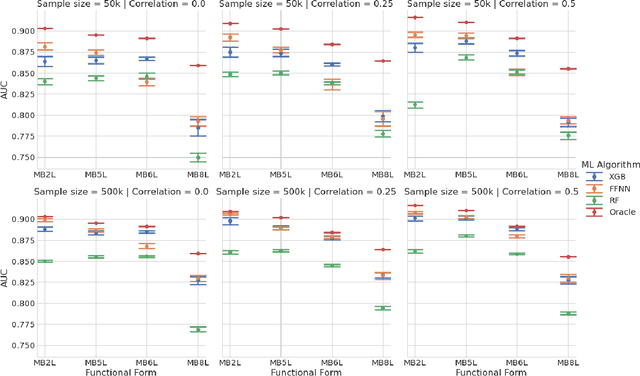
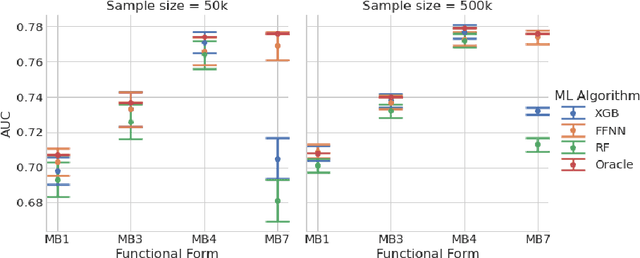
This paper compares the performances of three supervised machine learning algorithms in terms of predictive ability and model interpretation on structured or tabular data. The algorithms considered were scikit-learn implementations of extreme gradient boosting machines (XGB) and random forests (RFs), and feedforward neural networks (FFNNs) from TensorFlow. The paper is organized in a findings-based manner, with each section providing general conclusions supported by empirical results from simulation studies that cover a wide range of model complexity and correlation structures among predictors. We considered both continuous and binary responses of different sample sizes. Overall, XGB and FFNNs were competitive, with FFNNs showing better performance in smooth models and tree-based boosting algorithms performing better in non-smooth models. This conclusion held generally for predictive performance, identification of important variables, and determining correct input-output relationships as measured by partial dependence plots (PDPs). FFNNs generally had less over-fitting, as measured by the difference in performance between training and testing datasets. However, the difference with XGB was often small. RFs did not perform well in general, confirming the findings in the literature. All models exhibited different degrees of bias seen in PDPs, but the bias was especially problematic for RFs. The extent of the biases varied with correlation among predictors, response type, and data set sample size. In general, tree-based models tended to over-regularize the fitted model in the tails of predictor distributions. Finally, as to be expected, performances were better for continuous responses compared to binary data and with larger samples.